1. 简介
以standalone模式安装spark集群bin运行demo。
2.环境和介质准备
2.1 下载spark介质,根据现有hadoop的版本选择下载,我目前的环境中的hadoop版本是2.6,所以下载spark-2.0.0-bin-hadoop2.6.tgz
当然你也可以下载源码自行根据hadoop版本进行编译,这里不再赘述。
地址:http://ftp.cuhk.edu.hk/pub/packages/apache.org/spark/spark-2.0.0/

2.2 环境准备
| 主机名称 | 进程名称 |
| xufeng-1 | work |
| xufeng-2 | work |
| xufeng-3 | master |
3. 安装步骤:
【以下步骤不单独说明所有主机都需要执行】
步骤 1:将介质包拷贝到服务器上,并将配置文件和bin文件分开。

可以看到spark目录使用了软连接,配置文件被单独放在了spark-config中,这样做的目的是便于升级。
步骤 2:设定环境变量.
在~/.bash_profile文件中增加如下信息:
#spark export SPARK_HOME=/opt/hadoop/spark export SPARK_CONF_DIR=/opt/hadoop/spark-config PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
步骤 3:配置slaves:
打开spark-config目录下的slaves文件将work部署的主机名信息写入:
# A Spark Worker will be started on each of the machines listed below. xufeng-1 xufeng-2
步骤 4:配置javahome
打开spark-config目录下的spark-env.sh文件,设定如下信息(根据自己的java路径信息):
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0) export JAVA_HOME=/opt/hadoop/java/jdk1.7.0_79
4. 启动集群
4.1 登录上master节点,也就是xufeng-3节点,进入spark/sbin目录,执行
./start-all.sh ------- spark的脚本和hadoop的脚本是同名的,如果我们直接执行start-all.sh,那么很有可能执行的是hadoop的脚本,所以这里进入spark安装目录,具体调用他的脚本
4.2 检查Master 的 webUI
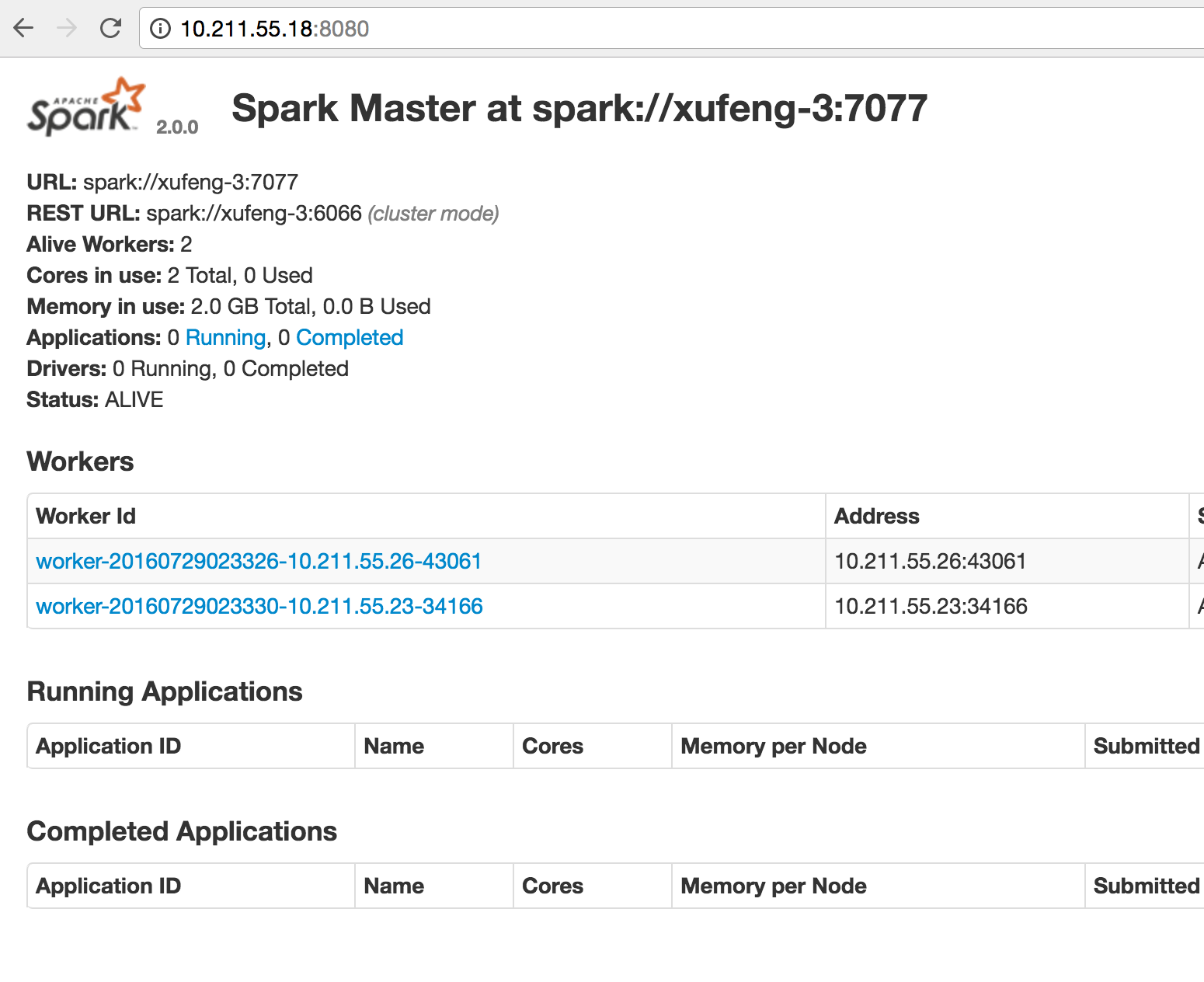
以上Mater和worker在standalone模式中就是一个资源管理器系统,分配app的资源使用或者我们可以直接说他是一个【Cluster Manager】。
在其他模式中,如在YARN模式中资源的分配就交给YARN去处理,YARN集群就是【Cluster Manager】角色了。
5. 验证
进入spark-shell 简单的去执行一个任务用于验证
如果不知道后续参数,那么这个shell将会在本地执行,在Mater页面上是看不到信息的。
spark-shell --master spark://xufeng-3:7077 --executor-memory 500M

1.创建一个rdd
scala> val rdd = sc.parallelize(List(1,2,3,4,5,6))
2.执行两次count和一次collect操作(action操作)
scala> rdd.count() res0: Long = 6 scala> rdd.count() res1: Long = 6 scala> rdd.collect res2: Array[Int] = Array(1, 2, 3, 4, 5, 6)
查看页面监控:

以上,standalone模式安装完毕。