同理,马尔可夫图像可用于代码的分类,数据集使用的是GCJ数据集,(https://github.com/Jur1cek/gcj-dataset)。分别选取代码数靠前的5类,30类和500类作者的代码用于分类。
代码提取
先汇总所有年份的数据集,结合起来,统计代码数,选取数量靠前的作者,每一个作者相应代码存入一个文件夹。代码如下
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from tensorflow.keras.preprocessing.text import Tokenizer
import tensorflow.keras.preprocessing.text as T
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
import numpy as np
data_2008 = pd.read_csv("D:\dataset\GCI\gcj2008.csv\gcj2008.csv")
data_2009 = pd.read_csv("D:\dataset\GCI\gcj2009.csv\gcj2009.csv")
data_2010 = pd.read_csv("D:\dataset\GCI\gcj2010.csv\gcj2010.csv")
data_2012 = pd.read_csv("D:\dataset\GCI\gcj2012.csv\gcj2012.csv")
data_2013 = pd.read_csv("D:\dataset\GCI\gcj2013.csv\gcj2013.csv")
data_2014 = pd.read_csv("D:\dataset\GCI\gcj2014.csv\gcj2014.csv")
data_2015 = pd.read_csv("D:\dataset\GCI\gcj2015.csv\gcj2015.csv")
data_2016 = pd.read_csv("D:\dataset\GCI\gcj2016.csv\gcj2016.csv")
data_2017 = pd.read_csv("D:\dataset\GCI\gcj2017.csv\gcj2017.csv")
data_2018 = pd.read_csv("D:\dataset\GCI\gcj2018.csv\gcj2018.csv")
data_2019 = pd.read_csv("D:\dataset\GCI\gcj2019.csv\gcj2019.csv")
data_2020 = pd.read_csv("D:\dataset\GCI\gcj2020.csv\gcj2020.csv")
data = pd.concat([data_2008,data_2009,data_2010,data_2012,data_2013,data_2014,data_2015,data_2016,data_2017,data_2018,data_2019,data_2020],axis=0,ignore_index=True)
name_list = aa[0:500].index #选取前500
print(name_list)
value_list = aa[0:500].values
print(value_list)
#提取代码进相应的文件夹
base_save_code_dir = "D:\dataset\GCI\code_500\code"
count = 0
for name in name_list:
sub_data = data[data['username']==name]
sub_data.reset_index(drop=True)
save_dir = os.path.join(base_save_code_dir,str(count))
count+=1
print(count)
if not os.path.exists(save_dir):
os.mkdir(save_dir)
for i in range(sub_data.shape[0]):
code = sub_data.iloc[i,:]['flines']
fname = str(i)+".txt"
to_file = os.path.join(save_dir,fname)
file = open(to_file,'w+')
try:
file.write(code)
file.close()
except:
file.close()
os.remove(to_file)
print("error")
图像处理
将代码处理为马尔可夫图像,保存为数组形式
import PIL.Image as Image, os, sys, array, math
import numpy as np
base_sorce_dir = "D:\dataset\GCI\code_500\code"
def file2arr(file_path,file_save_path):
fileobj = open(file_path, mode = 'rb')
buffer = array.array('B', fileobj.read())
array1 = np.zeros((256,256), dtype=np.int)
for i in range(len(buffer)-2):
j = i+1
array1[buffer[i]][buffer[j]] += 1
trun_array = np.zeros(256,dtype=np.int)
for i in range(256):
for j in range(256):
trun_array[i] += array1[i][j]
array2 = np.zeros((256,256),dtype=np.float)
for i in range(256):
for j in range(256):
if(trun_array[i]!=0):
array2[i][j] = array1[i][j]/trun_array[i]
np.save(file_save_path,array2)
sorce_list = [os.path.join(base_sorce_dir,str(i)) for i in range(500)]
print(sorce_list)
to_base_dir = "D:\dataset\GCI\code_500\image"
to_list = [os.path.join(to_base_dir,str(i)) for i in range(500)]
print(to_list)
for i in range(500):
count = 1
for file in os.listdir(sorce_list[i]):
print ("counting the {0} file...".format(str(count)))
count+=1
apk_dir = os.path.join(sorce_list[i],file)
#创建图像存放文件夹
if not os.path.exists(to_list[i]):
os.mkdir(to_list[i])
apk_save_dir = os.path.join(to_list[i],file)
file2arr(apk_dir, apk_save_dir)
训练
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
import sys
import cv2
from tensorflow.keras import regularizers
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Activation,Flatten
from tensorflow.keras.layers import Conv2D,MaxPooling2D,BatchNormalization
from tensorflow.keras.optimizers import SGD,Adam,RMSprop
from tensorflow.keras.callbacks import TensorBoard
import sys
from sklearn.datasets import load_digits # 加载手写数字识别数据
import pylab as pl
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler # 标准化工具
from sklearn.svm import LinearSVC
from sklearn.metrics import classification_report # 预测结果分析工具
from tensorflow import keras
%matplotlib inline
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import optimizers
#数据准备
to_base_dir = "D:\dataset\GCI\code_500\image"
to_list = [os.path.join(to_base_dir,str(i)) for i in range(500)]
data = []
labels = []
count = 0
for to_dir in to_list:
print (to_dir)
for file in os.listdir(to_dir):
output = np.load(os.path.join(to_dir,file))
output2 = keras.preprocessing.image.img_to_array(output)
# output2 = np.expand_dims(output, axis=2) #扩维
# output2 = np.concatenate((output2, output2, output2), axis=-1)
data.append(output2)
labels.append(count)
count+=1
data_array = np.array(data)
labels = np.array(labels)
data = [] #释放数组,否则内存不够
#打乱数据
import numpy as np
index = np.random.permutation(len(labels))
labels = labels[index]
data_array = data_array[index]
#网络模型
from tensorflow.keras.layers import Convolution2D, MaxPooling2D, Flatten, Dropout, Dense, Activation
from tensorflow.keras.optimizers import Adam
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(256, 256, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(500, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
history = model.fit(data_array, labels, batch_size=64, epochs=50, validation_split=0.2)
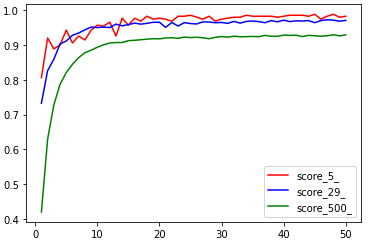
分类结果
马尔可夫图像5分类结果
[0.8062678, 0.92022794, 0.8888889, 0.9002849, 0.9430199, 0.9059829, 0.9259259, 0.9145299, 0.9430199, 0.95726496, 0.954416, 0.96581197, 0.9259259, 0.97720796, 0.95726496, 0.97720796, 0.96866095, 0.982906, 0.974359, 0.97720796, 0.974359, 0.96866095, 0.982906, 0.982906, 0.98575497, 0.980057, 0.974359, 0.982906, 0.96866095, 0.974359, 0.97720796, 0.980057, 0.980057, 0.98575497, 0.982906, 0.982906, 0.982906, 0.982906, 0.980057, 0.982906, 0.98575497, 0.98575497, 0.98575497, 0.982906, 0.988604, 0.974359, 0.982906, 0.988604, 0.980057, 0.982906]
马尔可夫图像29分类结果
[0.73260736, 0.82637626, 0.85904413, 0.9032063, 0.91167575, 0.9280097, 0.93466425, 0.94373864, 0.9516032, 0.9503932, 0.9516032, 0.9503932, 0.9600726, 0.9552329, 0.95886266, 0.9630974, 0.9600726, 0.96249247, 0.9655172, 0.9655172, 0.9509982, 0.9649123, 0.95462793, 0.9643073, 0.9618875, 0.96067756, 0.96672714, 0.9661222, 0.9643073, 0.9649123, 0.96249247, 0.9679371, 0.9630974, 0.9679371, 0.969147, 0.9673321, 0.9643073, 0.97035694, 0.96672714, 0.97156686, 0.9673321, 0.96975195, 0.969147, 0.97035694, 0.9643073, 0.97035694, 0.9727768, 0.97156686, 0.96854204, 0.97096187]
马尔可夫图像500分类结果
[0.41994056, 0.62947065, 0.7276879, 0.7870034, 0.820898, 0.8446682, 0.8637614, 0.87801254, 0.8850556, 0.8936943, 0.90062726, 0.9058545, 0.90717506, 0.9072301, 0.9125674, 0.91361284, 0.9153186, 0.91685927, 0.9182348, 0.91784966, 0.92021567, 0.92126113, 0.9193353, 0.9228568, 0.92148125, 0.9224166, 0.92087597, 0.9182348, 0.92219657, 0.92445254, 0.92269176, 0.9253329, 0.9239023, 0.9242324, 0.92478263, 0.9240123, 0.9276989, 0.9253329, 0.9251128, 0.92868936, 0.9277539, 0.9283042, 0.92434245, 0.9277539, 0.92681855, 0.9251678, 0.92665344, 0.92967975, 0.92637837, 0.9293496]
结果图如下: