领域模型(domain model)是对领域内的概念类或现实世界中对象的可视化表示。领域模型也称为概念模型、领域对象模型和分析对象模型。
——《UML和模式应用》
我们在日常开发中,经常针对一些功能点争论“这个功能不应该我改,应该是你那边改”,最终被妥协改了之后都改不明白为什么这个功能要在自己这边改。区别于传统的架构设计,领域驱动设计(DDD)也许在这个时候能帮助你做到清晰的划分。
什么是DDD
领域驱动设计最初由Eric Evans提出,但是多年以来一直停留在理念阶段,真正能实现并且落地的项目和公司少之又少,而进来阿里内部其实在大力推行DDD的理念,它主要可以帮助我们解决传统单体式集中架构难以快速响应业务需求落地的问题,并且针对中台和微服务盛行的场景做出指导。
DDD为我们提供的是架构设计的方法论,既面向技术也面向业务,从业务的角度来把握设计方案。
DDD的作用

统一思想:统一项目各方业务、产品、开发对问题的认知,而不是开发和产品统一,业务又和产品统一从而产生分歧。
明确分工:域模型需要明确定义来解决方方面面的问题,而针对这些问题则形成了团队分钟的理解。
反映变化:需求是不断变化的,因此我们的模型也是在不断的变化的。领域模型则可以真实的反映这些变化。
边界分离:领域模型与数据模型分离,用领域模型来界定哪些需求在什么地方实现,保持结构清晰。
DDD的概念
实体
有唯一标志的核心领域对象,且这个标志在整个软件生命周期中都不会发生变化。这个概念和我们平时软件模型中和数据库打交道的Model实例比较接近,唯一不同的是DDD中这些实体会包含与该实体相关的业务逻辑,它是操作行为的载体。
值对象
依附于实体存在,通过对象属性来识别的对象,它将一些相关的实体属性打包在一起处理,形成一个新的对象。
举个栗子:比如用户实体,包含用户名、密码、年龄、地址,地址又包含省市区等属性,而将省市区这些属性打包成一个属性集合就是值对象。
聚合
实体和值对象表现的是个体的能力,而我们的业务逻辑往往很复杂,依赖个体是无法完成的,这时候就需要多个实体和值对象一起协同工作,而这个协同的组织就是聚合。聚合是数据修改和持久化的基本单元,同一个聚合内要保证事务的一致性,所以在设计的时候要保证聚合的设计拆分到最小化以保证效率和性能。
聚合根
也叫做根实体,一个特殊的实体,它是聚合的管理者,代表聚合的入口,抓住聚合根可以抓住整个聚合。
领域服务
有些领域的操作是一些动词,并不能简单的把他们归类到某个实体或者值对象中。这样的行为从领域中识别出来之后应该将它声明成一个服务,它的作用仅仅是为领域提供相应的功能。
领域事件
在特定的领域由用户动作触发,表示发生在过去的事件。比如充值成功、充值失败的事件。
四种模式
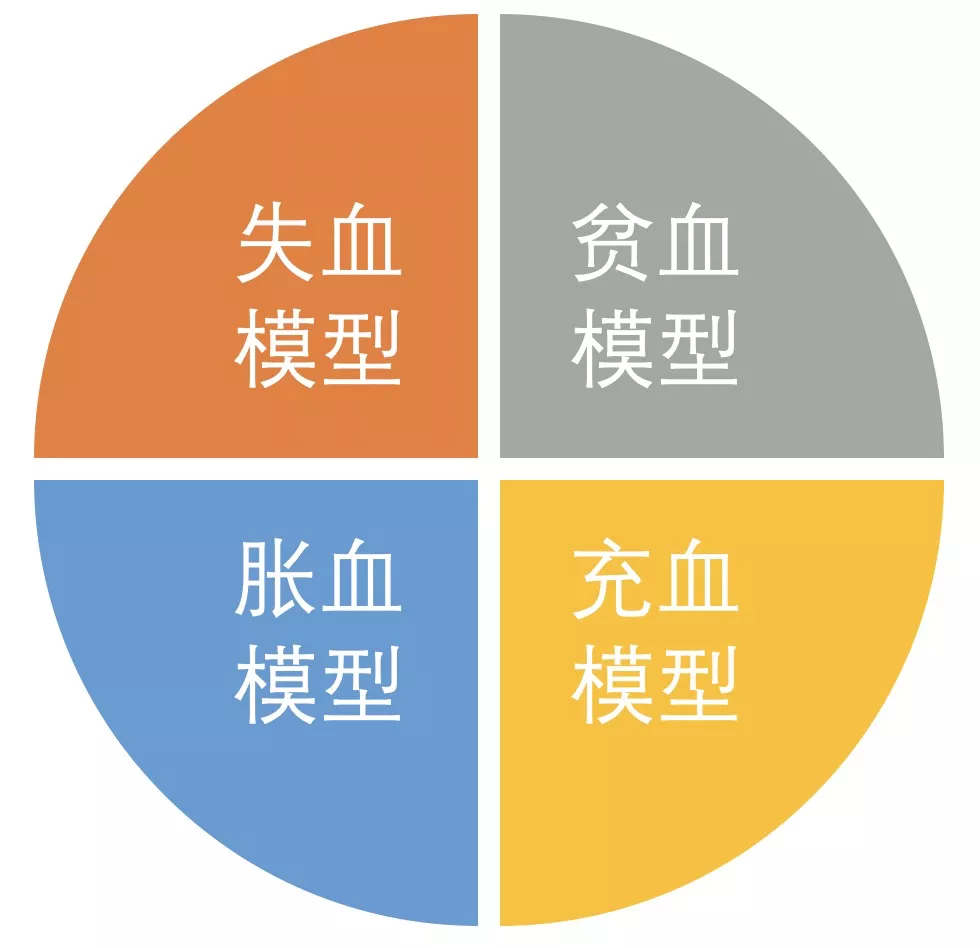
失血模型
模型中只有简单的get set方法,是对一个实体最简单的封装,其他所有的业务行为由服务类来完成。
@Data @ToString public class User { private Long id; private String username; private String password; private Integer status; private Date createdAt; private Date updatedAt; private Integer isDeleted; }
public class UserService{ public boolean isActive(User user){ return user.getStatus().equals(StatusEnum.ACTIVE.getCode()); } }
贫血模型
在失血模型基础之上聚合了业务领域行为,领域对象的状态变化停留在内存层面,不关心数据持久化。
@Data @ToString public class User { private Long id; private String username; private String password; private Integer status; private Date createdAt; private Date updatedAt; private Integer isDeleted; public boolean isActive(User user){ return user.getStatus().equals(StatusEnum.ACTIVE.getCode()); } public void setUsername(String username){ return username.trim(); } }
充血模型
在贫血模型基础上,负责数据的持久化。
@Data @ToString public class User { private Long id; private String username; private String password; private Integer status; private Date createdAt; private Date updatedAt; private Integer isDeleted; private UserRepository userRepository; public boolean isActive(User user){ return user.getStatus().equals(StatusEnum.ACTIVE.getCode()); } public void setUsername(String username){ this.username = username.trim(); userRepository.update(user); } }
胀血模型
service都不需要,所有的业务逻辑、数据存储都放到一个类中。
对于DDD来说,失血和胀血都是不合适的,失血太轻量没有聚合,胀血那是初学者才这样写代码。那么充血模型和贫血模型该怎么选择?充血模型依赖repository接口,与数据存储紧密相关,有破坏程序稳定性的风险。
建模方法

用例分析法
用例分析法是领域建模最简单可行的方式。大致可以分为获取用例、收集实体、添加关联、添加属性、模型精化几个步骤。
-
获取用例:提取领域规则描述
-
收集实体:定位实体,
-
添加关联:两个实体间用动词关联起来
-
添加属性:获取实体属性
-
模型精化:可选的步骤,可以用UML的泛华和组合来表达模型间的关系,同时可以做子领域的划分
四色建模法
四色建模法源于《Java Modeling In Color With UML》,它是一种模型的分析和设计方法,通过把所有模型分为四种类型,帮助模型做到清晰、可追溯。
简单来说,四色关注的是某个人的角色在某个地点的角色用某个东西的角色做了某件事情。

事件风暴法
事件风暴法类似头脑风暴,简单来说就是谁在何时基于什么做了什么,产生了什么,影响了什么事情。

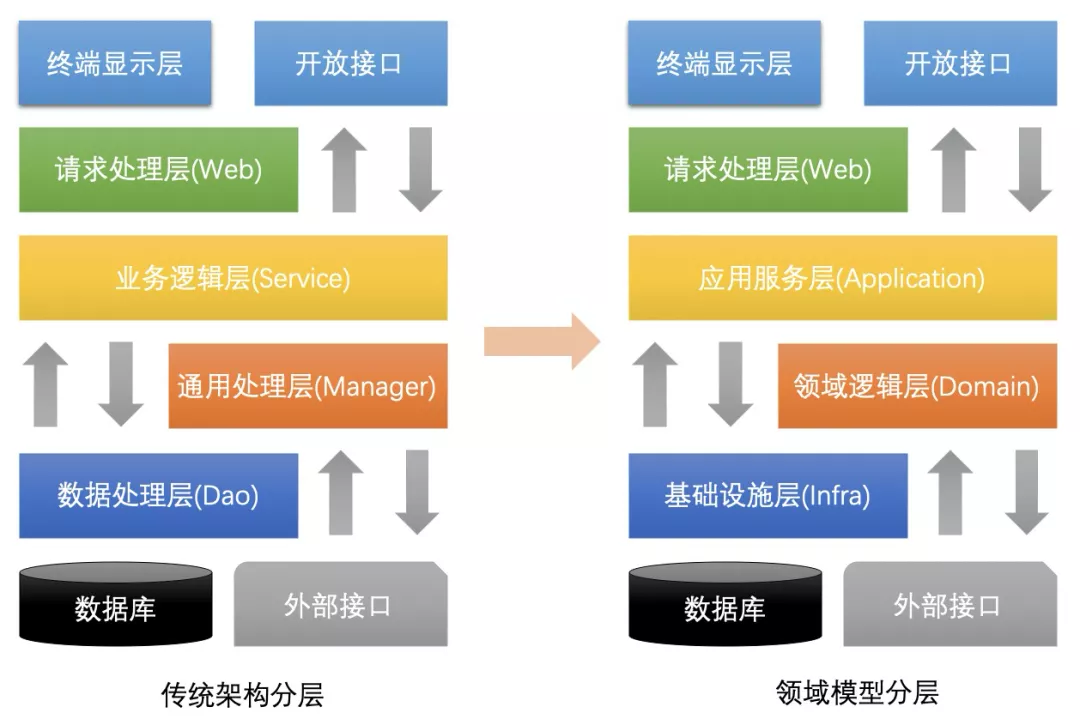
架构分层
区别于左图传统架构的分层,一般DDD分层会有一些变化。
Application:包含事件注册、业务逻辑等
Domain:聚合、实体、值对象
InfraStructure:基础设施封装、数据库访问等
总结
DDD是一套完善的方法论,他能帮助我们合理的对系统进行架构设计,同时,好的模板应该是在不断的适应变化,而DDD也能帮助我们更快速更方便的支撑业务的发展。