有一个单向链表,链表当中有可能出现“环”。如何用程序判断出这个链表是有环链表?
方法一:首先从头节点开始,依次遍历单链表的每一个节点。每遍历到一个新节点,就从头节点重新遍历新节点之前的所有节点,用新节点ID和此节点之前所有节点ID依次作比较。如果发现新节点之前的所有节点当中存在相同节点ID,则说明该节点被遍历过两次,链表有环;如果之前的所有节点当中不存在相同的节点,就继续遍历下一个新节点,继续重复刚才的操作。
例如这样的链表:A->B->C->D->B->C->D, 当遍历到节点D的时候,我们需要比较的是之前的节点A、B、C,不存在相同节点。这时候要遍历的下一个新节点是B,B之前的节点A、B、C、D中恰好也存在B,因此B出现了两次,判断出链表有环。
方法二:首先创建一个以节点ID为键的HashSet集合,用来存储曾经遍历过的节点。然后同样是从头节点开始,依次遍历单链表的每一个节点。每遍历到一个新节点,就用新节点和HashSet集合当中存储的节点作比较,如果发现HashSet当中存在相同节点ID,则说明链表有环,如果HashSet当中不存在相同的节点ID,就把这个新节点ID存入HashSet,之后进入下一节点,继续重复刚才的操作。
这个方法在流程上和方法一类似,本质的区别是使用了HashSet作为额外的缓存。
方法三:首先创建两个指针1和2(在java里就是两个对象引用),同时指向这个链表的头节点。然后开始一个大循环,在循环体中,让指针1每次向下移动一个节点,让指针2每次向下移动两个节点,然后比较两个指针指向的节点是否相同。如果相同,则判断出链表有环,如果不同,则继续下一次循环。
1 import java.util.HashMap; 2 public class LoopLink { 3 //内部静态类定义结点类 4 static class Node{ 5 int val; 6 Node next; 7 public Node(int val){ 8 this.val = val; 9 } 10 } 11 /* 12 * 首先从头节点开始,依次遍历单链表的每一个节点。 13 * 每遍历到一个新节点,就从头节点重新遍历新节点之前的所有节点,用新节点ID和此节点之前所有节点ID依次作比较。 14 * 如果发现新节点之前的所有节点当中存在相同节点ID,则说明该节点被遍历过两次,链表有环;如果之前的所有节点当中不存在相同的节点,就继续遍历下一个新节点,继续重复刚才的操作。 15 */ 16 public static boolean hasLoop1(Node head){ 17 Node p1 = head; 18 int length=0; 19 while(p1!=null&& p1.next != null) 20 { 21 int temp=0; 22 Node p2 = head; 23 while(p2!=null&&p2.next!=null&&p2!=p1) 24 { 25 p2=p2.next; 26 temp++; 27 } 28 if(temp!=length) 29 { 30 return true; 31 } 32 length++; 33 p1 = p1.next; 34 } 35 return false; 36 } 37 /* 38 *首先创建一个以节点ID为键的HashSet集合,用来存储曾经遍历过的节点。 39 *然后同样是从头节点开始,依次遍历单链表的每一个节点。 40 *每遍历到一个新节点,就用新节点和HashSet集合当中存储的节点作比较,如果发现HashSet当中存在相同节点ID,则说明链表有环, 41 *如果HashSet当中不存在相同的节点ID,就把这个新节点ID存入HashSet,之后进入下一节点,继续重复刚才的操作。 42 */ 43 public static boolean hasLoop2(Node head){ 44 Node temp1 = head; 45 HashMap<Node,Node> ns = new HashMap<Node,Node>(); 46 while(head!=null){ 47 if(ns.get(temp1)!=null)return true; 48 else ns.put(temp1, temp1); 49 temp1 = temp1.next; 50 if(temp1 == null)return false; 51 } 52 return true; 53 } 54 /* 55 * 首先创建两个指针1和2(在java里就是两个对象引用),同时指向这个链表的头节点。 56 * 然后开始一个大循环,在循环体中,让指针1每次向下移动一个节点,让指针2每次向下移动两个节点,然后比较两个指针指向的节点是否相同。 57 * 如果相同,则判断出链表有环,如果不同,则继续下一次循环。 58 */ 59 //判断单链表是否有环的方法 60 public static boolean hasLoop3(Node head){ 61 Node p1 = head; //定义一个引用指向头结点 62 Node p2 = head.next; //定义另一个引用指向头结点的下一个结点 63 64 /** 65 * 因为引用p2要比p1走的快,所以要用它作为循环的结束标志,为了防止当链表中个数为 66 * 偶数时出现p2.next=null空指针异常,这时可以在循环中进行一下判断,如果这种情况 67 * 出现一定是无环的。 68 */ 69 while(p2 != null && p2.next != null){ 70 p1 = p1.next; 71 p2 = p2.next.next; 72 if(p2 == null) 73 return false; 74 //为了防止p2.val出现空指针异常,需要对p2进行判断 75 int val1 = p1.val; 76 int val2 = p2.val; 77 if(val1 == val2) 78 return true; 79 } 80 return false; 81 } 82 public static void main(String[] args) { 83 Node n1 = new Node(1); 84 Node n2 = new Node(3); 85 Node n3 = new Node(6); 86 Node n4 = new Node(4); 87 Node n5 = new Node(5); 88 Node n6 = new Node(10); 89 n1.next = n2; 90 n2.next = n3; 91 n3.next = n4; 92 n4.next = n5; 93 n5.next = n6; 94 n6.next = n5; 95 System.out.println(hasLoop1(n1)); 96 System.out.println(hasLoop2(n1)); 97 System.out.println(hasLoop3(n1)); 98 } 99 }
下面说说如何找到环的入节点
遍历和哈希就不多说了后面直接上代码
现在说说第三种方法,即赛跑法
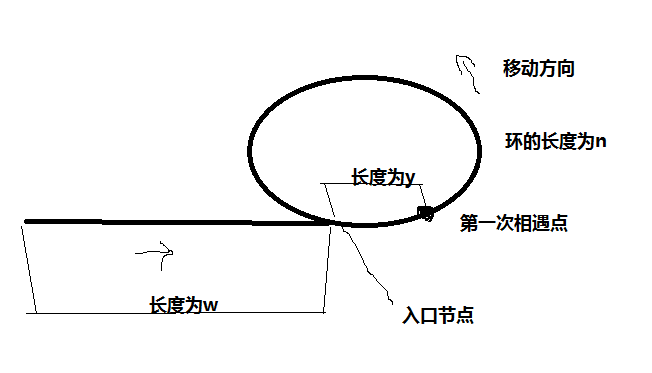
根据上图,我们可以得到下面的关系式:
- w + n + y = 2 (w + y)
如果是相遇的时候,p2已经走了很多圈了,思路也是一样的,只是这时的w会更长一点,并且我们可以肯定的是p1肯定不会绕着圈走一圈,即p1只在环上走了y的距离:
- w + y + kn = 2 (w + y)
同样,我们可以推到出来, kn - y = w。
1 import java.util.HashMap; 2 3 4 public class LoopNodeFind { 5 //找到环的起点 6 //内部静态类定义结点类 7 static class Node{ 8 int val; 9 Node next; 10 public Node(int val){ 11 this.val = val; 12 } 13 } 14 /* 15 * 首先从头节点开始,依次遍历单链表的每一个节点。 16 * 每遍历到一个新节点,就从头节点重新遍历新节点之前的所有节点,用新节点ID和此节点之前所有节点ID依次作比较。 17 * 如果发现新节点之前的所有节点当中存在相同节点ID,则说明该节点被遍历过两次,链表有环,且该节点为入口点; 18 * 如果之前的所有节点当中不存在相同的节点,就继续遍历下一个新节点,继续重复刚才的操作。 19 */ 20 public static int findNode1(Node head) 21 { 22 Node p1 = head; 23 int length=0; 24 while(p1!=null&& p1.next != null) 25 { 26 int temp=0; 27 Node p2 = head; 28 while(p2!=null&&p2.next!=null&&p2!=p1) 29 { 30 p2=p2.next; 31 temp++; 32 } 33 if(temp!=length) 34 { 35 return p1.val; 36 } 37 length++; 38 p1 = p1.next; 39 } 40 return 0; 41 } 42 /* 43 *首先创建一个以节点ID为键的HashSet集合,用来存储曾经遍历过的节点。 44 *然后同样是从头节点开始,依次遍历单链表的每一个节点。 45 *每遍历到一个新节点,就用新节点和HashSet集合当中存储的节点作比较,如果发现HashSet当中存在相同节点ID,则说明链表有环,且该节点为入口点, 46 *如果HashSet当中不存在相同的节点ID,就把这个新节点ID存入HashSet,之后进入下一节点,继续重复刚才的操作。 47 */ 48 public static int findNode2(Node head){ 49 Node temp1 = head; 50 HashMap<Node,Node> ns = new HashMap<Node,Node>(); 51 while(head!=null){ 52 if(ns.get(temp1)!=null) 53 { 54 return temp1.val; 55 } 56 else 57 { 58 ns.put(temp1, temp1); 59 } 60 temp1 = temp1.next; 61 if(temp1 == null) 62 return 0; 63 } 64 return 0; 65 } 66 67 /* 68 * 首先创建两个指针1和2(在java里就是两个对象引用),同时指向这个链表的头节点。 69 * 然后开始一个大循环,在循环体中,让指针1每次向下移动一个节点,让指针2每次向下移动两个节点,然后比较两个指针指向的节点是否相同。 70 * 如果相同,则判断出链表有环,如果不同,则继续下一次循环。 71 * 相同后,把p2放在头部,两者同速运动,则相遇点一定是环的起点 72 * 73 */ 74 public static int findNode3(Node pHead) 75 { 76 if(pHead==null||pHead.next==null) 77 { 78 return 0; 79 } 80 Node p1=pHead; 81 Node p2=pHead; 82 while(p2!=null&&p2.next!=null) 83 { 84 p1=p1.next; 85 p2=p2.next.next; 86 if(p1==p2) 87 { 88 p1=pHead; 89 while(p1!=p2) 90 { 91 p1=p1.next; 92 p2=p2.next; 93 } 94 if(p1==p2) 95 { 96 return p1.val; 97 } 98 99 } 100 } 101 return 0; 102 } 103 104 public static void main(String[] args) { 105 Node n1 = new Node(1); 106 Node n2 = new Node(2); 107 Node n3 = new Node(3); 108 Node n4 = new Node(4); 109 Node n5 = new Node(5); 110 Node n6 = new Node(6); 111 n1.next = n2; 112 n2.next = n3; 113 n3.next = n4; 114 n4.next = n5; 115 n5.next = n6; 116 n6.next = n5; 117 System.out.println(findNode1(n1)); 118 System.out.println(findNode2(n1)); 119 System.out.println(findNode3(n1)); 120 } 121 }
思路:
1、直接法
采用暴力的方法,遍历两个链表,判断第一个链表的每个结点是否在第二个链表中,时间复杂度为O(len1*len2),耗时很大。
2、hash计数法
如果两个链表相交,则两个链表就会有共同的结点;而结点地址又是结点唯一标识。因而判断两个链表中是否存在地址一致的节点,就可以知道是否相交了。可以对第一 个链表的节点地址进行hash排序,建立hash表,然后针对第二个链表的每个节点的地址查询hash表,如果它在hash表中出现,则说明两个链表有共 同的结点。这个方法的时间复杂度为:O(max(len1+len2);但同时还得增加O(len1)的存储空间存储哈希表。这样减少了时间复杂度,增加 了存储空间。以链表节点地址为值,遍历第一个链表,使用Hash保存所有节点地址值,结束条件为到最后一个节点(无环)或Hash中该地址值已经存在(有环)。
再遍历第二个链表,判断节点地址值是否已经存在于上面创建的Hash表中。
这个方面可以解决题目中的所有情况,时间复杂度为O(m+n),m和n分别是两个链表中节点数量。由于节点地址指针就是一个整型,假设链表都是在堆中动态创建的,可以使用堆的起始地址作为偏移量,以地址减去这个偏移量作为Hash函数
3、第三种思路是比较奇特的,在编程之美上看到的。先遍历第一个链表到他的尾部,然后将尾部的next指针指向第二个链表(尾部指针的next本来指向的是null)。这样两个链表就合成了一个链表,判断原来的两个链表是否相交也就转变成了判断新的链表是否有环的问题了:即判断单链表是否有环?这样进行转换后就可以从链表头部进行判断了,其实并不用。通过简单的了解我们就很容易知道,如果新链表是有环的,那么原来第二个链表的头部一定在环上。因此我们就可以从第二个链表的头部进行遍历的,从而减少了时间复杂度(减少的时间复杂度是第一个链表的长度)。
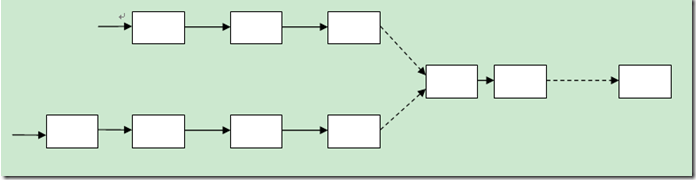
4.仔细研究两个链表,如果他们相交的话,那么他们最后的一个节点一定是相同的,否则是不相交的。因此判断两个链表是否相交就很简单了,分别遍历到两个链表的尾部,然后判断他们是否相同,如果相同,则相交;否则不相交。示意图如下:
1 import java.util.HashMap; 2 3 import javax.xml.transform.Templates; 4 5 6 7 //判断两个无环链表是否相交如果相交找到交点 8 public class LoopNoHoopIntersection { 9 //内部静态类定义结点类 10 static class Node{ 11 int val; 12 Node next; 13 public Node(int val){ 14 this.val = val; 15 } 16 } 17 /* 18 * 直接法 19 * 采用暴力的方法,遍历两个链表,判断第一个链表的每个结点是否在第二个链表中,时间复杂度为O(len1*len2),耗时很大。 20 */ 21 public static int judgeAndFind1(Node head1,Node head2) 22 { 23 while(head1!=null) 24 { 25 Node temp = head2; 26 while(temp!=null) 27 { 28 if(head1==temp) 29 { 30 return head1.val; 31 } 32 else { 33 temp = temp.next; 34 } 35 } 36 head1 = head1.next; 37 } 38 return 0; 39 } 40 /* 41 * hash计数法 42 * 如果两个链表相交,则两个链表就会有共同的结点; 43 * 而结点地址又是结点唯一标识。因而判断两个链表中是否存在地址一致的节点,就可以知道是否相交了。 44 * 可以对第一个链表的节点地址进行hash排序,建立hash表,然后针对第二个链表的每个节点的地址查询hash表,如果它在hash表中出现,则说明两个链表有共 同的结点。 45 * 这个方法的时间复杂度为:O(max(len1+len2);但同时还得增加O(len1)的存储空间存储哈希表。这样减少了时间复杂度,增加 了存储空间。 46 */ 47 public static int judgeAndFind2(Node head1,Node head2) 48 { 49 Node temp1 = head1; 50 HashMap<Node,Node> ns = new HashMap<Node,Node>(); 51 while(temp1!=null) 52 { 53 ns.put(temp1, temp1); 54 temp1 = temp1.next; 55 } 56 while(head2!=null) 57 { 58 if(ns.get(head2)!=null) 59 { 60 return head2.val; 61 } 62 head2 = head2.next; 63 } 64 return 0; 65 } 66 /* 67 * 仔细研究两个链表,如果他们相交的话,那么他们最后的一个节点一定是相同的,否则是不相交的。 68 * 因此判断两个链表是否相交就很简单了,分别遍历到两个链表的尾部,然后判断他们是否相同,如果相同,则相交;否则不相交 69 * 判断出两个链表相交后就是判断他们的交点了。假设第一个链表长度为len1,第二个问len2,然后找出长度较长的,让长度较长的链表指针向后移动|len1 - len2| (len1-len2的绝对值), 70 * 然后在开始遍历两个链表,判断节点是否相同即可。 71 */ 72 public static int judgeAndFind4(Node head1,Node head2) 73 { 74 int length1 = 0; 75 int length2 = 0; 76 Node temp1 = head1; 77 Node temp2 = head2; 78 while(temp1!=null) 79 { 80 length1++; 81 temp1 = temp1.next; 82 } 83 while(temp2!=null) 84 { 85 length2++; 86 temp2 = temp2.next; 87 } 88 if(length1>length2) 89 { 90 for(int i=0;i<length1-length2;i++) 91 { 92 head1 = head1.next; 93 } 94 while(head1!=head2&&head1!=null&&head2!=null) 95 { 96 head1 = head1.next; 97 head2 = head2.next; 98 } 99 if(head1==null) 100 { 101 return 0; 102 } 103 else { 104 return head1.val; 105 } 106 } 107 else { 108 for(int i=0;i<length2-length1;i++) 109 { 110 head2 = head2.next; 111 } 112 while(head1!=head2&&head1!=null&&head2!=null) 113 { 114 head1 = head1.next; 115 head2 = head2.next; 116 } 117 if(head1==null) 118 { 119 return 0; 120 } 121 else { 122 return head1.val; 123 } 124 } 125 } 126 /*第三种思路是比较奇特的,在编程之美上看到的。 127 * 先遍历第一个链表到他的尾部,然后将尾部的next指针指向第二个链表(尾部指针的next本来指向的是null)。 128 * 这样两个链表就合成了一个链表,判断原来的两个链表是否相交也就转变成了判断新的链表是否有环的问题了: 129 * 即判断单链表是否有环 130 * 这种只能判断是否有交点 131 */ 132 public static boolean judge3(Node head1,Node head2) 133 { 134 while(head1!=null&&head1.next!=null) 135 { 136 head1 = head1.next; 137 } 138 head1.next = head2; 139 return hasLoop3(head2); 140 } 141 142 public static boolean hasLoop3(Node head){ 143 Node p1 = head; //定义一个引用指向头结点 144 Node p2 = head.next; //定义另一个引用指向头结点的下一个结点 145 146 /** 147 * 因为引用p2要比p1走的快,所以要用它作为循环的结束标志,为了防止当链表中个数为 148 * 偶数时出现p2.next=null空指针异常,这时可以在循环中进行一下判断,如果这种情况 149 * 出现一定是无环的。 150 */ 151 while(p2 != null && p2.next != null){ 152 p1 = p1.next; 153 p2 = p2.next.next; 154 if(p2 == null) 155 return false; 156 //为了防止p2.val出现空指针异常,需要对p2进行判断 157 int val1 = p1.val; 158 int val2 = p2.val; 159 if(val1 == val2) 160 return true; 161 } 162 return false; 163 } 164 public static void main(String[] args) { 165 Node n1 = new Node(1); 166 Node n2 = new Node(2); 167 Node n3 = new Node(3); 168 Node n4 = new Node(4); 169 Node n5 = new Node(5); 170 Node n6 = new Node(6); 171 Node n7 = new Node(7); 172 Node n8 = new Node(8); 173 Node n9 = new Node(9); 174 n1.next = n2; 175 n2.next = n3; 176 n3.next = n4; 177 n4.next = n5; 178 n5.next = n6; 179 n7.next = n8; 180 n8.next = n9; 181 n9.next = n4; 182 System.out.println(judgeAndFind1(n1,n7)); 183 System.out.println(judgeAndFind2(n1,n7)); 184 System.out.println(judgeAndFind4(n1,n7)); 185 System.out.println(judge3(n1,n7)); 186 } 187 }
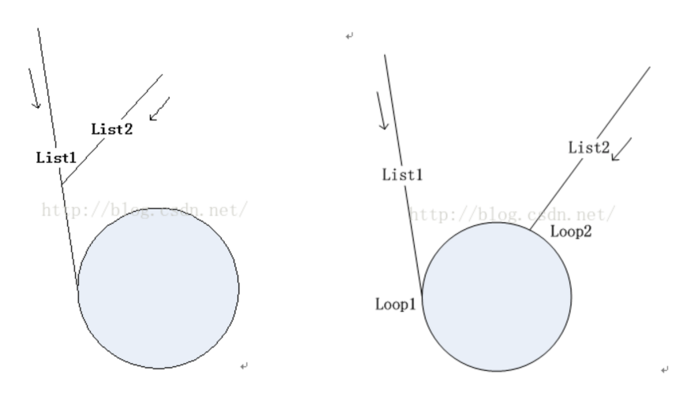
两个链表均存在环
对于连个链表均存在环的情况,相交点要么在环上,要么在环外
1 import java.security.KeyStore.Entry; 2 import java.util.HashMap; 3 4 import javax.xml.transform.Templates; 5 6 7 8 9 //判断两个有环链表是否相交如果相交找到交点 10 public class LoopHoopIntersection { 11 //内部静态类定义结点类 12 static class Node{ 13 int val; 14 Node next; 15 public Node(int val){ 16 this.val = val; 17 } 18 } 19 /* 20 * 在得到环的入口点之后,各自判断环的入口点是否相同,如果如口点相同, 21 * 只需计算着两个链表到入口点部分长度之差,然后用长的部分减去差,再同时与短的部分同步前进,如果节点相同,则为相交点。 22 * 反之如果入口点不同,则相交点为这两个链表的任意一个入口点。 23 */ 24 public static int judgeAndFind(Node head1,Node head2) 25 { 26 Node temp1 = head1; 27 Node temp2 = head2; 28 Node entrance1 = findNode3(temp1); 29 Node entrance2 = findNode3(temp2); 30 if(entrance1==entrance2) 31 { 32 Node temp3 = head1; 33 Node temp4 = head2; 34 return judgeAndFind4(temp3,temp4,entrance1,entrance2).val; 35 } 36 else { 37 System.out.println("交点为"+entrance1.val+entrance2.val); 38 return entrance1.val; 39 } 40 } 41 42 /* 43 * 首先创建两个指针1和2(在java里就是两个对象引用),同时指向这个链表的头节点。 44 * 然后开始一个大循环,在循环体中,让指针1每次向下移动一个节点,让指针2每次向下移动两个节点,然后比较两个指针指向的节点是否相同。 45 * 如果相同,则判断出链表有环,如果不同,则继续下一次循环。 46 * 相同后,把p2放在头部,两者同速运动,则相遇点一定是环的起点 47 * 48 */ 49 public static Node findNode3(Node pHead) 50 { 51 if(pHead==null||pHead.next==null) 52 { 53 return null; 54 } 55 Node p1=pHead; 56 Node p2=pHead; 57 while(p2!=null&&p2.next!=null) 58 { 59 p1=p1.next; 60 p2=p2.next.next; 61 if(p1==p2) 62 { 63 p1=pHead; 64 while(p1!=p2) 65 { 66 p1=p1.next; 67 p2=p2.next; 68 } 69 if(p1==p2) 70 { 71 return p1; 72 } 73 74 } 75 } 76 return null; 77 } 78 79 public static Node judgeAndFind4(Node head1,Node head2,Node enNode1,Node enNode2) 80 { 81 int length1 = 0; 82 int length2 = 0; 83 Node temp1 = head1; 84 Node temp2 = head2; 85 while(temp1!=null&&temp1!=enNode1) 86 { 87 length1++; 88 temp1 = temp1.next; 89 } 90 while(temp2!=null&&temp2!=enNode2) 91 { 92 length2++; 93 temp2 = temp2.next; 94 } 95 if(length1>length2) 96 { 97 for(int i=0;i<length1-length2;i++) 98 { 99 head1 = head1.next; 100 } 101 while(head1!=head2&&head1!=null&&head2!=null) 102 { 103 head1 = head1.next; 104 head2 = head2.next; 105 } 106 if(head1==null) 107 { 108 return null; 109 } 110 else { 111 return head1; 112 } 113 } 114 else { 115 for(int i=0;i<length2-length1;i++) 116 { 117 head2 = head2.next; 118 } 119 while(head1!=head2&&head1!=null&&head2!=null) 120 { 121 head1 = head1.next; 122 head2 = head2.next; 123 } 124 if(head1==null) 125 { 126 return null; 127 } 128 else { 129 return head1; 130 } 131 } 132 } 133 public static void main(String[] args) { 134 Node n1 = new Node(1); 135 Node n2 = new Node(2); 136 Node n3 = new Node(3); 137 Node n4 = new Node(4); 138 Node n5 = new Node(5); 139 Node n6 = new Node(6); 140 Node n7 = new Node(7); 141 Node n8 = new Node(8); 142 Node n9 = new Node(9); 143 n1.next = n2; 144 n2.next = n3; 145 n3.next = n4; 146 n4.next = n5; 147 n5.next = n6; 148 n6.next = n3; 149 n7.next = n8; 150 n8.next = n9; 151 n9.next = n4; 152 System.out.println(judgeAndFind(n1,n7)); 153 } 154 }