第一种方案:
SELECT * FROM `follow_record` AS t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(record_id) FROM `follow_record`)-(SELECT MIN(record_id) FROM `follow_record`))+ (SELECT MIN(record_id) FROM `follow_record`)) AS record_id) AS t2 WHERE t1.record_id >= t2.record_id ORDER BY t1.record_id LIMIT 100;
加条件:
SELECT COUNT(record_id) FROM `follow_record` WHERE record_addtime>="2019-02-01 21:29:20" AND record_gs="布拖县"
SELECT * FROM `follow_record` AS t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(record_id) FROM `follow_record`)-(SELECT MIN(record_id) FROM `follow_record`))+ (SELECT MIN(record_id) FROM `follow_record` where record_addtime>="2019-03-01 21:29:20")) AS record_id) AS t2 WHERE t1.record_id >= t2.record_id AND record_addtime>="2019-02-01 21:29:20" AND record_gs="布拖县" ORDER BY t1.record_id LIMIT 100;
在Mysql工具中测试结果是0.01-0.03sec。
第二种方案:
SELECT * FROM `follow_record` WHERE record_id >= (SELECT floor(RAND() * (SELECT MAX(record_id) FROM `follow_record`))) ORDER BY record_id LIMIT 100;
SELECT * FROM `follow_record` WHERE record_id >= (SELECT floor(RAND() * (SELECT MAX(record_id) FROM `follow_record`))) AND record_addtime>="2019-02-01 21:29:20" AND record_gs="布拖县" ORDER BY record_id LIMIT 100;
在Mysql工具中测试结果是0.04-0.05sec。
第三种方案:
SELECT * FROM `follow_record` WHERE record_id >= (SELECT floor( RAND() * ((SELECT MAX(record_id) FROM `follow_record`)-(SELECT MIN(record_id) FROM `follow_record`)) + (SELECT MIN(record_id) FROM `follow_record`))) ORDER BY record_id LIMIT 100;
SELECT * FROM `follow_record` WHERE record_id >= (SELECT floor( RAND() * ((SELECT MAX(record_id) FROM `follow_record`)-(SELECT MIN(record_id) FROM `follow_record`)) + (SELECT MIN(record_id) FROM `follow_record`))) AND record_addtime>="2019-02-01 21:29:20" AND record_gs="布拖县" ORDER BY record_id LIMIT 100;
在Mysql工具中测试结果是0.04-0.05sec。
第四种方案:
SELECT * FROM `follow_record` WHERE record_id >= ((SELECT MAX(record_id) FROM `follow_record`)-(SELECT MIN(record_id) FROM `follow_record`)) * RAND() + (SELECT MIN(record_id) FROM `follow_record`) limit 100;
SELECT * FROM `follow_record` WHERE record_id >= ((SELECT MAX(record_id) FROM `follow_record`)-(SELECT MIN(record_id) FROM `follow_record`)) * RAND() + (SELECT MIN(record_id) FROM `follow_record`) AND record_addtime>="2019-02-01 21:29:20" AND record_gs="布拖县" limit 100;
UPDATE `follow_record` SET record_addtime="2019-04-04 21:29:20" WHERE record_id in ( SELECT F.record_id FROM (SELECT record_id FROM `follow_record` WHERE record_id >= ((SELECT MAX(record_id) FROM `follow_record`)-(SELECT MIN(record_id) FROM `follow_record`)) * RAND() + (SELECT MIN(record_id) FROM `follow_record`) AND record_addtime>="2019-02-01 21:29:20" AND record_gs="布拖县" limit 10) F)
在Mysql工具中测试结果是0.02-0.04sec。
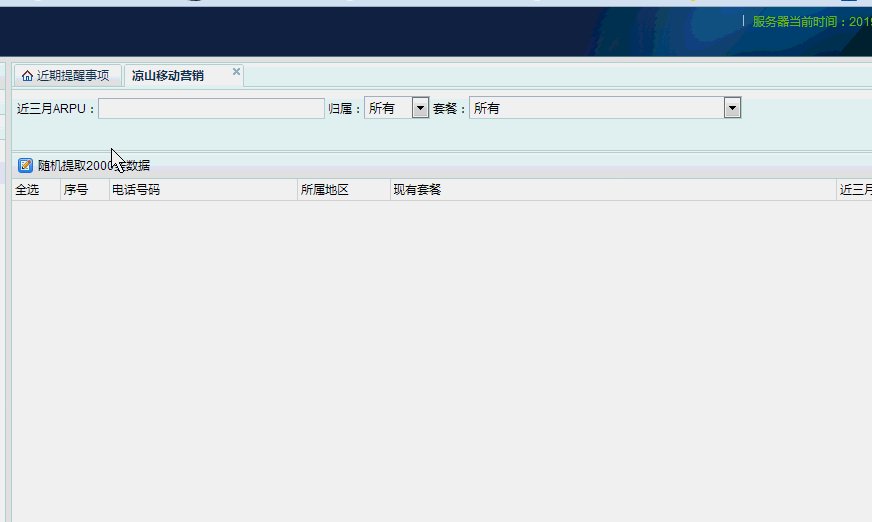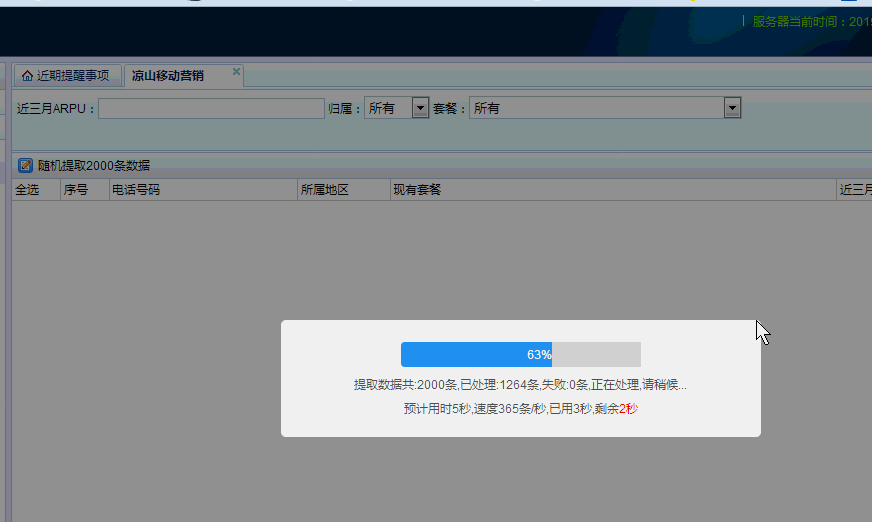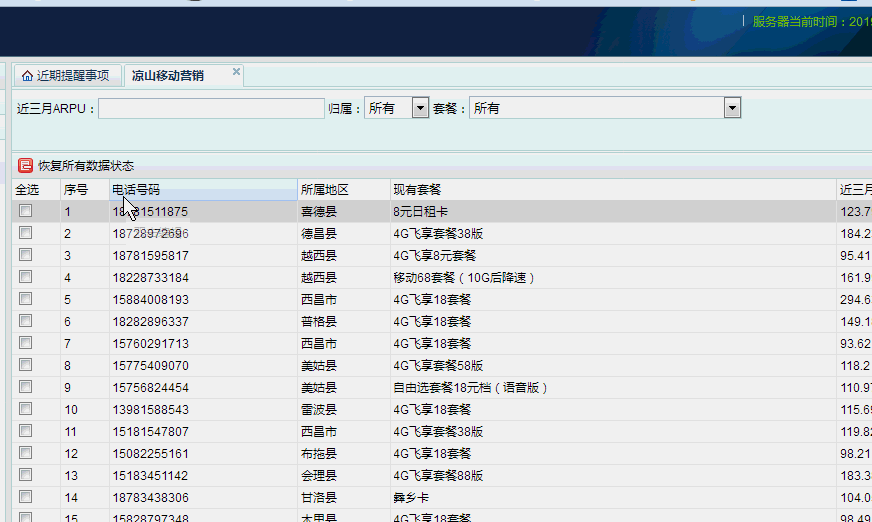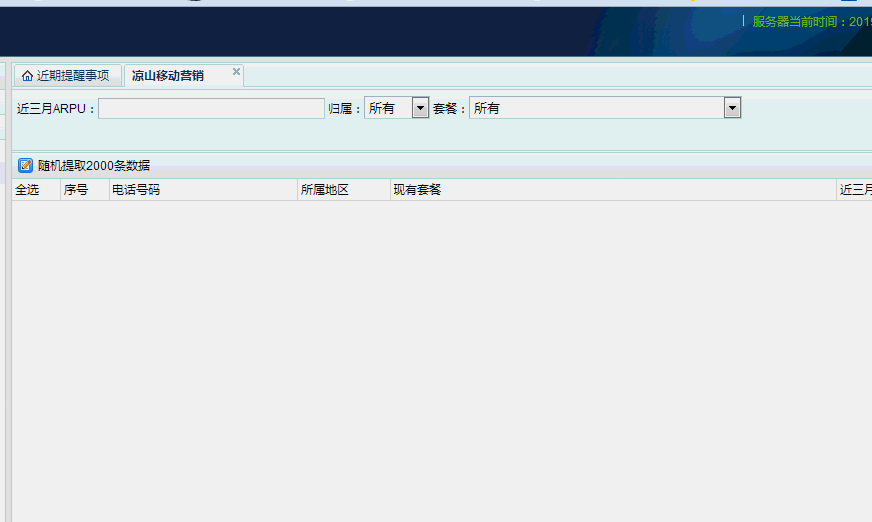
在线测试从170万条数据中,随机提取2000条并修改相应字段