目录
安装jdk
安装eclipse
安装PyDev插件
配置Spark
配置Hadoop
Python代码
|
配置Spark |
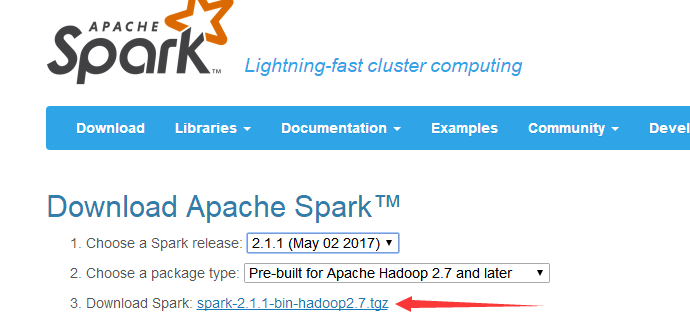
下载Spark
http://spark.apache.org/downloads.html
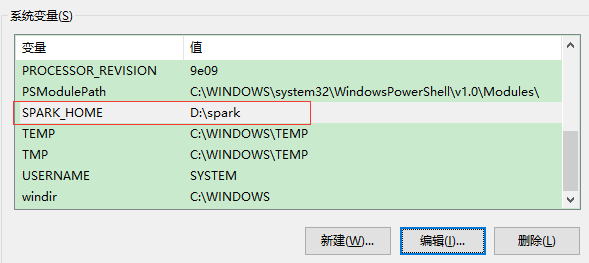
配置环境变量
变量名:SPARK_HOME 变量值:D:spark (不能有空格)
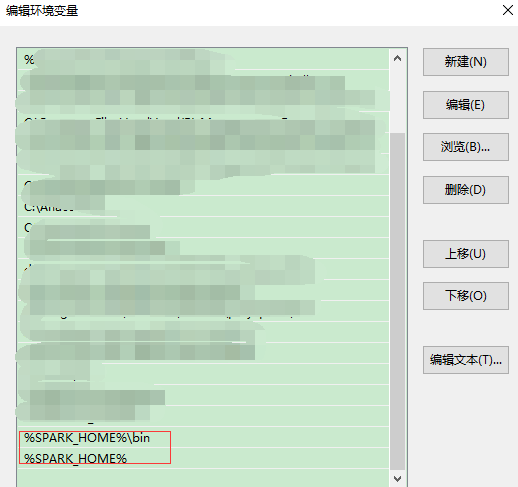
添加到Path
安装pyspark包:
将spark/python中的pyspark和pyspark.egg-info拷贝到python的Anaconda2Libsite-packages目录下
|
配置Hadoop |
无需安装完整的Hadoop,但需要hadoop.dll,winutils.exe等。根据下载的Spark版本,下载相应版本的hadoop2.7.1。
链接:https://pan.baidu.com/s/1jHRu9oE 密码:wdf9
配置环境变量
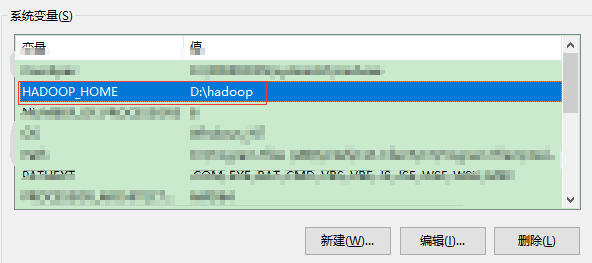
添加到Path

重启计算机!!!环境变量才生效!!!
|
Python代码 |
# -*-coding=utf-8 -*- from operator import add import random from pyspark import SparkConf, SparkContext sc = SparkContext('local') NUM_SAMPLES = 100000 def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(xrange(0, NUM_SAMPLES)) .filter(inside).count() print "Pi is roughly %f" % (4.0 * count / NUM_SAMPLES) '''运行结果: Pi is roughly 3.140160 '''