目录
概述
冒泡排序虽然解决了桶排序浪费空间的问题,但在算法的执行效率上却牺牲了很多,它的时间复杂度达到了 O(N2 )。
那有没有既不浪费空间又可以快 一点的排序算法呢?
那就是 快速排序 啦!
基本思想
基于 哨兵 的使用。
问题引入
假设我们现在对“ 6 1 2 7 9 3 4 5 10 8 ”这 10 个数进行排序。首先在这个序列中随便找一个数作为基准数(即参照数),为了方便,就让第一个数 6 作为基准数吧。接下来,需要将这个序列中所有比基准数大的数放在 6 的右边,比基准数小的数放在 6 的左边,类似下面这种排列。
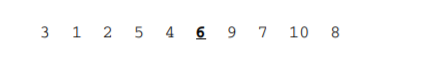
在初始状态下,数字 6 在序列的第 1 位。我们的目标是将 6 挪到序列中间的某个位置, 假设这个位置是 k。现在就需要寻找这个 k,并且以第 k 位为分界点,左边的数都小于等于 6, 右边的数都大于等于 6。
分析
方法其实很简单:分别从初始序列“ 6 1 2 7 9 3 4 5 10 8 ”两端开始“探测”。
先从右往左找一个小于 6 的数,再从左往右找一个大于 6 的数,然后交换它们。
这里可以用两个 变量 i 和 j,分别指向序列最左边和最右边。
我们为这两个变量起个好听的名字“ 哨兵 i ”和 “ 哨兵 j ”。
刚开始的时候让哨兵 i 指向序列的最左边(即 i=1),指向数字 6。让哨兵 j 指向序 列的最右边(即 j=10),指向数字 8。

首先哨兵 j 开始出动。
因为此处设置的基准数是最左边的数,所以需要让哨兵 j 先出动, 这一点非常重要(自己想一下为什么,文末解释),哨兵 j 一步一步地向左挪动(即 j--),直到找到 一个小于 6 的数停下来。
接下来哨兵 i 再一步一步向右挪动(即 i++),直到找到一个大于 6 的数停下来。最后哨兵 j 停在了数字 5 面前,哨兵 i 停在了数字 7 面前。

现在交换哨兵 i 和哨兵 j 所指向的元素的值。交换之后的序列如下。

到此,第一次交换结束。接下来哨兵 j 继续向左挪动,他发现了 4(比基准数 6 要小,满足要求)之后停了下来。
哨兵 i 也继续向右挪 动,他发现了 9(比基准数 6 要大,满足要求)之后停了下来。
此时再次进行交换。

交换之后的序列如下:
![]()
第二次交换结束,“探测”继续。哨兵 j 继续向左挪动,他发现了 3(比基准数 6 要小, 满足要求)之后又停了下来。
哨兵 i 继续向右移动,此时哨兵 i 和哨兵 j 相遇了,哨 兵 i 和哨兵 j 都走到 3 面前。
说明此时“探测”结束。我们将基准数 6 和 3 进行交换。

交换 之后的序列如下:

到此第一轮“探测”真正结束。此时以基准数 6 为分界点,6 左边的数都小于等于 6,6 右边的数都大于等于 6。
回顾一下刚才的过程,其实哨兵 j 的使命就是要找小于基准数的数, 而哨兵 i 的使命就是要找大于基准数的数,直到 i 和 j 碰头为止。
现在我们将原来的序列拆分为两个部分,即基准数左部分与基准数右部分
左部分:
3 1 2 5 4
右部分:
9 7 10 8
接下来按照相同的方法(哨兵 i 与 j )对这两个序列进行排序(递归调用)
快速排序的每一轮处理其实就是将这 一轮的基准数归位,直到所有的数都归位为止,排序就结束了。
流程图

原理
每一轮处理其实就是将这 一轮的基准数归位,直到所有的数都归位为止。
快速排序之所以比较快,是因为相比冒泡排序,每次交换是跳跃式的。
每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全 部放到基准点的右边。
这样在每次交换的时候就不会像冒泡排序一样只能在相邻的数之间进行交换,交换的距离就大得多了。
因此总的比较和交换次数就少了,速度自然就提高了。
当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和 冒泡排序是一样的,都是 O(N^2 ),它的平均时间复杂度为 O (NlogN)
代码演示
#include "stdio.h"
int arr[101], n; //定义全局变量
//构建快速排序函数
void quicksort(int left, int right){
int i, j, stan, temp;
//如果左哨兵的值大于右哨兵的值,结束函数
if (left > right){
return ;
}
stan = arr[left]; //temp用来存放基准数
i = left;
j = right;
while (i != j){
//顺序为先右后左,不可颠倒,并确保哨兵j的值始终大于哨兵a的值
while (arr[j] >= stan && i < j){ //当哨兵 j 的值大于基准数,继续向右前进
j--;
}
while (arr[i] <= stan && i < j){ //当哨兵 i 的值小于基准数,继续向左前进
i++;
}
//当哨兵 j 值小于基准数(两哨兵没相遇),哨兵 i 的值大于基准数,两数交换位置
if (j > i){
temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
//上述循环知道哨兵 i 与 j 碰头,即 i=j 时结束,此时将基准数归位(将哨兵与基准数进行换位)
//下面用到的变量 i 也可替换为变量 j ,因为此时两哨兵的值相等
arr[left] = arr[i];
arr[i] = stan;
//利用递归处理第一个基准数左部分与右部分的数据,进行新的排序
quicksort(left, i - 1); //处理左边数据,确定深的基准数并排序
quicksort(i + 1, right); //处理右边数据,确定深的基准数并排序
}
//主函数
int main()
{
int i, n;
//获取数据
scanf("%d", &n);
for (i = 1; i <= n; i++) {
scanf("%d", &arr[i]);
}
//调用快排函数
quicksort(1, n);
//输入结果
for (i = 1; i <= n; i++) {
printf("%d ", arr[i]);
}
return 0;
}输入:

输出:

哨兵 j 先动的原因
关注点在相遇的时候,从左侧先走相遇的时候可以保证左边的都是小于标准值的,但是相遇时候的值是要大于标准值(或者已经走到最右边都没有大于标准值的)。
从右侧走正好是右边都是大于标准值的,但是相遇的时候值是小于标准值(或者走到 最左边都没有小于标准值)。
所以要从基数的对面开始。
两种情况,就看你从哪开始扫描。不一定非要从右边开始!也可以从左边的,那标准值就选右边的。
参考书籍
《啊哈!算法》