需求:
客户通过 sftp 上传了一个 poc测试的 excel文件, 下到 云桌面 查看,发现一堆格式问题, 怎么办呢? 公司又不允许 吧文件下载到本地处理, 只能在 服务器上进行处理。
一堆的类型需要转换, 时间格式也是错误的,想想 可以借助 python 来做处理, 转成 csv格式,都转成 string 格式,接口也符合。
说罢,就这么干。 因为没怎么写过 python, 内心还是 恐惧的。
找了一个 解析 excel 的demo, 找个 改了改,以前处理excel 文件,打印字段测试是可以的,
问题1、这次 放到 服务器上运行 居然 读取第一个 单元格的字段就报 编码问题。

知道是编码问题,但是不知道why(以前在本地也处理过文件,没有问题。) 咨询了以前python 大神, 让我 encode(‘utf-8') 试试。

再执行成功了。 虽然还是不知道why ,文件本身就是 设置为 utf8 的编码。(还没去深究!!!!!)
2、内容转成 csv文件后,发现 顺序 不符合要求,想了一下,也想不出什么高端的方法,只得用最low的方法
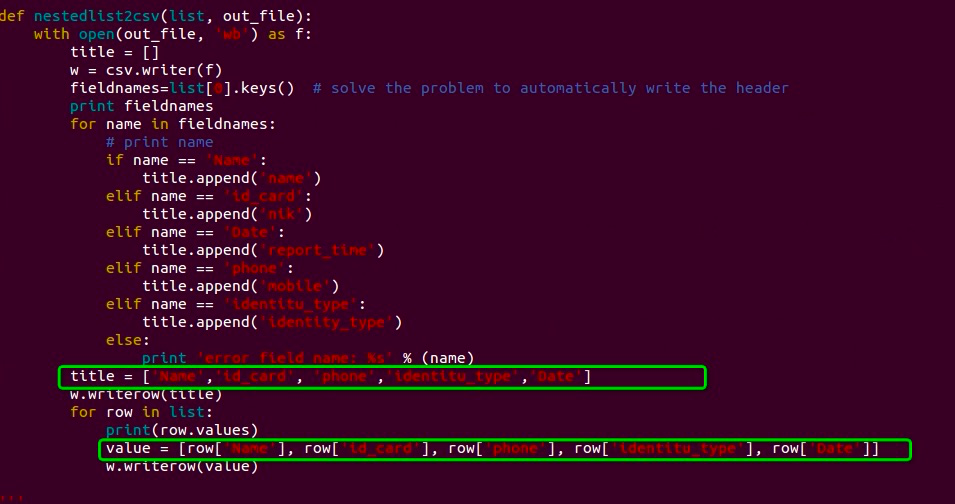
庆幸的是处理的 内容还是比较少。不存在性能之说。
问题3: 字符串中有 表情符,没处理成功【网上找了几个 demo 都测试 不通过,就先不管了,直接先存库了】

总结:
在用python 处理 格式过程中,感觉也不是很难,难点是不知道可以用 哪些 包 可以处理,一些基本的 语法问题。 只是文本处理的话,还是不难的。
主要代码如下:(别笑,我只是个python小白)
''' 读 excel文件 ''' def read_from_excel(filepath): data = xlrd.open_workbook(filepath) table = data.sheets()[0] nor = table.nrows nol = table.ncols print 'row: %d , colume: %d' % (nor, nol) resutl = [] for i in range(1, nor): dict = {} flag = True # if i == 10: # break for j in range(nol): title = table.cell_value(0, j).encode('utf-8') print(str(i) + '--' + str(j) + '---'+ title) #print(chardet.detect(table.cell_value(i, j))) value = (str(table.cell_value(i, j).encode('utf-8')).replace(' ', '')) print(str(i) + '--' + str(j) + '---'+value) # print value if title == 'identitu_type': if value == 'SSS': value = 'SSS card' elif value == 'PASSPORT': value = 'Passport' elif value == 'DRIVERLICENCE': value = "Driver's license" elif value == 'PHILHEALTH': value = "PhilHealth" elif value == 'UMID': value = "UMID" else: flag = False print(str(i) + '--' + str(j) + '---'+value) dict[title] = remove_emoji(value) if flag: resutl.append(dict) return resutl
''' 字典转 csv文件 ''' def nestedlist2csv(list, out_file): with open(out_file, 'wb') as f: title = [] w = csv.writer(f) fieldnames=list[0].keys() # solve the problem to automatically write the header print fieldnames title = ['Name','id_card', 'phone','identitu_type','Date'] w.writerow(title) for row in list: print(row.values) value = [row['Name'], row['id_card'], row['phone'], row['identitu_type'], row['Date']] w.writerow(value)