简单动态字符串
redis字符串底层并不是直接拿c字符串来处理的。
redis字符串底层存储结构是SDS
- SDS包含三个属性
- len 字符串长度
- 好处
- 传统c字符串遍历长度的时候会去遍历字符串,而SDS保留了长度空间,将获取长度的时间复杂度控制在O(1)。
- 避免缓冲区溢出,c字符串在将AB两个字符串拼接的时候不会考虑,A是否能容得下A+B有溢出的风险,而SDS在执行拼接api的时候会校验长度。
- 减少修改字符串时带来的内存重分配次数。
- 空间预分配(字符串增长的操作):
- 判断结果字符串是否>1M
- 是(假设5M),分配1M空间作为free空间,最终大小为5M+1M+1byte
- 否(假设500k),分配500k作为free空间,最终500k+500k+1byte
- 判断结果字符串是否>1M
- 惰性空间释放(字符串剪短的操作)
- 将字符串剪短后,不会立即释放多出来的空间长度,而是将它们的长度记录在free字段中,留待下次利用。
- 空间预分配(字符串增长的操作):
- 好处
- free 字符串未使用的空闲空间(不包含在len中)
- buf[] 字符数组,存储实际的字符(包含最后的’/0’空字符,空字符不包含在len和free中,buf的实际长度是len+free+1)
- len 字符串长度
- 总结

链表
- 一个链表由一个list结构和多个listNode节点组成
- list结构中包含几个重要属性
- len 长度,链表有多少元素。
- head 头节点,指向链表头节点
- tail 尾节点,指向链表尾节点 (前三点都是为了让获取这些节点的时间复杂度达到O(1))
- 以及其它一些用于操作的重要属性不赘述
- listNode结构
- pre 前驱节点
- next 后继节点
- val 值
HASH表
- 一个hash表由一个dictht结构和多个hash节点组成
- dictht类似与list,保存多个重要属性
- dicEntry **table hash表节点数组
- size hash表大小
- sizemask 用于计算索引值(总是等于size-1,推测类似于java的hashMap计算索引值,也是用size-1 & hash(key))
- used 该hash表已有节点的数量
- dicEntry结构
- key
- value
- next 指向下一个节点形成链表(类似与hashMap的结构 将相同索引值的key在一个桶中形成链表)
字典
- redis中的字典是由hash表实现的
- dict结构
- dictType 类型函数 保存了一簇操作特定类型键值对的函数
- privdata 私有数据 保存了需要传给那些特定类型函数的可选参数
- ht[2] hash表数组 一般情况下使用的是ht[0]数组 只有当字典进行rehash时才使用ht[1]数组
- trehashidx rehash索引 当rehash不在进行时值为-1
- hash算法,hash算法与java hashmap的hash算法一致,不赘述
- hash碰撞处理方式也与java hashmap的处理方式一致,链表化处理
- rehash操作 如下 (size始终保持是2的n次方,size-1来计算索引值减少hash碰撞)
- 扩展与收缩的时间点选择

- rehash操作在元素比较多的时候不是一次性完成的,而是渐进式完成,rehashidx置成0表示rehash开始,此时字典在接收数据的时候会同时rehash值到ht[1]中,同时rehashoidx +1,直到所有值都rehash完成,将rehashidx -> -1,同时释放ht[0],将ht[1]置成ht[0]。


跳跃表
- 跳跃表结构由zskiplist和zskiplistnode结构组成
- zskiplist
- header
- tail
- level 层高最高的节点的层数。tips:头节点不计算在内可以假设头节点的层高恒为32
- length
- zskiplistnode
- level[] 节点所在层,它是一个数组,层数越多代表访问其他节点越快
- 每一层都有一个指向表尾方向的前进指针
- 每生成一个新节点level[]的大小会在1-32之间随机生成
- backward 前驱元素,表尾向表头遍历时使用
- score 分值 用于排序
- obj 节点保存的对象
- level[] 节点所在层,它是一个数组,层数越多代表访问其他节点越快
- 保存的对象不能重复,但是分值可以重复,分值重复了就按对象在字典中的顺序排序。
整数集合
- 整数集合是集合键的底层实现之一,当一个集合只包含整数元素,并且元素数量不多的时候,redis就会使用整数集合作为集合键的底层实现。
- 实现方式intset结构
- encoding 编码方式
- length 元素数量
- contents[] 保存元素的数组 各个项在数组中按从小到大有序排列并且不包含重复元素。
- 升级操作,当指定数组encoding为16位时:
- 如果此时添加一个32位的整数会触发升级操作。
- 触发升级操作之后会将整个数组重新分配内存重新计算元素位置,所以整数数组添加元素的时间复杂度O(n)。
- 由于触发升级的新元素一定是大于或者小于原集合中的所有元素的,所以新元素的位置要么在第一位,要么在最后一位。
- 升级的好处:
- 提升整数数组的灵活性 因为c语言是静态类型语言避免类型错误一般不会将不同的数据类型放在同一个结构里。
- 节约内存 只有在必要的时候才去升级,尽可能的节约内存。
- 升级的好处:
- 不支持降级操作。
压缩列表 不赘述了 自行查阅redis设计与实现第二版
- 是列表键和hash键的底层实现之一,当一个列表只包含少量列表项,并且每个列表项是小整数或者长度比较短的字符串,那么redis就会使用压缩列表来做底层实现。
对象
- redis没有直接使用以上数据结构构造键值对数据库,而是基于这些数据结构创建了一个对象系统。
- 每当我们在redis数据库中创建一个键值对时至少会创建两个对象
- 比方说set msg hello
- 键是包含了msg值的字符串对象
- 值是包含hello值的字符串对象

-
对象的type属性记录的是类型(键对象只有字符串,而值对象对应五种(string,list,hash,set,zset))。
-
我们用type key 命令时,输出的是值的对象属性。
-
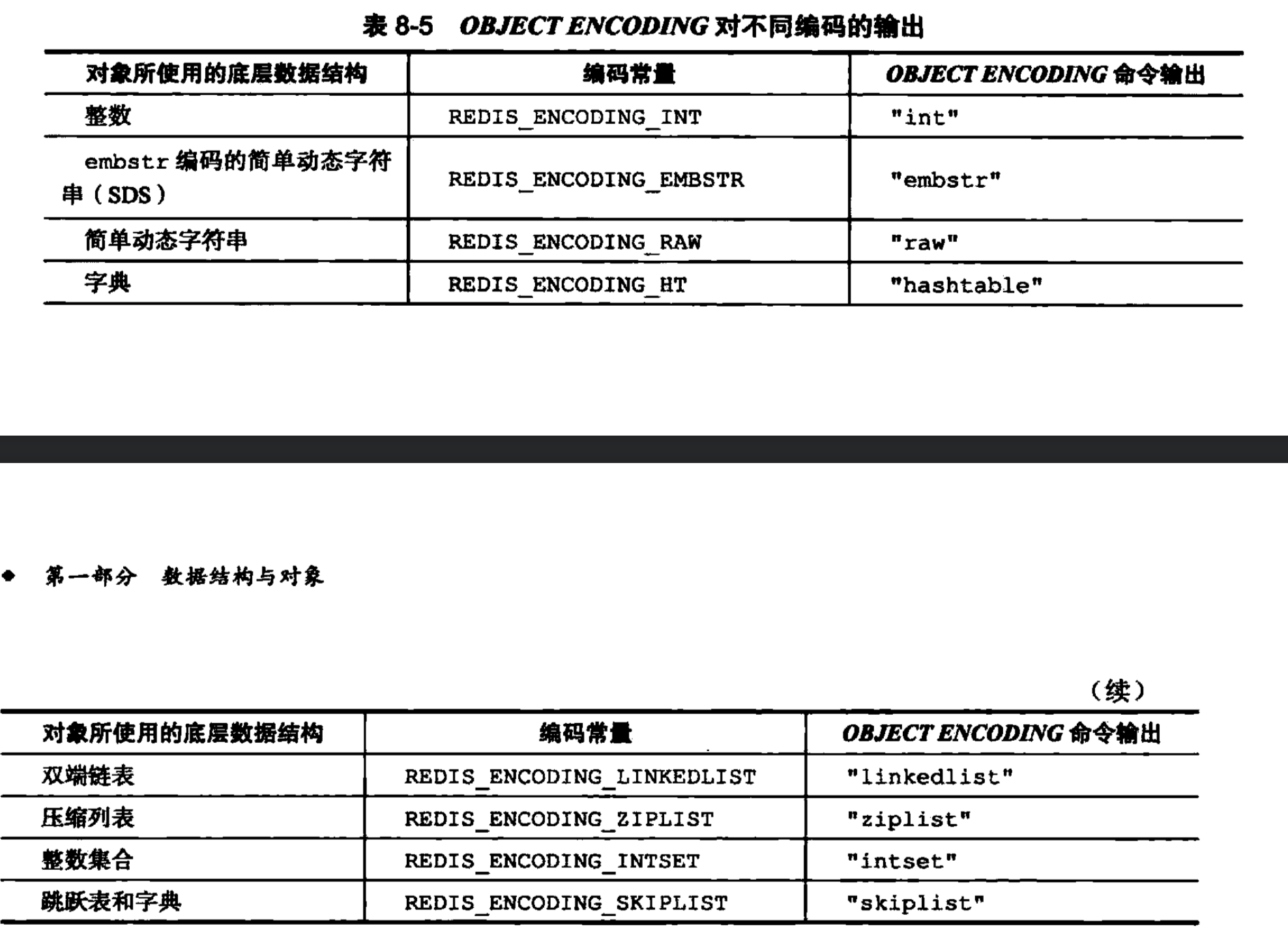
对象的ptr属性指向底层的数据结构,而这些底层的数据结构由encoding决定。以下是object encoding 的输出
-
-
- 比方说set msg hello