转:
- KNN算法的缺陷
观察下面的例子,我们看到对于样本X,通过KNN算法,我们显然可以得到X应属于红点,但对于样本Y,通过KNN算法我们似乎得到了Y应属于蓝点的结论,而这个结论直观来看并没有说服力。

由上面的例子可见:该算法在分类时有个重要的不足是,当样本不平衡时,即:一个类的样本容量很大,而其他类样本数量很小时,很有可能导致当输入一个未知样本时,该样本的K个邻居中大数量类的样本占多数。 但是这类样本并不接近目标样本,而数量小的这类样本很靠近目标样本。这个时候,我们有理由认为该位置样本属于数量小的样本所属的一类,但是,KNN却不关心这个问题,它只关心哪类样本的数量最多,而不去把距离远近考虑在内,因此,我们可以采用权值的方法来改进。和该样本距离小的邻居权值大,和该样本距离大的邻居权值则相对较小,由此,将距离远近的因素也考虑在内,避免因一个样本过大导致误判的情况。
从算法实现的过程可以发现,该算法存两个严重的问题,第一个是需要存储全部的训练样本,第二个是计算量较大,因为对每一个待分类的样本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。KNN算法的改进方法之一是分组快速搜索近邻法。其基本思想是:将样本集按近邻关系分解成组,给出每组质心的位置,以质心作为代表点,和未知样本计算距离,选出距离最近的一个或若干个组,再在组的范围内应用一般的KNN算法。由于并不是将未知样本与所有样本计算距离,故该改进算法可以减少计算量,但并不能减少存储量。
___________________________________________________________________________
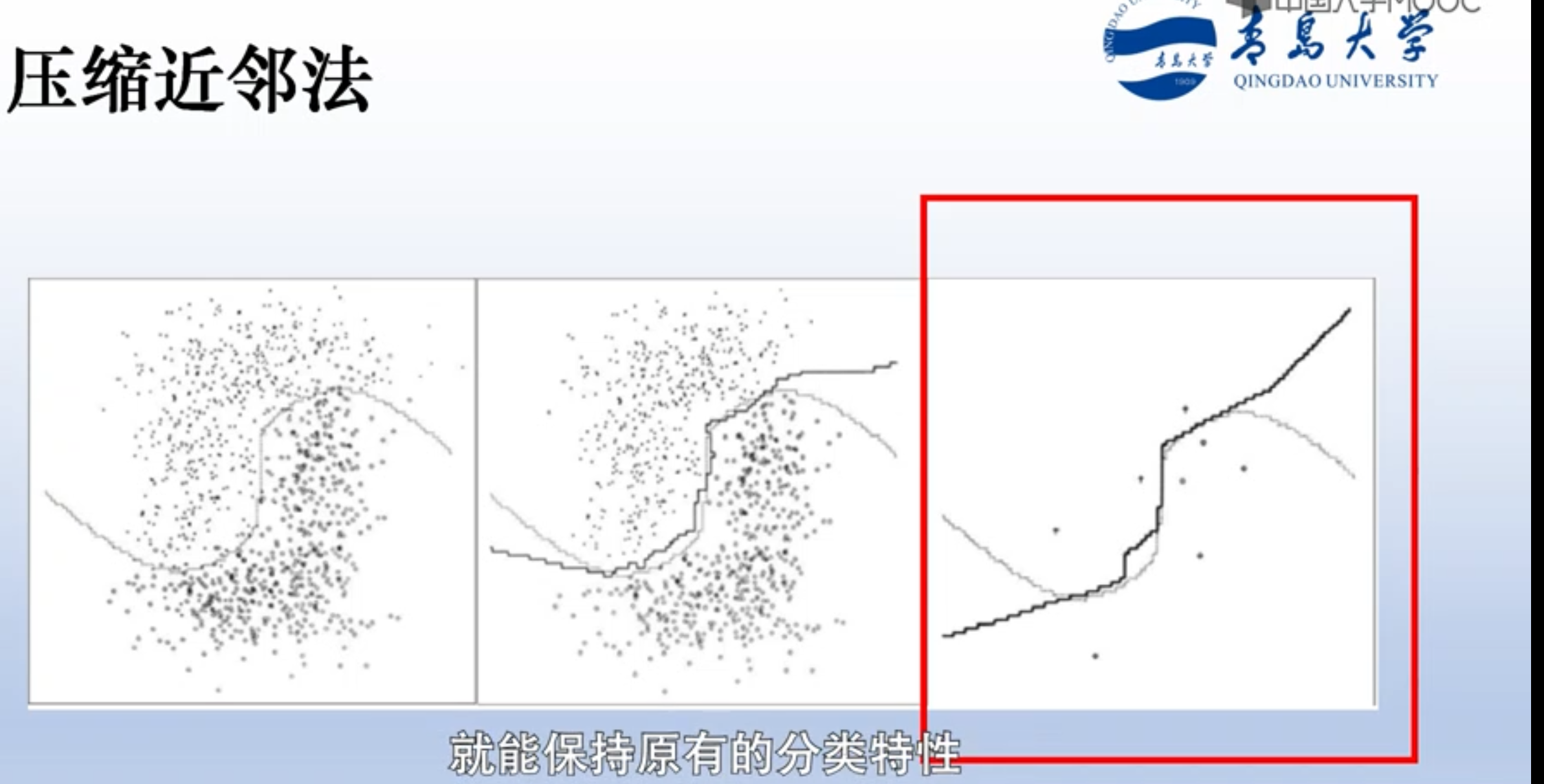
以上的快速搜索近邻法,数据存储量比原始knn还大。剪辑近邻法,会减少模板数量,数量少了,计算也就少了。
思想是:如果两个类中间有重叠部分,那重叠部分的样本点肯定不好,会影响分类结果(因为那块比较模糊,距离小,容易错分),所以考虑把重叠部分的样本点直接删掉。
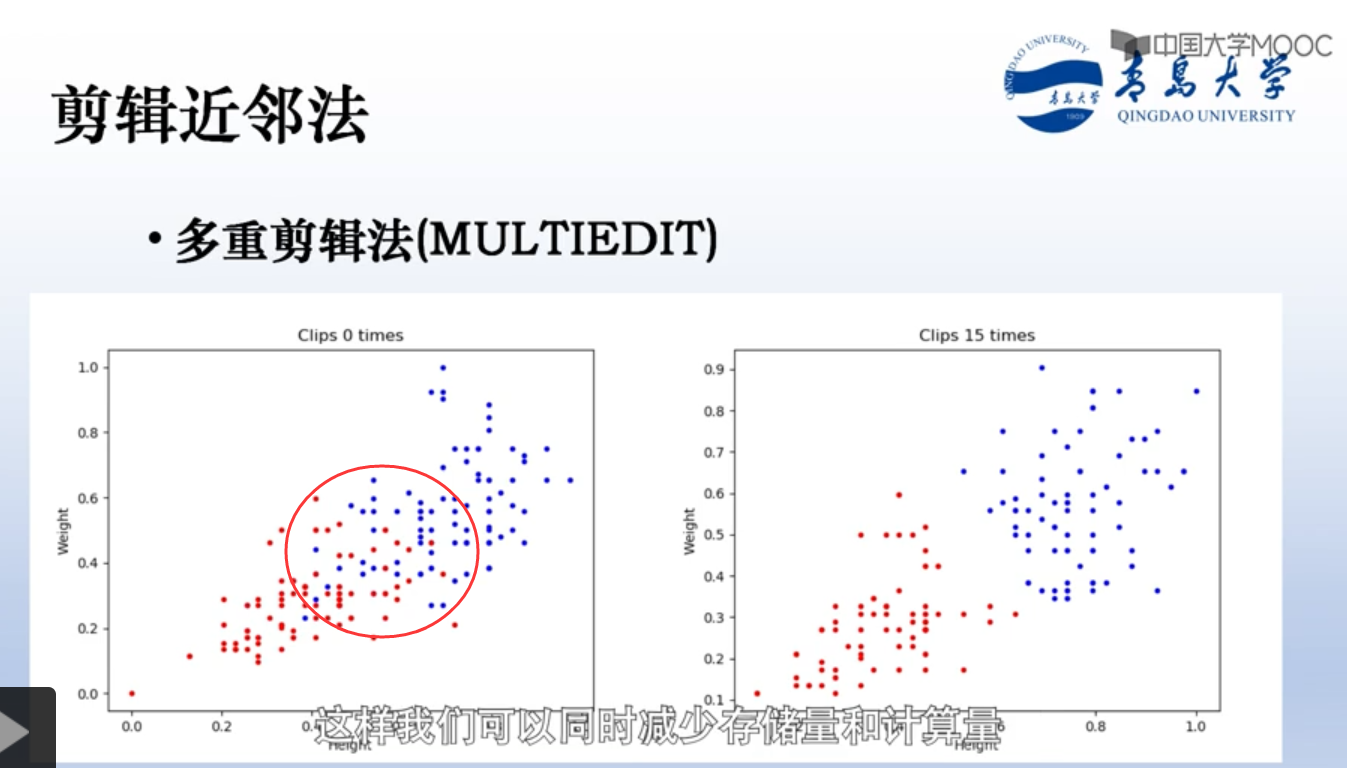
怎么删:把数据集划分为训练集和测试集。

如果数据足够多,还可以多重剪辑,这样剪的更多,“误导样本”更少。

————————————————————————————————————————————————————————————————————————

压缩近邻法,因为剪辑近邻法只对重叠部分的样本点剪辑了,剩下的数量还是很多。因此计算量还是很大。所以设计另一种方法,进一步减少模板样本点。