目录
读取和写入CSV文件
读取文件中学生成绩高于60的数据,并写入新的文件中
import csv
# 写入文件
with open("test.csv", 'w', encoding='utf-8') as wf:
writes = csv.writer(wf)
writes.writerow(["id", "name", "age", "score"])
writes.writerow([1, "李四", 14, 45.4])
writes.writerow([2, "张三", 18, 61])
writes.writerow([3, "王二", 35, 30.1])
writes.writerow([4, "麻子", 44, 88])
# 读取文件中学生成绩高于60的数据,并写入新的文件中
with open("test.csv", 'r', encoding='utf-8') as rf:
# 获取读取的句柄
reader = csv.reader(rf)
# 通过next()获取头部
headers = next(reader)
# 写入新的文件中
with open("newFile.csv", 'w', encoding='utf-8') as wf:
# 获取写入句柄
writes = csv.writer(wf)
# 写入刚才获取的头部
writes.writerow(headers)
# 读取每一行数据
for student in reader:
# 获取成绩的列
score = student[-1]
# 判断成绩的列存在且大于等于60
if score and float(score) >= 60:
# 写入新文件中
writes.writerow(student)
在列表,字典,集合中根据条件筛选数据
列表
from random import randint
l = [randint(-10, 10) for i in range(10)]
# 方法1-列表解析
m = [x for x in l if x >= 0] # [8, 7, 10, 1, 4]
# 方法2-filter()方法
n = filter(lambda x: x >= 0, l)
print(list(n))
字典
# 字典
d = {"student%d" % d: randint(50, 100) for d in range(21)}
# 方法1-字典解析
dc = {k: v for k, v in d.items() if v > 90}
print(dc)
# 方法2-filter()方法
dn = filter(lambda x: x[1] > 90, d.items())
print(dict(dn))
集合
# 集合
s = {randint(-10, 10) for x in range(10)}
# 方法1-集合解析
sm = {x for x in s if x >= 0}
print(sm)
# 方法2-使用filter()方法
sd = filter(lambda x: x >= 0, sm)
print(set(sd))
为元组中的每个元素命名
方法1:使用一系列的数值常量
# 为元组中每一个元素命名
# 方法1:使用一系列的数值常量
NAME, AGE, SEXE, EMAIL = range(4)
stu = ("李四", 16, "man", "pyj.moon@gmail.com")
def get_func(student):
# 通过常量命名
if student[AGE] < 18:
print(student[0] + "的年龄小于18")
if student[SEXE] == "male":
print(student[0] + "的性别为:male")
get_func(student=stu)
方法2:使用枚举类
# 导入int型的枚举类
from enum import IntEnum
class StuentEnum(IntEnum):
NAME = 0
AGE = 1
SEXE = 2
EMAIL = 3
print(stu[StuentEnum.NAME]) # 李四
print(isinstance(StuentEnum.NAME, int)) # True StuentEnum.NAME是int的实例
方法3:使用标准库中collections.namedtuple代替内置tuple
# 方法3:使用标准库中collections.namedtuple代替内置tuple
from collections import namedtuple
# 第一个参数,命名元组的名字;第二个参数,每个元素的名字
s1 = namedtuple("StudentTest", ["name", "age", "sex", "email"])
# 使用命名元组创建一个元组
s2 = s1("李四", 16, "man", "pyj.moon@gmail.com")
print(s2)
# 使用命名元组的方式,访问字段
print(s2.name) # 李四
根据字典值的大小进行排序
方法1:先将字典中的项转化为元组(列表解析),然后使用sorted()方法排序
# 创建字典
score = {k: randint(60, 100) for k in "abcdefg"}
# 方法1:先将字典中的项转化为元组(列表解析),然后使用sorted()方法排序
# 先转化成元组的列表
l = [(v, k) for k, v in score.items()]
# 在对他进行降序排序
m = sorted(l, reverse=True)
print(m) # [(98, 'g'), (92, 'a'), (88, 'c'), (83, 'e'), (77, 'd'), (74, 'f'), (69, 'b')]
方法2:先将字典中的项转化为元组(zip),然后使用sorted()方法排序
# 方法2:# 先将字典中的项转化为元组(zip),然后使用sorted()方法排序
# 创建字典
score = {k: randint(60, 100) for k in "abcdefg"}
ls = list(zip(score.values(), score.keys()))
print(ls)
# 使用sorted()进行排序
lm = sorted(ls, reverse=True)
print(lm)
方法3:传递sorted函数的key参数
# # 方法3:传递sorted函数的key参数
# 创建字典
score = {k: randint(60, 100) for k in "abcdefg"}
sl = sorted(score.items(), key=lambda item: item[1], reverse=True)
print(sl)
加入排名
# 加入排排名信息
# enumerate()函数,加入排名
p = list(enumerate(sl, 1))# [(1, ('c', 86)), (2, ('e', 79)), (3, ('f', 77)), (4, ('d', 75)), (5, ('a', 66)), (6, ('b', 62)), (7, ('g', 60))]
# 在原字典上更新
for i, (k, v) in enumerate(sl, 1):
score[k] = (i, v)
print(score)
# 生成一个新字典
ll = {k: (i, v) for i, (k, v) in enumerate(sl, 1)}
print(ll)
随机序列中元素出现频次最多的3个和其出现的频次
使用collections函数的Counter方法
from random import randint
# 在0-20之间生成30个元素
lr = [randint(0, 20) for i in range(30)]
print(lr)
# 使用collections的Counter方法
from collections import Counter
c = Counter(lr)
print(c.most_common(3)) # [(12, 4), (2, 4), (5, 4)]
统计英文文章中出现最多的10个单词
# 计算文本中单词出先的次数
txt = open("englishTitle.txt", encoding='utf-8').read()
# print(txt)
import re
# W:匹配非字母数字及下划线,使用其分割文件
ls = re.split('W', txt)
c1 = Counter(ls)
print(c1.most_common(10))
获取多个字典中的公共键
from random import randint, sample
from functools import reduce
# 创建随机字典
data1 = {k: randint(1, 3) for k in sample("abcdefg", randint(3, 6))}
data2 = {k: randint(1, 3) for k in sample("abcdefg", randint(3, 6))}
data3 = {k: randint(1, 3) for k in sample("abcdefg", randint(3, 6))}
# 字典放到一个列表中
dl = [data1, data2, data3]
# 通过reduce获取共关键
n = reduce(lambda a, b: a & b, map(dict.keys, dl))
print(n)
拆分多个分隔符的字符串
# 拆分多个分割符的字符串
import re
str = "abc,ge;fe,gee dk;test"
# 使用正则匹配分隔符
sp = re.split('[,; ]+', str) # ['abc', 'ge', 'fe', 'gee', 'dk', 'test']
print(sp)
小字符串拼接成大字符串
# 小字符串拼接大字符串
# 方法1:使用+拼接字符串
str1 = ['李四', "zhangsan", 'good', '99', '南京南南站']
from functools import reduce
newStr1 = reduce(str.__add__, str1)
print(newStr1)
# 方法2:使用join方法(推荐使用,空间和速度都比拼接的方式快)
newStr2 = ''.join(str1)
print(newStr2)
对字符串进行左对齐、右对齐、居中
# 对字符串进行左、右、居中对齐
str1 = "abcd"
# 左对齐
print(str1.ljust(10)) # abcd
# 右对齐
print(str1.rjust(10)) # abcd
# 居中
print(str1.center(10)) # abcd
# 指定字符填充
print(str1.center(10, '*')) # ***abcd***
# 使用format()方法
# 左对齐
format(str1, '<10')
# 右对齐
format(str1, '>10')
# 居中
print(format(str1, '^10'))
# 指定字符填充
print(format(str1, '*^10')) # ***abcd***
# 使字典按照“:”符号对齐
dictTest = {"李四的耳朵": "利斯的", "性别": 1, "本人的地址省份": "日本市"}
# 获取元素key最大长度
weith = max(map(len, dictTest))
print(weith)
for k, v in dictTest.items():
print(k.ljust(weith), ':', v)
去掉不需要的字符
# 使用strip,lstrip,rstrip方法去掉字符串两端的字符
# 去掉两端的空格
str2 = " abcd "
print(str2.strip())
# 去掉两端指定的字符
str3 = "=== abcd =="
print(str3.strip('='))
# 使用replace和正则表达sub的方法
str4 = " abcd abcd "
print(str4.replace(' ', '')) # abcdabcd
# 使用正则表达式sub
import re
str5 = " abcd abcd "
print(re.sub("s", '', str5))# abcdabcd
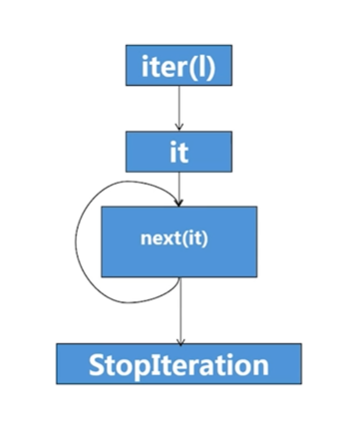
可迭代对象和迭代器
- 可迭代对象通过iter(可迭代对象)方法,生成迭代器
- 迭代器必是可迭代对象
- iter(迭代器)是它自身
- 迭代器是一次性消费的
for循环原理
实例:抓取城市气温
from collections.abc import Iterator, Iterable
import requests
class WeatherIterable(Iterable):
# 可迭代对象
def __init__(self, cities):
self.cities = cities
# __iter_ 改造后的
def __iter__(self):
for city in self.cities:
yield self.get_weather(city)
# 获取城市, 最高气温, 最低气温
def get_weather(self, city):
url = 'http://wthrcdn.etouch.cn/weather_mini?city=' + city
r = requests.get(url)
data = r.json()['data']['forecast'][0]
return city, data['high'], data['low']
# 循环遍历
def show(w):
for x in w:
print(x)
# 用户实例化调用
w = WeatherIterable(['北京', '上海', '广州'] * 5)
show(w)
print('-' * 30)
show(w)
通过可迭代对象生成素数
# 通过可迭代对象yield获取素数
# 可迭代对象
from collections.abc import Iterable
class PrimeNumbers(Iterable):
# 维护a ,b
def __init__(self, a, b):
self.a = a
self.b = b
# __iter__方法yield素数
def __iter__(self):
for k in range(self.a, self.b + 1):
if self.is_prime(k):
yield k
# 筛选素数
def is_prime(self, k):
# 除了1和本身以外不能被其他任何数整除,为素数
return False if k < 2 else all(map(lambda x: k % x, range(2, k)))
# 实例化调用
n = PrimeNumbers(1, 30)
for x in n:
print(x)
实现反向迭代
通过反向迭代协议的__reversed__方法,它返回一个反向迭代器
from decimal import Decimal
# 浮点数表示二进制,不会损失精度
class FloatRange:
def __init__(self, a, b, step):
self.a = Decimal(str(a))
self.b = Decimal(str(b))
self.step = Decimal(str(step))
# 正向迭代
def __iter__(self):
t = self.a
while t <= self.b:
yield float(t)
t += self.step
# 反向迭代
def __reversed__(self):
t = self.b
while t >= self.a:
yield float(t)
t -= self.step
fr = FloatRange(3.0, 4.0, 0.2)
# 正向迭代
for f in fr:
print(f)
print('-' * 30)
# 反向迭代
for f in reversed(fr):
print(f)
对迭代器进行切片操作
"""
类似列表切片的方式,获取100-300之间内容的文件生成器
切片的实质是:__getitem__(),有这个方法才可以切片
使用itertools.islice,它能返回一个迭代器对象切片的生成器
"""
from itertools import islice
# 对取文件
f = open("englishTitle.txt", encoding='utf-8')
# 可以切片的生成器
il = islice(f, 10, 40, 2)
# for遍历
for i in il:
print(i)
for语句迭代多个可迭代对象
并行迭代:多个迭代对象对应位置并行处理
from random import randint
# 获取3课成绩
chinese = [randint(60, 100) for _ in range(10)]
english = [randint(60, 100) for _ in range(10)]
math = [randint(60, 100) for _ in range(10)]
# 方法1:
t1 = []
# zip()得到的是一元素为元组的可迭代对象,需要拆包
for s1, s2, s3 in zip(chinese, english, math):
t1.append(s1 + s2 + s3)
print(t1)
# 方法2:sum不需要拆包
t2 = [sum(s) for s in zip(chinese, english, math)]
print(t2)
串行迭代:多个可迭代对象连接,itertools.chain可以把多个可迭代对象连接起来
"""
获取3课成绩分别超过80的个数
"""
from itertools import chain
lenScore = len([x for x in chain(chinese, english, math) if x > 80])
print(lenScore) # 13
文件处理
处理json文件
load()和dump()处理json文件
# dump():将python中的对象转化成json储存到文件中
fw = open("test.json", "w", encoding="utf-8")
data = {"name": "李四", "age": 33, "info": "北京"}
# 将data转化成json存储到test.json文件中
json.dump(data, fw, ensure_ascii=False)
fw.close()
# load():将文件中的json的格式转化成python对象提取出来
fr = open("test.json", 'r', encoding="utf-8")
jp = json.load(fr)
print(jp)
loads()和dumps()处理字符串
# dumps():将python对象编码成Json字符串
# 字典转json字符串
data1 = {"name": "李四", "age": 33, "info": "北京"}
jd = json.dumps(data1)
print(type(jd)) # <class 'str'>
# load():将Json字符串解码成python对象
jp = json.loads(jd)
print(type(jp)) # <class 'dict'>
处理xml文件
from xml.etree import ElementTree
# 传入xml文件
et = ElementTree.parse("xmltest.xml")
print(et) # <xml.etree.ElementTree.ElementTree object at 0x00C2E6D0>
# 或者传入xml格式的string
# ElementTree.fromstring("xxxx")
# 获取根元素
root = et.getroot()
print(root) # <Element 'sites' at 0x02364488>
# 元素标签名
print(root.tag) # sites
# 元素属性
print(root.attrib) # 获取属性字典
# 获取元素的子元素列表
children = list(root)
print(children)
# 子元素的属性名获取属性值
c1 = children[0]
print(c1.get("name"))
# 获取元素的文本
c2 = c1[0]
ct = c2.text
print(ct) # 菜鸟教程
# 查找子元素单个特定的元素
print(root.find("site2")) # <Element 'site2' at 0x013345F0>
# 查找子元素特定元素的列表
print(root.findall("site2"))
# 查找任意位置的元素
rl = root.iter("site2")
print(list(rl))
# 通过xpath表示式查找带有attr2属性的元素
fl = root.findall(".//*/*[@attr2]")
print(list(fl)) # [<Element 'name' at 0x01F745A0>]
# 获取子元素下面所有文本列表
lt1 = c1.itertext()
print(list(lt1))
# 过滤空白文本
lt2 = ' '.join(t for t in c1.itertext() if not t.isspace())
print(lt2) # 菜鸟教程 www.runoob.com
处理excel文件
from openpyxl import load_workbook
# 1.打开 Excel 表格并获取表格名称
workbook = load_workbook(filename="Python招聘数据.xlsx")
print(workbook.sheetnames)
# 2.通过 sheet 名称获取表格
sheet = workbook["Sheet1"]
print(sheet)
# 3.获取表格的尺寸大小(几行几列数据) 这里所说的尺寸大小,指的是 excel 表格中的数据有几行几列,针对的是不同的 sheet 而言。
print(sheet.dimensions)
# 4.获取表格内某个格子的数据
# 1 sheet["A1"]方式
cell1 = sheet["A1"]
cell2 = sheet["C11"]
print(cell1.value, cell2.value)
"""
workbook.active 打开激活的表格; sheet["A1"] 获取 A1 格子的数据; cell.value 获取格子中的值;
"""
# 4.2sheet.cell(row=, column=)方式
cell1 = sheet.cell(row=1, column=1)
cell2 = sheet.cell(row=11, column=3)
print(cell1.value, cell2.value)
# 5. 获取一系列格子
# 获取 A1:C2 区域的值
cell = sheet["A1:C2"]
print(cell)
for i in cell:
for j in i:
print(j.value)