原文作者:技术成就梦想
原文链接: http://ixdba.blog.51cto.com/2895551/566802
一、 集群的定义
集群是一组协同工作的服务集合,用来提供比单一服务更稳定、更高效、更具扩展性的服务平台,在外界看来,集群就是一个独立的服务实体,但实际上,在集群的内部,有两个或两个以上的服务实体在协调、配合完成一系列复杂的工作。
集群一般有两个或两个以上的服务器组建而成,每个服务器被称为一个集群节点,集群节点之间可以相互通信,通信的方式有两种,一种是基于RS232线的心 跳监控,另一种是用一块单独的网卡来跑心跳,因而,集群具有节点间服务状态监控功能,同时还必须具有服务实体的扩展功能,可以灵活的增加和剔除某个服务实 体。
在集群中,同样的服务可以由多个服务实体提供。因而,当一个节点出现故障时,集群的另一个节点可以自动接管故障节点的资源,从而保证服务持久、不间断运行。因而集群具有故障自动转移功能。
一个集群系统必须拥有共享的数据存储,因为集群对外提供的服务是一致的,任何一个集群节点运行一个应用时,应用的数据都集中存储在节点共享空间内,而每个节点的操作系统上仅运行应用的服务,同时存储应用程序文件。
综上所述,构建一个集群系统至少需要两台服务器,同时还需要有串口线、集群软件、共享存储设备(例如磁盘阵列)等。
基于Linux的集群以其极高的计算能力、可扩展性、可用性及更加优化的性价比在企业各种应用中脱颖而出。 成为目前大家都关心的Linux应用热点,熟练掌握Linux集群知识,可以用低价格做出高性能的应用。为企业、个人节省了成本。国内大型网站新浪、网易 等都采用了linux集群系统构建高性能web应用,著名搜索引擎google采用了上万台linux服务器组成了一个超大集群,这些实例都说明了集群在 linux应用中的地位和重要性。
二、 集群的特点与功能
2.1 高可用性与可扩展性
1.高可用性
对于一些实时性很强的应用系统,必须保证服务的24小时不间断运行,而由于软件、硬件、网络、人为等各种原因,单一的服务运行环境很难达到这种要求,此 时构建一个集群系统是个不错的选择,构建集群的一个最大优点是集群具有高可用性,在服务出现故障时,集群系统可以自动将服务从故障节点切换到另一个备用节 点,从而提供不间断性服务,保证了业务的持续运行。
2.可扩展性
随着业务量的加大,现有的集群服务实体不能满足需求时,可以向此集群中动态的加入一个或多个服务节点,从而满足应用的需要,增强集群的整体性能。这就是集群的可扩展性。
2.2 负载均衡与错误恢复
1.负载均衡
集群系统最大的特点是可以灵活、有效的分担系统负载,通过集群自身定义的负载分担策略,将客户端的访问分配到下面的各个服务节点,例如,可以定义轮询分 配策略,将请求平均的分配到各个服务节点,还可以定义最小负载分配策略,当一个请求进来时,集群系统判断哪个服务节点比较清闲,就将此请求分发到这个节 点。
2.错误恢复
当一个任务在一个节点上还没有完成时,由于某种原因,执行失败,此时,另一个服务节点应该能接着完成此任务,这就是集群提供的错误恢复功能,通过错误的重定向,保证了每个执行任务都能有效的完成。
2.3心跳检测与漂移IP
1.心跳监测
为了能实现负载均衡、提供高可用服务和执行错误恢复,集群系统提供了心跳监测技术,心跳监测是通过心跳线实现的,可以做心跳线的设备有RS 232串口线,也可以用独立的一块网卡来跑心跳,还可以是共享磁盘阵列等,心跳线的数量应该为集群节点数减1,需要注意的是,如果通过网卡来做心跳的话, 每个节点需要两块网卡,其中,一块作为私有网络直接连接到对方机器相应的网卡,用来监测对方心跳。另外一块连接到公共网络对外提供服务,同时心跳网卡和服 务网卡的IP地址尽量不要在一个网段内。心跳监控的效率直接影响故障切换时间的长短,集群系统正是通过心跳技术保持着节点间的内部有效通信。
2.漂移IP地址
在集群系统中,除了每个服务节点自身的真实IP地址外,还存在一个漂移IP地址,为什么说是漂移IP呢,因为这个IP地址并不固定,例如在两个节点的双 机热备中,正常状态下,这个漂移IP位于主节点上,当主节点出现故障后,漂移IP地址自动切换到备用节点,因此,为了保证服务的不间断性,在集群系统中, 对外提供的服务IP一定要是这个漂移IP地址,虽然节点本身的IP也能对外提供服务,但是当此节点失效后,服务切换到了另一个节点,但是服务IP仍然是故 障节点的IP地址,此时,服务就随之中断。
三、 集群的分类
3.1 高可用集群
1.高可用的概念
高可用集群的英文全称是High Availability Cluster,简称HA Cluster, 高可用的含义是最大限度的可以使用,从集群的名字上可以看出,此类集群实现的功能是保障用户的应用程序持久、不间断的提供服务。
当应用程序出现故障,或者系统硬件、网络出现故障时,应用可以自动、快速从一个节点切换到另一个节点,从而保证应用持续、不间断的对外提供服务,这就是高可用集群实现的功能,
2.常见的HA Cluster
我们常说的双机热备、双机互备、多机互备等都属于高可用集群的范畴,这类集群一般都有两个或两个以上节点组成。典型的双机热备结构如图1所示
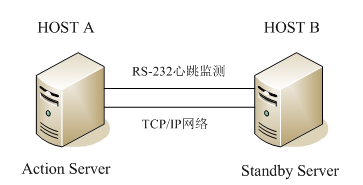
图1 双机热备结构
双机热备是最简单的应用模式,即经常说的active/standby方式,它使用两台服务器,一台作为主服务器(action),运行应用程序对 外提供服务,另一台作为备机(standby),安装和主服务器一样的应用程序,但是并不启动服务,处于待机状态。主机和备机之间通过心跳技术相互监控, 监控的资源可以是网络、操作系统、也可以是服务,用户可以根据自己的需要,选择需要监控的资源,当备机监控到主机的某个资源出现故障时,根据预先设定好的 策略,首先将IP切换过来,然后将应用程序服务也接管过来,接着就由备机对外提供服务,由于切换过程时间非常端,用户根本感觉不到程序出了问题,而且还进 行了切换,从而保障了应用程序持久、不间断的服务。
双机互备是在双机热备的基础上,两个相互独立的应用在两个机器上同时运行,互为主备,即两台服务器既是主机也是备机,当任何一个应用出现故障,另一台服务 器都能在短时间内将故障机器的应用接管过来,从而保障了服务的持续、无间断运行。双机互备的好处是节省了设备资源,两个应用的双机热备至少需要四台服务 器,而双机互备仅需两台服务器即可完成高可用集群功能,但是双机互备也有自身的缺点:在某个节点故障切换后,另一个节点上就同时运行了两个应用的服务,有 可能出现负载过大的情况。
多机互备是双机热备的技术升级,通过多台机器组成一个集群,可以在多台机器之间设置灵活的接管策略,例如,某个集群环境有8台服务器组成,3台运行web 应用,3台运行mail应用,因而,可以将剩余的一台作为3台web服务器的备机,另一台作为3台mail服务器的备机,通过这样的部署,合理充分的利用 了服务器资源,同时也保证了系统的高可用性。
需要注意的是:高可用集群不能保证应用程序数据的安全性,它仅仅解决的是对外提供持久不间断的服务,把由于软件、硬件、网络、人为因素造成的故障而对应用造成的影响降低到最底程度。
3.高可用集群软件
高可用集群一般是通过高可用软件来实现的,在linux下常用的高可用软件有:开源heartbea HA、Redhat提供的RHCS、商业软件ROSE、keepalived等。在下面的章节中我们会详细介绍heartbea HA的配置和使用。
3.2 负载均衡集群
负载均衡系统的英文全称为Load Balance Cluster,简称LB Cluster,负载均衡集群也是有两台或者两台以上的服务器组成,分为前端负载调度和后端节点服务两个部分,负载调度部分负责把客户端的请求按照不同的 策略分配给后端服务节点,而后端节点是真正提供应用程序服务的部分。
与HA Cluster不同的是,在负载均衡集群中,所有的后端节点都处于活动状态,它们都对外提供服务,分摊系统的工作负载。
负载均衡集群可以把一个高负荷的应用分散到多个节点来共同完成,适用于业务繁忙、大负荷访问的应用系统,但是它也有不足的地方:当一个节点出现故障时,前 端调度系统并不知道此节点已经不能提供服务,仍然会把客户端的请求调度到故障节点上来,这样访问就会失败,为了解决这个问题,负载调度系统一般都引入了节 点监控系统。
节点监控系统位于前端负载调度机上,负责监控下面的服务节点,当某个节点出现故障后,节点监控系统会自动将故障节点从集群中剔除,当此节点恢复正常后,节点监控系统又会自动将其加入集群中,而这一切,对用户来说是完全透明的。
图2显示了负载均衡集群的基本结构:
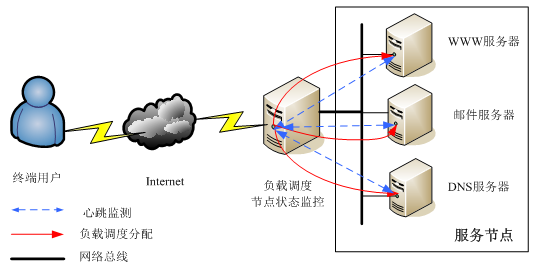
图2 负载均衡集群基本构架
负载均衡集群可以通过软件方式实现,也可以由硬件设备来完成,linux下典型的负载均衡软件有:开源LVS集群、Oracle的RAC集群等,硬件负载均衡器有F5 Networks等。关于LVS集群,在下面的章节我们会进行详细讲解。
3.3 科学计算集群
高性能计算(High Perfermance Computing)集群,简称HPC集群。这类集群致力于提供单个计算机所不能提供的强大的计算能力,包括数值计算和数据处理,并且倾向于追求综合性 能。HPC与超级计算类似,但是又有不同,计算速度是超级计算追求的第一目标。最快的速度,最大的存储,最庞大的体积,最昂贵的价格代表了超级计算的特 点,随着人们对计算速度需求的提高,超级计算也应用到了各个领域,对超级计算追求单一计算速度指标转变为追求高性能的综合指标。即高性能计算。
HPC应用领域非常广泛,典型应用有:生命科学研究、基因测试比对、数据挖掘应用、石油和天然气勘探、图像呈现等。
