
在前两篇博文中讲解了新生代和年老代的收集器,在本篇博文中介绍一个收集范围涵盖整个堆的收集器——G1收集器。
先讲讲G1收集器的特点,他也是个多线程的收集器,能够充分利用多个CPU进行工作,收集方式也与CMS收集器类似,因此不会有太久的停顿。
虽然回收的范围是整个堆,但还是有分代回收的回收方式。在年轻代依然采用复制算法;年老代也同样采用“标记-清除-整理”算法。但是,新生代与老年代在堆内存中的布局就和以往的收集器有着很大的区别:G1将整个堆分成了一个个大小相等的独立区域,叫做region。其中依然保存着新生代和年老代的概念,如图: 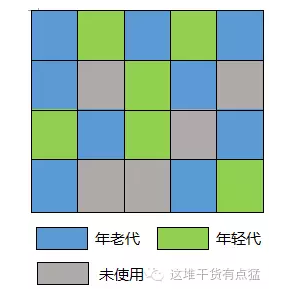
是不是和之前博文中看到的不同(这是内存空间图,不要和垃圾回收的图弄混了),以往只是简单的分区域,而这里是将整个堆分成多个大小相等的区域。
他的回收过程也分为四个部分:初始标记、并发标记、最终标记、筛选回收。
大家是不是觉得很熟悉!上面我们也说过了,和CMS收集器类似,初始标记需要STW;并发标记不需要;最终标记就是做一些小修改,需要STW;而筛选回收则有些不同,在众多的region中,每个region可回收的空间各不相同,但是回收所消耗的时间是需要控制的,不能太长,因此G1就会筛选出一些可回收空间比较大的region进行回收,这就是G1的优先回收机制。这也是保证了G1收集器能在有限的时间内能够获得最高回收效率的原因。通过-XX:MaxGCPauseMills=50毫秒设置有限的收集时间。
每个region之间的对象引用通过remembered set来维护,每个region都有一个remembered set,remembered set中包含了引用当前region中对象的指针。虚拟机正是通过这个remembered set去避免对整个堆进行扫描来确认可回收的对象。
到此,所有的收集器都已经讲完了,但是很重要的一点:每个收集器是不能随意进行组合使用的!这里我列出一个搭配使用的表格提供大家参考使用: 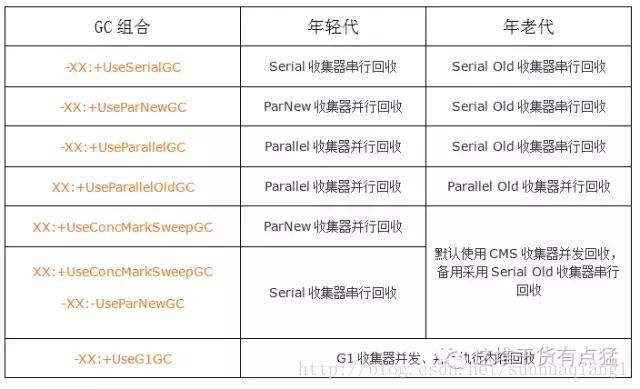
G1收集器并发、并发执行内存回收