前言
前面介绍了SRE的基础,包括SLI和SLO以及Error Budget(错误预算)。其中:
SLI是衡量系统稳定性的指标;
SLO是每个指标对应的衡量目标;
SLO转化为错误预算(更直观便与量化);
转化后做稳定性提升保障工作,就是想办法不要把错误预算消耗完,或不能把错误预算快速大量消耗掉。
其实在SRE落地实践过程中,主要是解决如下两种情况的问题:
- 制定的错误预算在周期还没结束前就消耗完了,这意味着稳定性目标未达成;
- 另一种是错误预算在单次问题中被消耗过多,这时候要把这样的问题定性为故障;
这篇文章,主要说明如何通过应对故障来落地SRE。
故障发现:建设On-Call机制
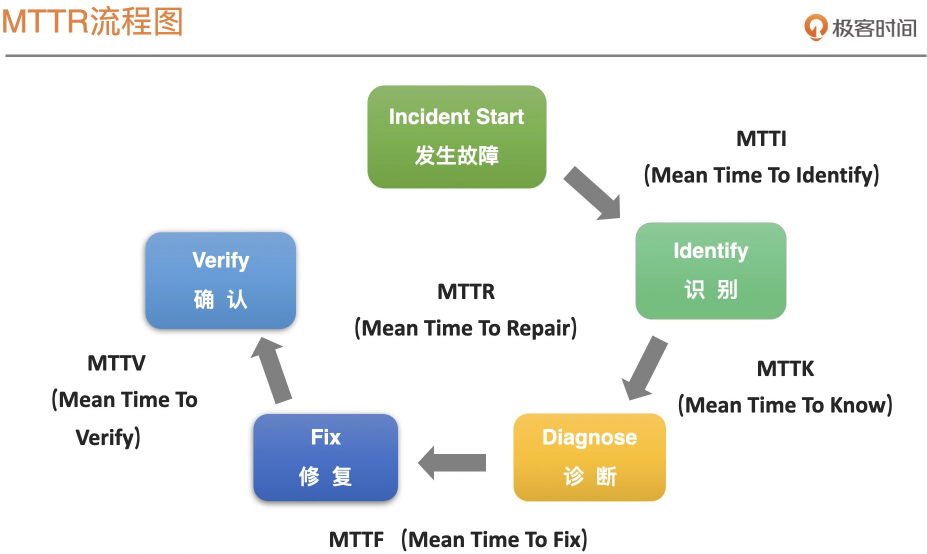
1、MTTR-故障处理流程
2、MTTR各环节所占时长
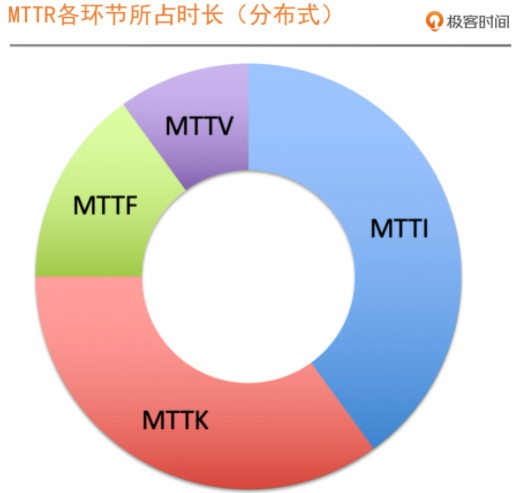
绝大多数故障,只要能定位问题根因,往往就能快速解决。
故障处理的生命周期中,大部分时间耗费在寻找和定位问题上面。
分布式系统中,往往优先级最高的是线上业务止血(即Design for Failure策略)。通过服务限流、降级、熔断甚至主备切换等手段,来快速恢复线上业务的可用性。
故障处理的核心:提升MTTR每个环节的处理效率,缩短处理时间,这样才能缩短整个MTTR,减少对错误预算的消耗。
3、MTTI:从发现到响应故障
MTTI:故障的平均确认时间。即从故障实际发生的时间点,到出发采取行动去定位前的这段时间。
这个环节,主要做两件事:
1)判断出现的问题是不是故障(主要依赖于监控和告警体系);
2)确定由谁来响应和召集人进行处理(需要一套明确清晰的决策及消息分发机制);
这两件事,其实就是SRE中的On-Call机制(一般有专门的NOC岗位来负责响应和召集)。
On-Call机制的核心,就是确保关键角色实时在线,随时应急响应。
4、On-Call机制流程建设
1)确保关键角色在线(轮班的各岗位关键角色,需要有backup);
2)组织War Room应急组织(常见的有线上消防群&线上监控告警群);
3)建立合理的消息分发方式(谁值守谁负责,而不是谁最熟悉谁负责);
4)确保资源投入的升级机制(即值班相关SRE角色有权调动其他资源,甚至故障升级);
5)与云厂商联合的On-Call机制(对于上云的企业,和云厂商共建故障信息对接群,定时故障演练);
6)终极方案:针对可能出现的故障,落地故障应急SOP,制定“故障应急处理手册”,这样人人都是SRE。
5、On-Call机制的优势
1)最快最好的熟悉系统的方式;
2)培养和锻炼新人以及backup角色;
3)新人融入团队和承担责任的最佳方式;
故障处理:恢复业务为最高优先级
在MTTR环节中,MTTK、MTTF、MTTV分别对应故障诊断、故障修复与故障确认。
故障处理的最终目标:采取所有手段和行动,一切以恢复线上业务可用为最高优先级。
1、常见的故障蔓延原因
1)故障隔离手段缺失(限流、降级、熔断、弹性扩容);
2)关键角色和流程机制缺失(信息同步、方案决策、反馈机制);
3)线上故障灾备演练环节缺失(故障应急SOP、故障应急处理手册);
2、Google故障指挥体系
- IC(Incident Commander):故障指挥官,这个角色是整个指挥体系的核心,最重要的职责是组织和协调,而非执行,下面所有角色都要接受他的指令并严格执行。
- CL(Communication Lead):沟通引导,负责对内和对外的信息收集及通报,这个角色一般相对固定,由技术支持、QA或者是某个SRE来承担,要求沟通表达能力要比较好。
- OL(Operations Lead):运维指挥,负责指挥或指导各种故障预案的执行和业务恢复。
- IR(Incident Responders):即所有需要参与到故障处理中的各类人员,真正的故障定位和业务恢复都是他们来完成的,如具体执行的SRE、运维、业务开发、平台开发、DBA,甚至是QA 。
3、建立有效的应急响应机制
3.1流程机制
1)故障发生后,On-Call的SRE最开始是IC,有权召集相关角色和资源,快速组织线上消防;
2)如果问题和恢复过程非常明确,IC仍是SRE不做转移,由他指挥每个人要做的事情,优先恢复业务优先;
3)如果问题疑难或影响范围大,SRE可以要求更高级别的角色介入如 SRE主管或总监。一般原则是谁业务受影响最大谁牵头组织。
这时IC的职责转移给更高级别的主管。如果是全站范围的影响,必要时技术VP或CTO也可以承担IC职责,或授权给某位总监承担;
4)SRE回归到OL的职责上,负责组织和协调具体的执行恢复操作的动作。
3.2反馈机制
1)定时反馈(10-15分钟),没有进展也要及时反馈;
2)执行操作或变更事先通报,说明变更操作重点和影响范围;
3)尽量减少对执行者的干扰,让执行者能够聚焦;
4)信息要及时同步给客服、PR及商家和其他各类合作方;
5)团队leader收集反馈并传递IC的指令,CL收集信息并在更大范围内同步汇总后的信息,同事传递给外部联系人;
6)除了快速恢复业务,保持信息及时同步和透明也非常关键(便于对用户和其他平台的安抚措施能够快速执行到位)!
注意:信息同步尽量不要用技术术语,尽量以业务画的语言描述,并给到对方大致的预期!
故障复盘:黄金三问与判定三原则
故障复盘的核心:从故障中学习和提升!
故障复盘的教训:故障根因往往不止一个,要聚焦到引起故障的原因都是哪些,是否都有改进空间。
故障复盘的心得:解决问题,而不是不断提出新的问题!
1、故障复盘黄金三问
1)第一问:故障原因有哪些?
2)第二问:我们做什么,怎么做才能确保下次不会出现类似故障?
3)第三问:当时如果我们做了什么,可以用更短的时间恢复业务?
注意事项:对事不对人,不允许出现互相指责和埋怨甩锅。故障复盘的核心是找到原因并加以改进,落地优化。
2、故障判定的三原则
1)健壮性原则:每个组件自身要具备一定的自愈和高可用能力,而非全部由下游依赖放兜底;
2)三方默认无责:对内谁受影响谁改进,对外推进第三方改进(稳定性要做到相对自我可控,而不是完全依赖外部);
3)分段判定原则:对于原因较复杂或链路较长的故障,建议分阶段评估,不同阶段有不同的措施。这一原则的出发点是要摒弃“故障根因只有一个”的观点。
典型案例:互联网的SRE组织架构
在SRE体系中,高效的的故障应对和管理工作,需要整个技术团队共同参与和投入。
1、互联网典型技术架构
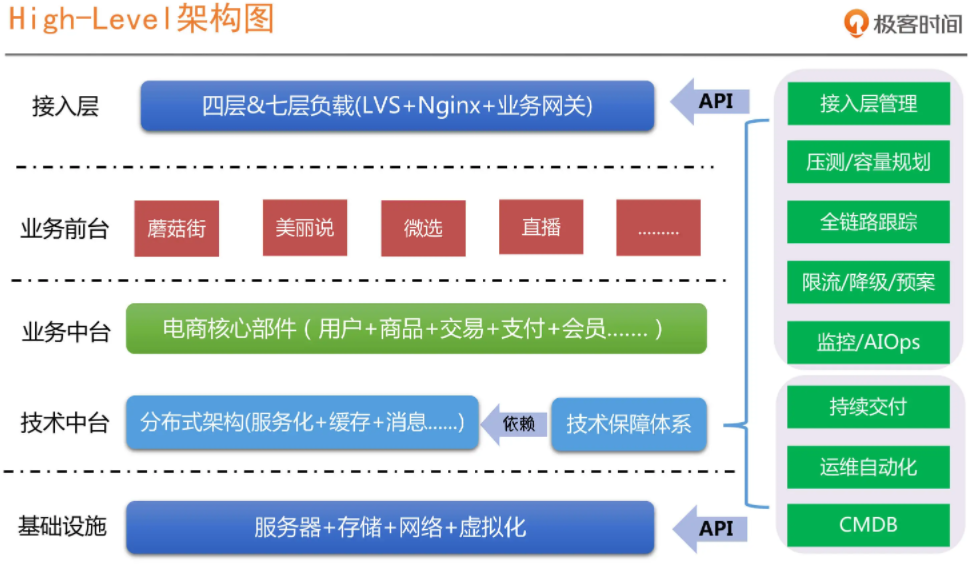
参考:SRE组织架构的构建原则
- 组织架构要与技术架构相匹配(两者是互相补充和促进的作用);
- SRE是微服务和分布式架构的产物(微服务和分布式技术复杂性对传统的运维模式和理念产生了冲击和变革);
2、系统架构的演变历程
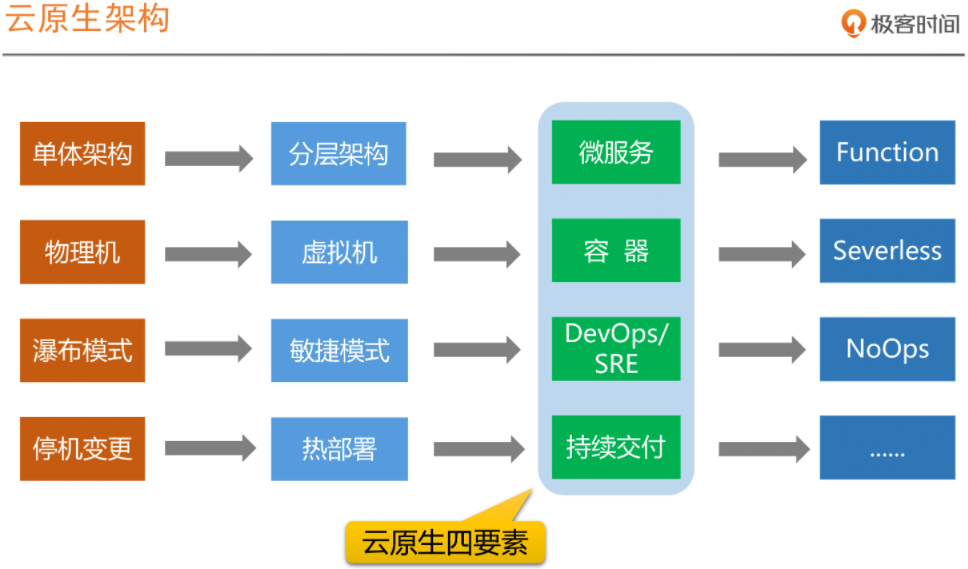
要引入SRE体系,并做对应的组织架构调整,首先要看技术架构是否朝着服务化和分布式方向演进。
要想在组织内引入并落地SRE体系,原有技术团队的组织架构或协作模式必须要做出一些变革。
3、互联网组织架构示意图
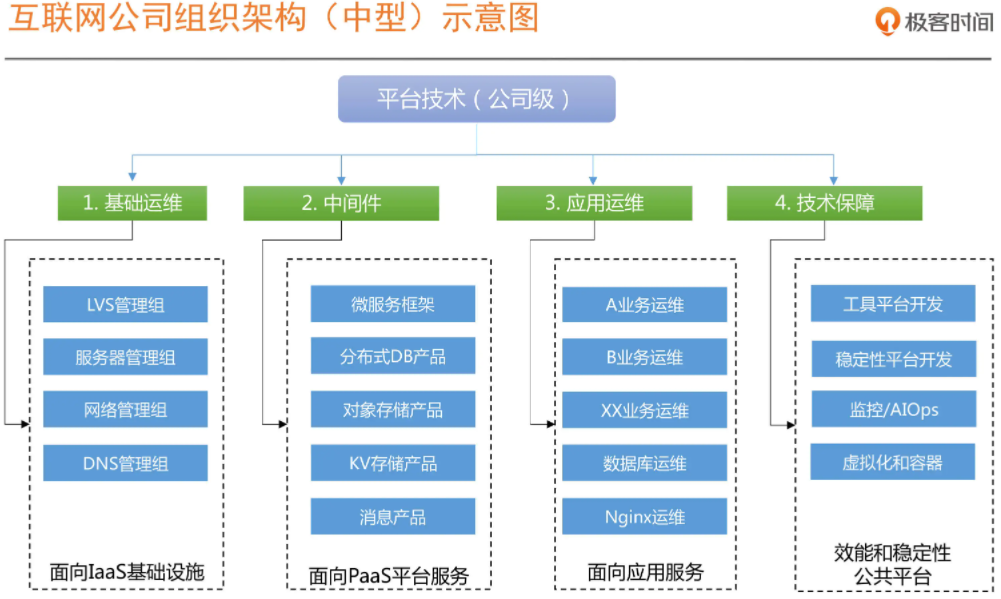
基础设施:传统运维这个角色所具备的能力。
平台服务:包括常见的技术中台(有状态的数据产品研发团队)和业务中台(无状态的具有业务共性的业务研发团队)以及业务前台(H5&前端&移动端产品研发团队)。
技术保障平台:微服务和分布式架构下的运维能力,是整个技术架构能力的体现,而不是单纯的运维能力体现。
工程效能平台:负责效能工具的研发,比如实现 CMDB、运维自动化、持续交付流水线以及部分技术运营报表的实现,为基础运维和应用运维提供效率平台支持(对业务理解及系统集成能力要比较强,但是技术能力要求相对就没那么高)。
稳定性保障平台:负责稳定性保障相关的标准和平台,比如监控、服务治理相关的限流降级、全链路跟踪、容量压测和规划(技术要求和团队建设复杂度较高,需要很多不同领域的专业人员)。
总结:SRE = PE + 工具平台开发 + 稳定性平台开发!
业内经验:高效的SRE组织协作机制
SRE落地经验:以赛带练。
1、什么是以赛带练?
“以赛带练”这个术语最早出自体育赛事中,即通过比赛带动训练(如足球、篮球或田径比赛)。
目的是在真实的高强度竞争态势和压力下,充分暴露出个人和团队的不足及薄弱点,然后在后续的训练中有针对性地改进,这样对于比赛成绩的提升有很大帮助,而不是循规蹈矩地做机械性训练。
2、SRE落地如何以赛带练?
以赛带练的策略放在系统稳定性建设中非常适用。
通过选择类似的真实且具备高压效果的场景,来充分暴露稳定性存在哪些问题和薄弱点,然后有针对性地进行改进。
类似的场景,如电商类产品的双十一大促、社交类产品在春晚的抢红包,以及媒体类产品的突发热点新闻等,对于系统的稳定性冲击和挑战非常大。
再或者是极端故障场景,如机房断电、存储故障或核心部件失效。稳定性建设,一定也是针对极端场景下的稳定性建设。
“以赛带练”的目的就是要检验系统稳定性状况到底如何,系统稳定性还有哪些薄弱点。
3、SRE各个角色如何协作?
案例:双十一大促保障!
1)大促项目kickoff(项目启动会)
2)核心链路技术指标拆解及模型评审(用户模型、流量模型、压测模型)
3)稳定性预案评审(前置预案、主动预案、紧急预案、恢复预案)
4)全链路压测及复盘会议(每轮压测结束都需要进行复盘总结和落地TODO项)
通过上述每个环节的工作细节,让不同角色都参与进来!
4、哪些事项可以做到日常化?
除了大促或者极端场景之外,将一些案例落地到日常的工作中,是提升稳定性的进阶工作。场景如下:
1)核心应用变更及新应用上线评审;
2)周期性的技术运营以及汇报工作场景;
概括总结:实践是检验SRE的唯一标准
落地实践,小步快跑胜过考虑太多!
实践需要落实到具体的真实的场景和细节问题上,而不是凭空虚构!
落地SRE要尽可能早的参与到项目中,而非等到线上出问题才考虑引入SRE机制!
SRE 更多的要成为稳定性的监督者和推进者,而不是各种问题的救火队员!
相关书籍
《The Site Reliability Workbook》:兼具普适性和参考性;
《Building Secure&Reliable Systems》:适合进阶阶段阅读;
《Site Reliability Engineering》:SRE落地取得一定成效后阅读;