Redux 和 Mobx 都是当下比较火热的数据流模型,一个背靠函数式,似乎成为了开源界标配,一个基于面向对象,低调的前行。
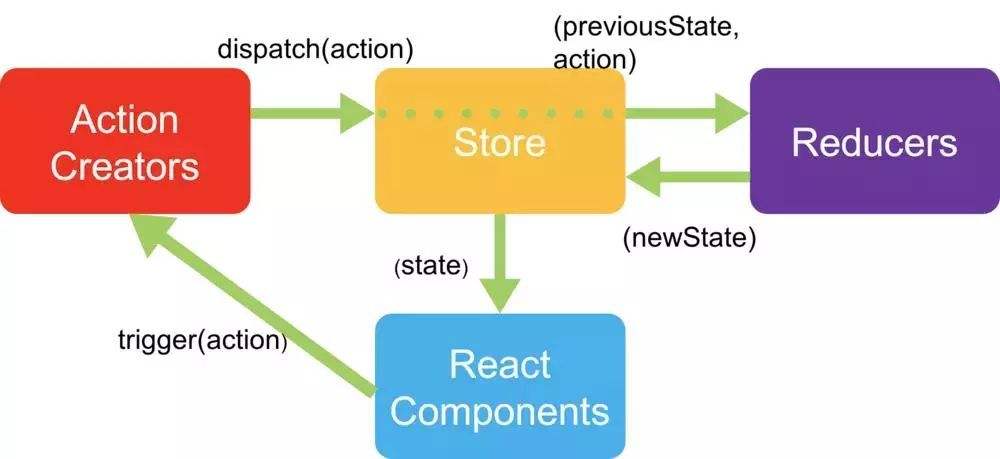
以下内容会严格遵循下面三个观点:
目的一致
都是状态管理库,用来管理应用的内部状态
受众大体一致
一般都会被用到react中,虽然说这并不是必须的,你当然也可以用到vue或者angular里,但是,大多数情况下,都不会这么做
可相互替代
在项目之初,你可以选择二者之一来满足你的项目需求,但是到某一天你突然觉得另一个更和你气味相投,你完全可以花点时间迁移过去,你会发现,它似乎也能满足你的那些需求
学习难度对比:
mobX的学习中,你可以听信关于30分钟快速入门的神话,因为它真的很简单,并且在这三十分钟过去之后,你唯一需要花的时间就是偶尔翻翻文档就可以自如的使用它了。
redux的入门学习也没那么难,即使有些概念显得比较抽象,你最多需要多花上半个小时就可以掌握它们了,但是当你真的去使用的时候,你会发现这一切原来并非想象的那么简单,你不得不花更多的时间来学习更多:
当你需要异步的时候,你不得不考虑redux-thunk,你怎么可能不需要异步想用Promise,没问题,先看看redux-promise-middleware怎么样想搞个日志之类的东西,redux-logger已经准备好了。
工作量对比(以下代码直接在nodejs环境下测试):
一般来讲,这里应该用一个couter之类的示例来做
const { createStore } = require('redux') const ADD = 'ADD' const initState = {count: 0} // reducer function counter(state = initState, action) { switch(action.type) { case ADD: return {...state, count: state.count + action.payload.count} default: return state } } // actions const AddOne = () => ({type: ADD, payload: {count:1}}) // store const store = createStore(counter) store.subscribe(() => console.log(store.getState())) setInterval(() => store.dispatch(AddOne()), 1000)
一个mobx的counter大概得长成这样吧
const { observable, autorun } = require('mobx') const appState = observable({ counter: 0, add(value){this.counter += value} }) autorun(() => console.log(appState.counter)) setInterval(() => appState.add(1), 1000)
我的天哪,多出了那么多行代码,我还要不要下班了
内存开销对比:
大小只是浮于表面的东西,对于应用更友好的东西,才是核心的要点
在写redux的action的时候,总是需要用到扩展语句或者Object.assign()的方式来得到一个新的state,这一点对于JavaScript而言是对象的浅拷贝,它对内存的开销肯定是大于mobX中那样直接操作对象属性的方式大得多。
这一点比较6,算是一个可被重视的问题
以上内容黑得主角很明显是属于redux的,那,万一我们换个视角看看呢
状态管理的集中性:
mobX中竟然有这样的写法:
const {observable} = require('mobx')
const appState = observable({ counter: 0 })
appState.counter += 1
直接修改状态?这和react的理论完全相悖啊,还怎么和react搭配使用啊,我的状态万一被同事给悄悄改了可是会引发一场战争的啊,还是开启严格模式吧。
你说redux做的怎么样?试试不通过action更新一下state,当然不能成功啊。
样板代码的必要性:
关于样板代码,就要追溯到redux的基本设计选择了,redux三大原则:
单一数据源
State 是只读的
使用纯函数来执行修改
所以可以说是这些样本代码保证了state的状态的可管理性,毕竟所有的东西都是泾渭分明的,让出错的可能性和找问题的成本降到了最低。
以上,使用mobX入门简单,构建应用迅速,但是当项目足够大的时候,还是使用redux,如果的确对mobX爱不释手,那还是开启严格模式,再加上一套状态管理的规范吧。
函数式 vs 面向对象
首先任何避开业务场景的技术选型都是耍流氓,我先耍一下流氓,首先函数式的优势,比如:
无副作用,可时间回溯,适合并发。
数据流变换处理很拿手,比如 rxjs。
对于复杂数据逻辑、科学计算维的开发和维护效率更高。
当然,连原子都是由带正电的原子核,与带负电的电子组成的,几乎任何事务都没有绝对的好坏,面向对象也存在很多优势,比如:
javascript 的鸭子类型,表明它基于对象,不适合完全函数式表达。
数学思维和数据处理适合用函数式,技术是为业务服务的,而业务模型适合用面向对象。
业务开发和做研究不同,逻辑严谨的函数式相当完美,但别指望每个程序员都愿意消耗大量脑细胞解决日常业务问题。
Redux vs Mobx
那么具体到这两种模型,又有一些特定的优缺点呈现出来。
Redux:
数据流流动很自然,因为任何 dispatch 都会导致广播,需要依据对象引用是否变化来控制更新粒度。
如果充分利用时间回溯的特征,可以增强业务的可预测性与错误定位能力。
时间回溯代价很高,因为每次都要更新引用,除非增加代码复杂度,或使用 immutable。
时间回溯的另一个代价是 action 与 reducer 完全脱节,数据流过程需要自行脑补。原因是可回溯必然不能保证引用关系。
引入中间件,其实主要为了解决异步带来的副作用,业务逻辑或多或少参杂着 magic。
但是灵活利用中间件,可以通过约定完成许多复杂的工作。
对 typescript 支持困难。
Mobx:
数据流流动不自然,只有用到的数据才会引发绑定,局部精确更新,但免去了粒度控制烦恼。
没有时间回溯能力,因为数据只有一份引用。
自始至终一份引用,不需要 immutable,也没有复制对象的额外开销。
没有这样的烦恼,数据流动由函数调用一气呵成,便于调试。
业务开发不是脑力活,而是体力活,少一些 magic,多一些效率。
由于没有 magic,所以没有中间件机制,没法通过 magic 加快工作效率(这里 magic 是指 action 分发到 reducer 的过程)。
完美支持 typescript。
到底如何选择
一般前端数据流不太复杂的情况,使用 Mobx,因为更加清晰,也便于维护;如果大型项目建议使用redux