shuffle概览
shuffle过程概览
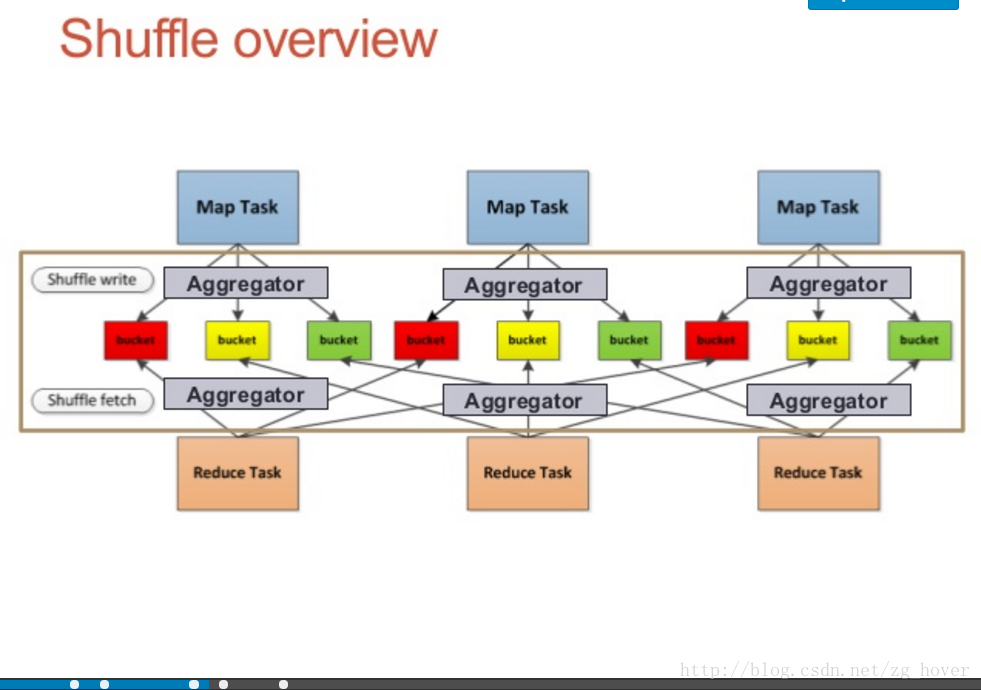
shuffle数据流概览
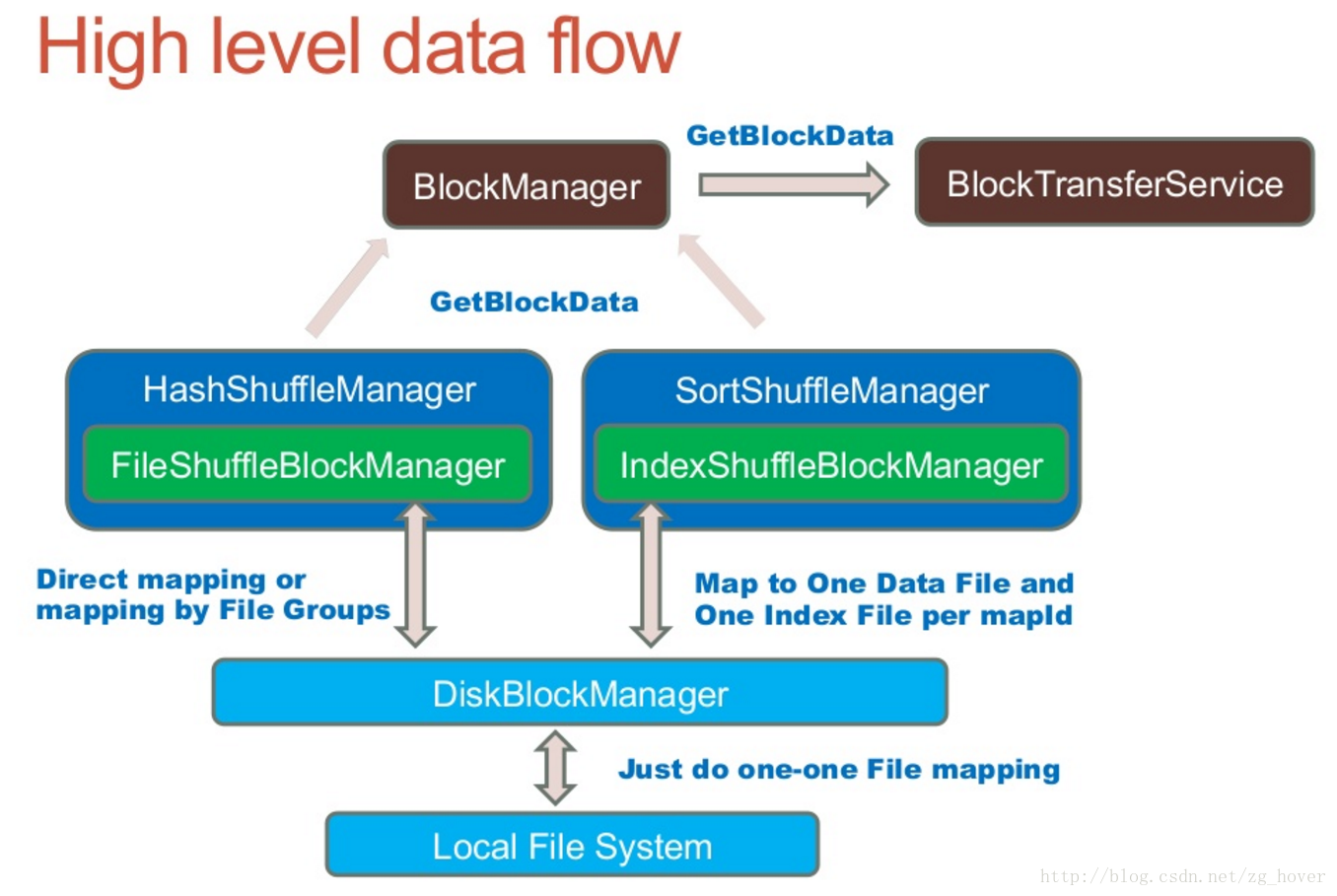
shuffle数据流
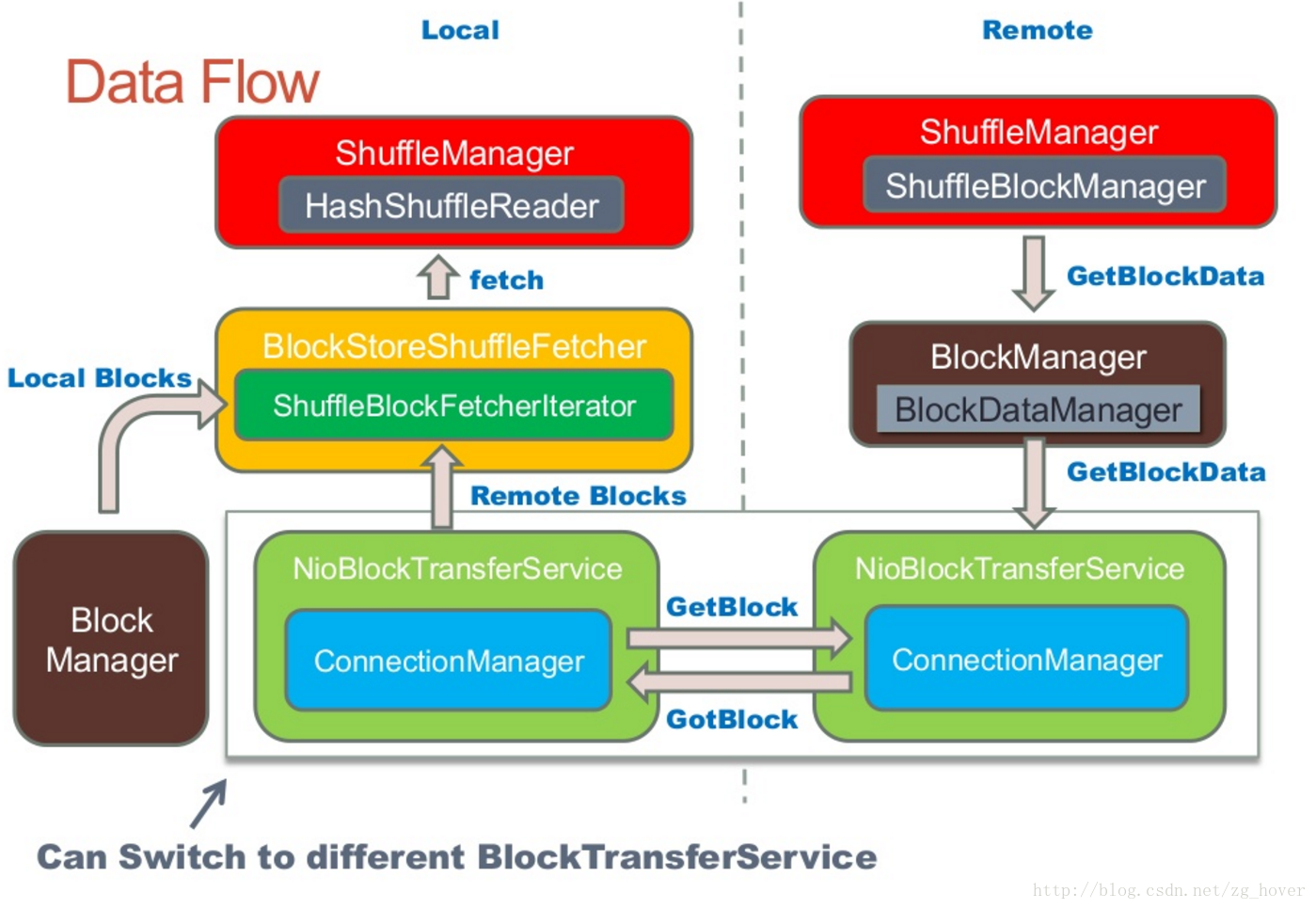
shuffle工作流程
在运行job时,spark是一个stage一个stage执行的。先把任务分成stage,在任务提交阶段会把任务形成taskset,在执行任务。
spark的DAGScheduler根据RDD的ShuffleDependency来构建Stages:
- 例如:ShuffleRDD/CoGroupedRDD有一个ShuffleDependency。
- 很多操作通过钩子函数来创建ShuffleRDD
每个ShuffleDependency会map到spark的job的一个stage,然后会导致一个shuffle过程。
为什么shuffle过程代价很大
这是由于shuffle过程可能需要完成以下过程:
- 重新进行数据分区
- 数据传输
- 数据压缩
- 磁盘I/O
shuffle的体系结构
ShuffleManager接口
shuffleManager是spark的shuffle系统的可插拔接口。ShuffleManager将会在driver和每个executor上的SparkEnv中进行创建。可以通过参数spark.shuffle.manager进行设置。
driver通过ShuffleManager来注册shuffle,并且executor通过它来读取和写入数据。
ShuffleWriter
控制shuffle数据输出逻辑。
ShuffleReader
获取shuffle过程中用于ShuffleRDD的数据。
ShuffleBlockManager
管理抽象的bucket和计算数据块之间的mapping过程。
基于sort的shuffle
sort-based的shuffle,会把输入的记录根据目标分区id(partition ids)进行排序。然后写入单个的map输出文件中。为了读取map的输出部分,Reducers获取此文件的连续区域 。当map输出的数据太大而内存无法存放时,输出的排序子集可以保存到磁盘,这些磁盘文件被合并后,生成最终的输出文件。
sort shuffle有两个不同的输出路径来产生map的输出文件:
- 序列化排序(Serialized sorting)
在使用序列化排序时,需要满足以下3个条件:
- shuffle不指定聚合(aggregation)或输出排序方法。
- shuffle的序列化程序支持序列化值的重定位(KryoSerializer和Spark SQL的自定义序列化程序目前支持此操作)。
- shuffle产生小于16777216个输出分区。
- 反序列化排序(Deserialized sorting)
用来处理所有其他情况。
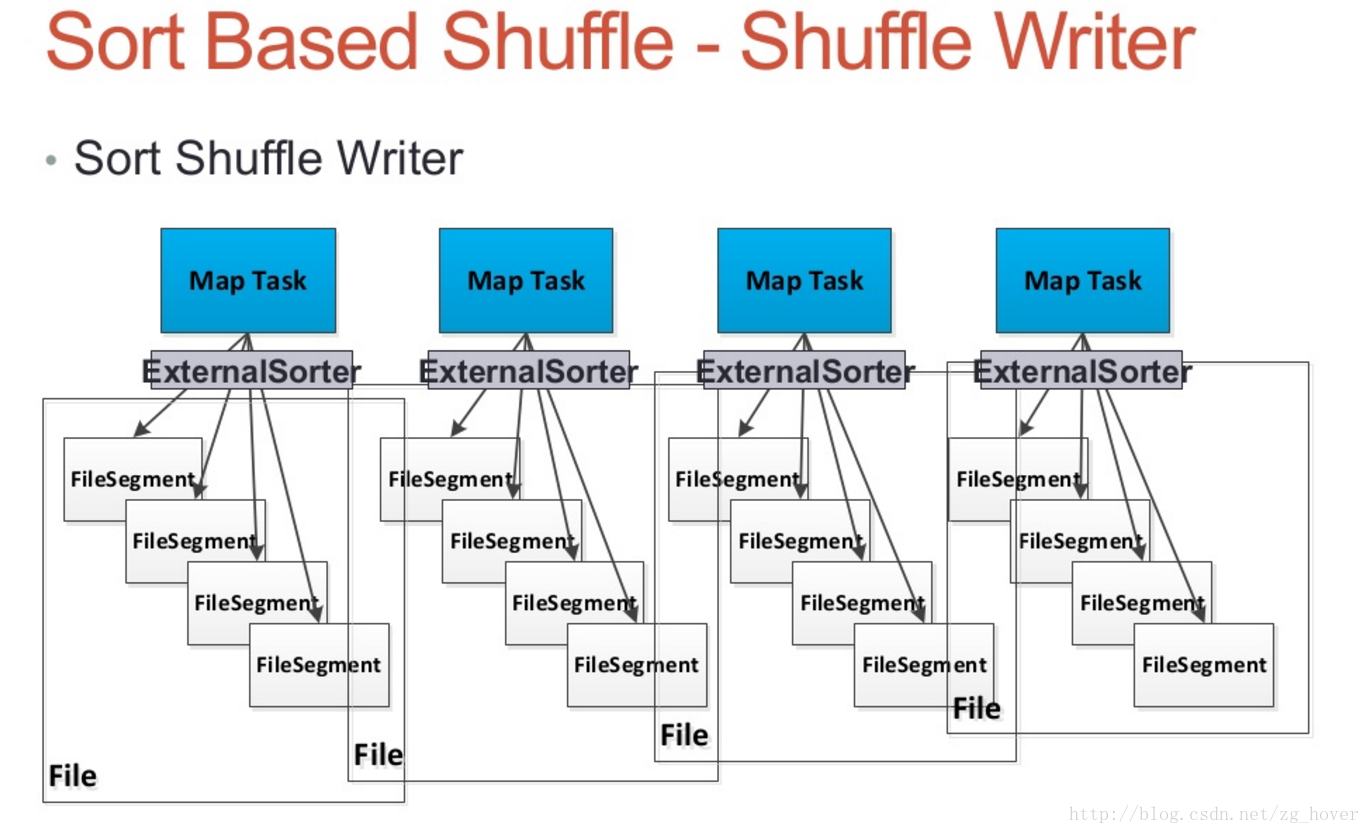
Sort Shuffle Manager
Sort Shuffle Writer
- 每个map任务都会产生一个shuffle数据文件,和一个Index文件
- 通过外部排序类ExternalSorter对数据进行排序
- 若map-side需要进行合并(combine)操作,数据将会按key和分区进行排序,若没有合并操作数据只会根据分区进行排序。