原文链接:实现yolo3模型训练自己的数据集总结
经过两天的努力,借鉴网上众多博客,在自己电脑上实现了使用yolo3模型训练自己的数据集并进行测试图片。本文主要是我根据下面参考文章一步步实施过程的总结,可能没参考文章中那么详细,但是会包含一些参考文章中没提及的容易掉坑的小细节,建议读者结合参考文章一起看,一步步走即可。首先贴出本文主要参考的文章以及代码出处:
代码:https://github.com/qqwweee/keras-yolo3
参考文章:https://blog.csdn.net/patrick_Lxc/article/details/80615433
一.下载项目源码,进行快速测试
从上面代码链接处下载整个项目源码。下载好后,首先根据github中指引进行快速测试。
yolo web:https://pjreddie.com/darknet/yolo
对应操作如下(命令行操作):
1. wget https://pjreddie.com/media/files/yolov3.weights
注释:这里wget为linux命令,windows系统可以直接访问后面链接来下载yolov3权重文件,也可以访问yolo web去下载。
2. python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
注释:执行convert.py文件,此为将darknet的yolo转换为可以用于keras的h5文件,生成的h5被保存在model_data下。命令中的convert.py和yolov3.vfg克隆下来后已经有了,不需要单独下载。
3.用已经被训练好的yolo.h5进行图片识别测试。执行:python yolo.py
执行后会让你输入一张图片的路径,因为我准备的图片(网上随便找的)放在yolo.py同级目录,所以直接输入图片名称,没有加路径。
过程和结果如下图所示:
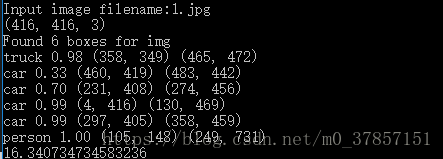

以上结果表明快速开始项目成功,接下来我们进行搭建自己的数据集,进行模型的训练以及训练后模型用于测试图片识别。
二.准备自己的数据集
可以按照上面参考文章里面做法下载VOC数据集,然后清空里面内容,保留文件目录结构。也可以直接手动创建如下目录结构:

这里面用到的文件夹是Annotation、ImageSets和JPEGImages。注意:需要在VOC2007再创建一个上级目录VOCdevkit。
其中文件夹Annotation中主要存放xml文件,每一个xml对应一张图像,并且每个xml中存放的是标记的各个目标的位置和类别信息,命名通常与对应的原始图像一样;而ImageSets我们只需要用到Main文件夹,这里面存放的是一些文本文件,通常为train.txt、test.txt等,该文本文件里面的内容是需要用来训练或测试的图像的名字;JPEGImages文件夹中放我们已按统一规则命名好的原始图像。
原始图片就不解释了,而与原始图片一 一对应的xml文件,可以使用LabelImg工具,具体使用方法百度即可。工具可以从参考的博客中的附带地址下载,也可以自己网上找,很容易。
将自己的图片以及xml按照要求放好后,在VOC2007的同级目录下建立convert_to_txt.py文件,拷贝下面的代码,然后运行该py文件。该代码是读取上面的xml文件中图片名称,并保存在ImageSets/Main目录下的txt文件中。注意:此处txt中仅有图片名称。
代码:
1 import os 2 import random 3 4 trainval_percent = 0.1 5 train_percent = 0.9 6 xmlfilepath = 'Annotations' 7 txtsavepath = 'ImageSetsMain' 8 total_xml = os.listdir(xmlfilepath) 9 10 num = len(total_xml) 11 list = range(num) 12 tv = int(num * trainval_percent) 13 tr = int(tv * train_percent) 14 trainval = random.sample(list, tv) 15 train = random.sample(trainval, tr) 16 17 ftrainval = open('ImageSets/Main/trainval.txt', 'w') 18 ftest = open('ImageSets/Main/test.txt', 'w') 19 ftrain = open('ImageSets/Main/train.txt', 'w') 20 fval = open('ImageSets/Main/val.txt', 'w') 21 22 for i in list: 23 name = total_xml[i][:-4] + ' ' 24 if i in trainval: 25 ftrainval.write(name) 26 if i in train: 27 ftest.write(name) 28 else: 29 fval.write(name) 30 else: 31 ftrain.write(name) 32 33 ftrainval.close() 34 ftrain.close() 35 fval.close() 36 ftest.close()
然后,回到从github上下载的源码所在目录,执行其中的voc_annotation.py,会在当前目录生成新的三个txt文件,手动去掉名称中2007_部分。当然,可以自己进入voc_annotation.py修改代码,使生成的txt文件名中不包含2007_。
注意:一开始VOC2007,也可以叫VOC2008之类,这样此处的txt就会成为2008_xxx.txt。此外,有一个很关键的地方需要注意,必须修改,不然此处生成的三个新的txt文件中仅仅比前面Main下的txt中多了图片路径而已,并不包含框box的信息,这样的话在后面的训练步骤,由于没有框的信息,仅仅是图片路径和名称信息,是训练不好的,即使可以得到训练后的h5文件,但是当用这样的h5文件去执行类似前面所说的测试图片识别,效果就是将整幅图框住,而不是框住你所要识别的部分。
故所要做的是:在执行voc_annotation.py之前,打开它,进行修改。将其中最上面的sets改为你自己的,比如2012改为我得2007,要和前面的目录年份保持一致。还需要将最上面的classes中的内容,改为你自己xml文件中object属性中name属性的值。你有哪些name值,就改为哪些,不然其中读取xml框信息的代码就不会执行。

上面是我的xml中一个object截图,这里的name实际上为你用LableIma工具画框时候给那个框的命名值。
至此,自己数据集的准备工作就完成了。
三.修改一些文件,然后执行训练
首先是修改model_data下的文件,放入你的类别,coco,voc这两个文件都需要修改。这里的命名会成为最终检测图片时候框的框上的名称。
其次是yolov3.cfg文件
这一步事后我和同学讨论了下,得出的结论是,从0开始训练自己的模型,则不需要下面的修改步骤,而如果想用迁移学习思想,用已经预训练好的权重接着训练,则需要下面的修改步骤。
DE里直接打开cfg文件,ctrl+f搜 yolo, 总共会搜出3个含有yolo的地方。
每个地方都要改3处,filters:3*(5+len(classes));
classes: len(classes) = 1,我只识别一种,所以为1
random:原来是1,显存小改为0
如果要用预训练的权重接着训练,则需要执行以下代码:然后执行原train.py就可以了。原train.py中有加载预训练权重的代码,并冻结部分层数,在此基础上进行训练。可以修改冻结层数。
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5
这个在github和参考的文章中均提到。
如果不用预训练的权重,上一步不用执行(执行也没影响),但是下面的train.py需要修改,改为如下所示(代码出处为上文提到的参考博客中):直接复制替换原train.py即可
1 """ 2 Retrain the YOLO model for your own dataset. 3 """ 4 import numpy as np 5 import keras.backend as K 6 from keras.layers import Input, Lambda 7 from keras.models import Model 8 from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping 9 10 from yolo3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss 11 from yolo3.utils import get_random_data 12 13 14 def _main(): 15 annotation_path = 'train.txt' 16 log_dir = 'logs/000/' 17 classes_path = 'model_data/voc_classes.txt' 18 anchors_path = 'model_data/yolo_anchors.txt' 19 class_names = get_classes(classes_path) 20 anchors = get_anchors(anchors_path) 21 input_shape = (416,416) # multiple of 32, hw 22 model = create_model(input_shape, anchors, len(class_names) ) 23 train(model, annotation_path, input_shape, anchors, len(class_names), log_dir=log_dir) 24 25 def train(model, annotation_path, input_shape, anchors, num_classes, log_dir='logs/'): 26 model.compile(optimizer='adam', loss={ 27 'yolo_loss': lambda y_true, y_pred: y_pred}) 28 logging = TensorBoard(log_dir=log_dir) 29 checkpoint = ModelCheckpoint(log_dir + "ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5", 30 monitor='val_loss', save_weights_only=True, save_best_only=True, period=1) 31 batch_size = 10 32 val_split = 0.1 33 with open(annotation_path) as f: 34 lines = f.readlines() 35 np.random.shuffle(lines) 36 num_val = int(len(lines)*val_split) 37 num_train = len(lines) - num_val 38 print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size)) 39 40 model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes), 41 steps_per_epoch=max(1, num_train//batch_size), 42 validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors, num_classes), 43 validation_steps=max(1, num_val//batch_size), 44 epochs=500, 45 initial_epoch=0) 46 model.save_weights(log_dir + 'trained_weights.h5') 47 48 def get_classes(classes_path): 49 with open(classes_path) as f: 50 class_names = f.readlines() 51 class_names = [c.strip() for c in class_names] 52 return class_names 53 54 def get_anchors(anchors_path): 55 with open(anchors_path) as f: 56 anchors = f.readline() 57 anchors = [float(x) for x in anchors.split(',')] 58 return np.array(anchors).reshape(-1, 2) 59 60 def create_model(input_shape, anchors, num_classes, load_pretrained=False, freeze_body=False, 61 weights_path='model_data/yolo_weights.h5'): 62 K.clear_session() # get a new session 63 image_input = Input(shape=(None, None, 3)) 64 h, w = input_shape 65 num_anchors = len(anchors) 66 y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], 67 num_anchors//3, num_classes+5)) for l in range(3)] 68 69 model_body = yolo_body(image_input, num_anchors//3, num_classes) 70 print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes)) 71 72 if load_pretrained: 73 model_body.load_weights(weights_path, by_name=True, skip_mismatch=True) 74 print('Load weights {}.'.format(weights_path)) 75 if freeze_body: 76 # Do not freeze 3 output layers. 77 num = len(model_body.layers)-3 78 for i in range(num): model_body.layers[i].trainable = False 79 print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers))) 80 81 model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss', 82 arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})( 83 [*model_body.output, *y_true]) 84 model = Model([model_body.input, *y_true], model_loss) 85 return model 86 def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes): 87 n = len(annotation_lines) 88 np.random.shuffle(annotation_lines) 89 i = 0 90 while True: 91 image_data = [] 92 box_data = [] 93 for b in range(batch_size): 94 i %= n 95 image, box = get_random_data(annotation_lines[i], input_shape, random=True) 96 image_data.append(image) 97 box_data.append(box) 98 i += 1 99 image_data = np.array(image_data) 100 box_data = np.array(box_data) 101 y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes) 102 yield [image_data, *y_true], np.zeros(batch_size) 103 104 def data_generator_wrap(annotation_lines, batch_size, input_shape, anchors, num_classes): 105 n = len(annotation_lines) 106 if n==0 or batch_size<=0: return None 107 return data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes) 108 109 if __name__ == '__main__': 110 _main()
我是在cpu版本tensorflow上跑的,故特别慢,有运算资源的就不说了,如果资源有限,建议少弄些图片和xml文件,这样最后的txt文件中数据就少,跑起来轻松点。其次可以修改train.py中的迭代次数epochs的值,该值原作者设置的为500;也可以修改batch_size = 10的大小。
注意:我第一次训练时候,确实在目录下自动生成了logs文件夹,并在其中生成000文件夹,然后里面放的是自己训练好的h5文件。但是后来我调试代码,删除该目录,再次训练时,报如下错误:

此时只需要手动创建logs文件夹和其内的000文件夹即可。嫌名字不好,可以自己修改train.py文件,改里面的保存目录。
下面为成功测试截图:

四.用自己训练的h5文件进行测试
先修改yolo.py文件中的模型路径,如下所示,改为自己训练后生成的h5文件路径。

然后执行,测试过程和前面所讲一样,因为我得没怎么训练,就不贴出很挫的测试效果图了。在最初没有框信息的txt文件训练后,执行测试很慢,因为训练时候根本不知道要框什么,改为正常txt后,训练后的模型进行测试,速度就会很快。