将数据中导演与演员的关系整理出来,得到导演与演员的关系数据,并统计合作次数
import numpy as np import pandas as pd import matplotlib.pyplot as plt % matplotlib inline import warnings warnings.filterwarnings('ignore') # 不发出警告
# 读取数据 import os # os.chdir('C:/Users/Hjx/Desktop/') os.chdir(r'C:UsersAdministratorDesktopch0304_data') df = pd.read_excel('豆瓣电影数据.xlsx',sheetname=0,header=0) print('数据总共%i条' % len(df)) print('数据字段为: ',df.columns.tolist()) df.head(2) # 查看数据

#数据清洗 data = df[['name', '导演', '主演']] data.dropna(inplace = True) data.head()
data_yy = data['主演'].str.split('/ ', expand=True) col_len1 = len(data_yy.columns) data_yy.columns = ['yy'+str(i) for i in range(col_len1)] data_yy.head()

data_dy = data['导演'].str.split('/ ', expand=True) col_len2 = len(data_dy.columns) data_dy.columns = ['dy'+str(i) for i in range(col_len2)] data_dy.head()
data2 = data_dy.join(data_yy).join(data['name']) data2.head()

#拆分+合并 data_re = pd.DataFrame(columns=['name','导演','演员']) # 创建一个空的Dataframe col_yy = data_yy.columns col_dy = data_dy.columns for dy in col_dy: for yy in col_yy: data_i = data2[['name', dy, yy]].dropna() # 提取数据 data_i.columns = ['name', '导演', '演员'] ## 列名重命名 # print(data_i) data_re = pd.concat([data_re, data_i]) # 添加数据 print(data_re.head())
# 遍历数据后,得到一个导演与演员的关系数据,并做去重处理
# 这里index是有重复的,但作为过程数据可忽略

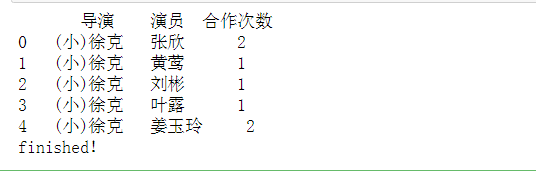
# 汇总统计导演和演员的合作次数 result = data_re.groupby(['导演','演员']).count() result.reset_index(inplace=True) result.columns = ['导演','演员','合作次数'] print(result.head()) # 按照导演-演员进行计数统计,得到结果数据 # reset_index() → 将所有索引级别转换为列 writer = pd.ExcelWriter('output.xlsx') result.to_excel(writer,'sheet1') writer.save() # 存为excel # 注意:output.xlsx文件不能是打开状态 print('finished!')