由于官网和其他教程里面都是以Linux为平台演示tensorboard使用的,而在Windows上与Linux上会有一些差别,因此我将学习的过程记录下来与大家分享(基于tensorflow1.2.1版本)。
最简单的tensorboard应用
tensorboard是为了将复杂的计算图可视化的工具,使用tensorboard包括两个步骤,
- 在python程序中将想要可视化的结果,包括中间结果,例如准确率变化等,以及计算图模型使用tf.Summary.FileWriter()写入到文件系统。
- 运行tensorboard –path-to-log命令读取之前输出的log,并显示在web服务器上,这时可通过浏览器访问。、
示例:
第一步:输出日志文件
import tensorflow as tf in1 = tf.constant([1., 2.], name='in1') in2 = tf.Variable(tf.random_normal([2]), name='in2') out = tf.add(in1, in2, name='add') #注意Windows环境下的的路径为了方便可以使用r'',或把都替换成/或\ writer = tf.summary.FileWriter(r'E: f', tf.get_default_graph()) writer.close()
这样就把上面的out=in1+in2的计算图输出到了E: f文件夹下了
第二步:打开tensorboard
tensorboard --logdir=E: f
打开浏览器访问localhost:6006(端口可以使用port参数修改)即可看到刚才输出的计算图
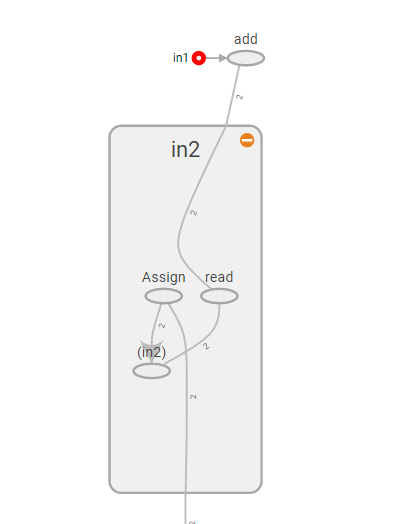
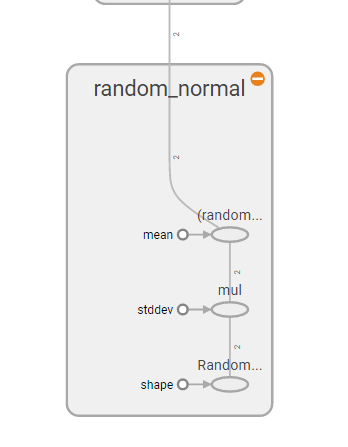
其中,in1为constant,in2为Variable(通过random_normal初始化),然后add的输入为in1和in2。
这是一个简单的应用,更复杂主要在于输出的log不同。
更全面的计算图可视化
命名空间
在有些时候计算图中有一些节点,例如常量变量的初始化操作使我们不太关心的,因此我们需要使用tensorflow中的命名空间来整理需要可视化的节点。
在tensorboard的默认视图中同一命名空间的所有节点会缩略成一个节点,只有顶层命名空间中的节点才会显示出来。关于命名空间可参考这里
因此,我们只需要在上面的代码中引入两个命名空间即可。
import tensorflow as tf #命名空间in1 with tf.name_scope('in1'): in1 = tf.constant([1., 2.], name='in1') #命名空间in2 with tf.name_scope('in2'): in2 = tf.Variable(tf.random_normal([2]), name='in2') out = tf.add_n([in1, in2], name='add') writer = tf.summary.FileWriter(r'E: f', tf.get_default_graph()) writer.close()
节点信息
在上面的例子中我们只能知道节点的一些基本信息,而在实际的应用中我们可能会想要知道某些运算(节点)消耗的时间和空间,因此在本节介绍如何通过tensorboard展示这些信息,这里只需要写入相应的信息即可。
# 配置运行时需要记录的信息。 run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE) # 运行时记录运行信息的proto。 run_metadata = tf.RunMetadata() _, loss_value, step = sess.run( [train_op, loss, global_step], feed_dict={x: xs, y_: ys}, options=run_options, run_metadata=run_metadata) #将运行时的信息写入文件 train_writer=tf.summary.FileWriter(r"E: f") train_writer.add_run_metadata(run_metadata, 'step%03d'%i)
这样,再打开tensorboard就可以在node信息里面看到时间和空间消耗了。
监控指标可视化
在机器学习过程中监控训练集和验证集上的准确率变化对于整个模型很有帮助,本节将会介绍如何把这些数据可视化。
直方图(histogram)
tf.summary.histogram()会记录tensor中元素的取值分布,返回值为Summary protocol buffer,将这个Summary写入log之后,可以在tensorboard中的HISTOGRAM栏中看到结果。
注意:tf.summary.histogram()不会立即执行,而是会在sess.run之后才会真正执行。但是有时会有太多的数据生成语句,tensorflow提供了tf.summary.merge_all()用来将所有的summary()函数执行一次。
图像
tf.summary.image()