简介
Flink本身为了保证其高可用的特性,以及保证作用的Exactly Once的快速恢复,进而提供了一套强大的Checkpoint机制。
Checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保 证应用流图状态的一致性。Flink的Checkpoint机制原理来自“Chandy-Lamport algorithm”算法 (分布式快照算法)。
Checkpoint的执行流程
每个需要checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator,CheckpointCoordinator全权负责本应用的快照制作。
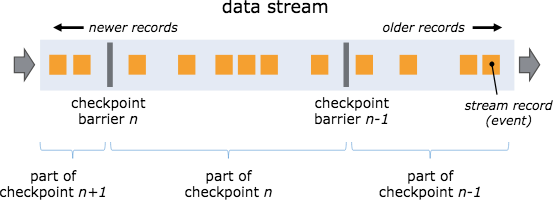
- CheckpointCoordinator周期性的向该流应用的所有source算子发送barrier;
- 当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状 态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告 自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理;
- 下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身 快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理;
- 每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
- 当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败 ;
Checkpoint常用设置
// start a checkpoint every 1000 ms
env.enableCheckpointing(1000);
// advanced options:
// set mode to exactly-once (this is the default)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// checkpoints have to complete within one minute, or are discarded
env.getCheckpointConfig().setCheckpointTimeout(60000);
// make sure 500 ms of progress happen between checkpoints
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// allow only one checkpoint to be in progress at the same time
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// enable externalized checkpoints which are retained after job cancellation
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// This determines if a task will be failed if an error occurs in the execution of the task’s checkpoint procedure.
env.getCheckpointConfig().setFailOnCheckpointingErrors(true);
- 使用StreamExecutionEnvironment.enableCheckpointing方法来设置开启checkpoint;具体可以使用enableCheckpointing(long interval),或者enableCheckpointing(long interval, CheckpointingMode mode);interval用于指定checkpoint的触发间隔(单位milliseconds),而CheckpointingMode默认是CheckpointingMode.EXACTLY_ONCE,也可以指定为CheckpointingMode.AT_LEAST_ONCE
- 也可以通过StreamExecutionEnvironment.getCheckpointConfig().setCheckpointingMode来设置CheckpointingMode,一般对于超低延迟的应用(大概几毫秒)可以使用CheckpointingMode.AT_LEAST_ONCE,其他大部分应用使用CheckpointingMode.EXACTLY_ONCE就可以
- checkpointTimeout用于指定checkpoint执行的超时时间(单位milliseconds),超时没完成就会被abort掉
- minPauseBetweenCheckpoints用于指定checkpoint coordinator上一个checkpoint完成之后最小等多久可以出发另一个checkpoint,当指定这个参数时,maxConcurrentCheckpoints的值为1
- maxConcurrentCheckpoints用于指定运行中的checkpoint最多可以有多少个,用于包装topology不会花太多的时间在checkpoints上面;如果有设置了minPauseBetweenCheckpoints,则maxConcurrentCheckpoints这个参数就不起作用了(大于1的值不起作用)
- enableExternalizedCheckpoints用于开启checkpoints的外部持久化,但是在job失败的时候不会自动清理,需要自己手工清理state;ExternalizedCheckpointCleanup用于指定当job canceled的时候externalized checkpoint该如何清理,DELETE_ON_CANCELLATION的话,在job canceled的时候会自动删除externalized state,但是如果是FAILED的状态则会保留;RETAIN_ON_CANCELLATION则在job canceled的时候会保留externalized checkpoint state
- failOnCheckpointingErrors用于指定在checkpoint发生异常的时候,是否应该fail该task,默认为true,如果设置为false,则task会拒绝checkpoint然后继续运行
flink-conf.yaml相关配置
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#
# state.backend: filesystem
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
# Default target directory for savepoints, optional.
#
# state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#
# state.backend.incremental: false
- state.backend用于指定checkpoint state存储的backend,默认为none
- state.backend.async用于指定backend是否使用异步snapshot(默认为true),有些不支持async或者只支持async的state backend可能会忽略这个参数
- state.backend.fs.memory-threshold,默认为1024,用于指定存储于files的state大小阈值,如果小于该值则会存储在root checkpoint metadata file
- state.backend.incremental,默认为false,用于指定是否采用增量checkpoint,有些不支持增量checkpoint的backend会忽略该配置
- state.backend.local-recovery,默认为false
- state.checkpoints.dir,默认为none,用于指定checkpoint的data files和meta data存储的目录,该目录必须对所有参与的TaskManagers及JobManagers可见
- state.checkpoints.num-retained,默认为1,用于指定保留的已完成的checkpoints个数
- state.savepoints.dir,默认为none,用于指定savepoints的默认目录
- taskmanager.state.local.root-dirs,默认为none
增量式的检查点- Checkpoint设置的奇技淫巧
增量式检查点
Flink的检查点是一个全局的、异步的程序快照,它周期性的生成并送到持久化存储(一般使用分布式系统)。当发生故障时,Flink使用最新的检查点进行重启。一些Flink的用户在程序“状态”中保存了GB甚至TB的数据。这些用户反馈在大量 的状态下,创建检查点通常很慢并且耗资源,这也是为什么Flink在 1.3版本开始引入“增量式的检查点”。
在引入“增量式的检查点”之前,每一个Flink的检查点都保存了程序完整的状态。后来我们意识到在大部分情况下这是不必要的,因为上一次和这次的检查点之前 ,状态发生了很大的变化,所以我们创建了“增量式的检查点”。增量式的检查点仅保存过去和现在状态的差异部分。
增量式的检查点可以为拥有大量状态的程序带来很大的提升。在早期的测试中,一个拥有TB级别“状态”程序将生成检查点的耗时从3分钟以上降低 到了30秒左右。因为增量式的检查点不需要每次把完整的状态发送到存储中。
现在只能通过RocksDB state back-end来获取增量式检查点的功能,Flink使用RocksDB内置的备份机制来合并检查点数据。这样Flink增量式检查点的数据不会无限制的增大,它会自动合并老的检查点数据并清理掉。
要启用这个机制,可以如下设置:
RocksDBStateBackend backend =
new RocksDBStateBackend(filebackend, true);
增量式检查点如何工作
Flink 增量式的检查点以“RocksDB”为基础,RocksDB是一个基于 LSM树的KV存储,新的数据保存在内存中,称为memtable。如果Key相同,后到的数据将覆盖之前的数据,一旦memtable写满了,RocksDB将数据压缩并写入到磁盘。memtable的数据持久化到磁盘后,他们就变成了不可变的sstable。
RocksDB会在后台执行compaction,合并sstable并删除其中重复的数据。之后RocksDB删除原来的sstable,替换成新合成的ssttable,这个sstable包含了之前的sstable中的信息。
在这个基础之上,Flink跟踪前一个checkpoint创建和删除的RocksDB sstable文件,因为sstable是不可变的,Flink可以因此计算出 状态有哪些改变。为了达到这个目标,Flink在RocksDB上触发了一个刷新操作,强制将memtable刷新到磁盘上。这个操作在Flink中是同步的,其他的操作是异步的,不会阻塞数据处理。
Flink 的checkpoint会将新的sstable发送到持久化存储(例如HDFS,S3)中,同时保留引用。Flink不会发送所有的sstable, 一些数据在之前的checkpoint存在并且写入到持久化存储中了,这样只需要增加引用次数就可以了。因为compaction的作用,一些sstable会合并成一个sstable并删除这些sstable,这也是为什么Flink可以减少checkpoint的历史文件。
为了分析checkpoint的数据变更,而上传整理过的sstable是多余的(这里的意思是之前已经上传过的,不需要再次上传)。Flink处理这种情况,仅带来一点点开销。这个过程很重要,因为在任务需要重启的时候,Flink只需要保留较少的历史文件。
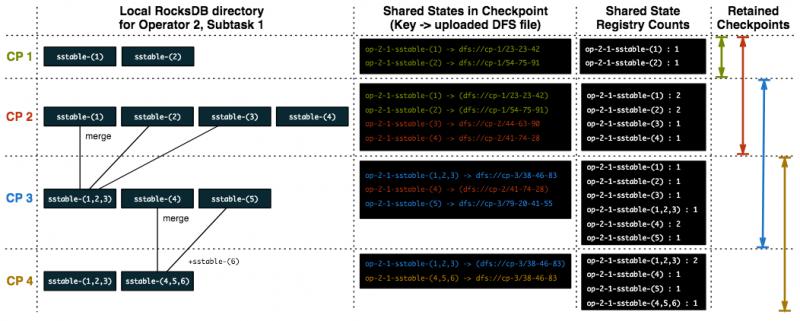
假设有一个子任务,拥有一个keyed state的operator,checkpoint最多保留2个。上面的图片描述了每个checkpoint对应的RocksDB 的状态,它引用到的文件,以及在checkpoint完成后共享状态中的count值。
checkpoint ‘CP2’,本地的RocksDB目录有两个sstable文件,这些文件是新生成的,于是Flink将它们传到了checkpoint 对应的存储目录。当checkpoint完成后,Flink在共享状态中创建两个实体,并将count设为1。在这个共享状态中,这个key 由operator、subtask,原始的sstable名字组成,value为sstable实际存储目录。
checkpoint‘CP2’,RocksDB有2个老的sstable文件,又创建了2个新的sstable文件。Flink将这两个新的sstable传到 持久化存储中,然后引用他们。当checkpoint完成后,Flink将所有的引用的相应计数加1。
checkpoint‘CP3’,RocksDB的compaction将sstable-(1), sstable-(2), sstable-(3) 合并成 sstable-(1,2,3),然后删除 原始的sstable。这个合并后的文件包含了和之前源文件一样的信息,并且清理掉了重复的部分。sstable-(4)还保留着,然后有一个 新生成的sstable-(5)。Flink将新的 sstable-(1,2,3)以及 sstable-(5)传到持久化存储中, sstable-(4)仍被‘CP2’引用,所以 将计数增加1。现在有了3个checkpoint,'CP1','CP2','CP3',超过了预设的保留数目2,所以CP1被删除。作为删除的一部分, CP1对应的文件(sstable-(1)、sstable-(2)) 的引用计数减1。
checkpoint‘CP4’,RocksDB将sstable-(4), sstable-(5), 新的 sstable-(6) 合并成 sstable-(4,5,6)。Flink将新合并 的 sstable-(4,5,6)发送到持久化存储中,sstable-(1,2,3)、sstable-(4,5,6) 的引用计数增加1。由于再次到达了checkpoint的 保留数目,‘CP2’将被删除,‘CP2’对应的文件(sstable-(1)、sstable-(2)、sstable(3) )的引用计数减1。由于‘CP2’对应 的文件的引用计数达到0,这些文件将被删除。
需要注意的地方
如果使用增量式的checkpoint,那么在错误恢复的时候,不需要考虑很多的配置项。一旦发生了错误,Flink的JobManager会告诉 task需要从最新的checkpoint中恢复,它可以是全量的或者是增量的。之后TaskManager从分布式系统中下载checkpoint文件, 然后从中恢复状态。
增量式的checkpoint能为拥有大量状态的程序带来较大的提升,但还有一些trade-off需要考虑。总的来说,增量式减少了checkpoint操作的时间,但是相对的,从checkpoint中恢复可能更耗时,具体情况需要根据应用程序包含的状态大小而定。相对的,如果程序只是部分失败,Flink TaskManager需要从多个checkpoint中读取数据,这时候使用全量的checkpoint来恢复数据可能更加耗时。同时,由于新的checkpoint可能引用到老的checkpoint,这样老的checkpoint就不能被删除,这样下去,历史的版本数据会越来越大。需要考虑使用分布式来存储checkpoint,另外还需要考虑读取带来的带宽消耗。
声明:本号所有文章除特殊注明,都为原创,公众号读者拥有优先阅读权,未经作者本人允许不得转载,否则追究侵权责任。
关注我的公众号,后台回复【JAVAPDF】获取200页面试题!
5万人关注的大数据成神之路,不来了解一下吗?
5万人关注的大数据成神之路,真的不来了解一下吗?
5万人关注的大数据成神之路,确定真的不来了解一下吗?
欢迎您关注《大数据成神之路》
备注:所有内容首发公众号,这里不保证实时性和完整性,大家扫描文末二维码关注哦~