可以看到,技术圈的风向一直在变,大数据、云的热度已经在慢慢消退,现在当红的是 AI 和 IoT。这些火热的概念,它最终要从论文和 PPT 落地,变成真正能解决问题的系统,否则就是一个空中楼阁。那不变的是什么?(一些题外话的感触)
主题和队列有什么区别?
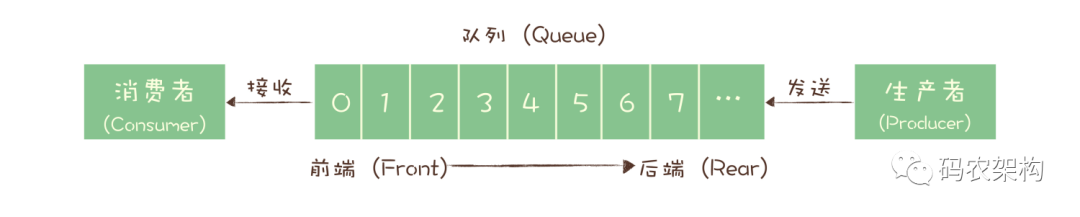
最初的消息队列,就是一个严格意义上的队列
-
消费者之间实际上是竞争的关系,每个消费者只能收到队列中的一部分消息
如果需要将一份消息数据分发给多个消费者,要求每个消费者都能收到全量的消息,例如,对于一份订单数据,风控系统、分析系统、支付系统等都需要接收消息。这个时候,单个队列就满足不了需求,一个可行的解决方式是,为每个消费者创建一个单独的队列,让生产者发送多份 (不好的做法).
为了解决这个问题,演化出了另外一种消息模型:“发布 - 订阅模型(Publish-Subscribe Pattern)”。
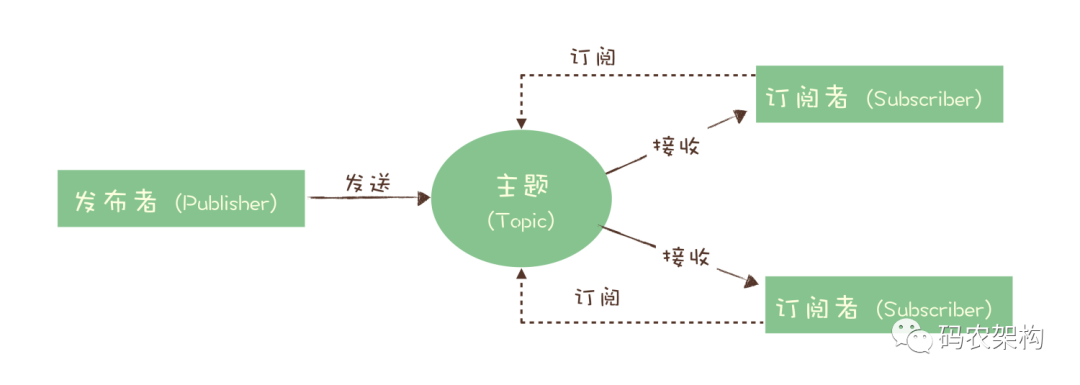
在发布 - 订阅模型中,消息的发送方称为发布者(Publisher),消息的接收方称为订阅者(Subscriber),服务端存放消息的容器称为主题(Topic)。发布者将消息发送到主题中,订阅者在接收消息之前需要先“订阅主题”。“订阅”在这里既是一个动作,同时还可以认为是主题在消费时的一个逻辑副本,每份订阅中,订阅者都可以接收到主题的所有消息。
现代的消息队列产品使用的消息模型大多是这种发布 - 订阅模型
RabbitMQ的消息模型
它是少数依然坚持使用队列模型的产品之一.
在 RabbitMQ 中,Exchange 位于生产者和队列之间,生产者并不关心将消息发送给哪个队列,而是将消息发送给 Exchange,由 Exchange 上配置的策略来决定将消息投递到哪些队列中。
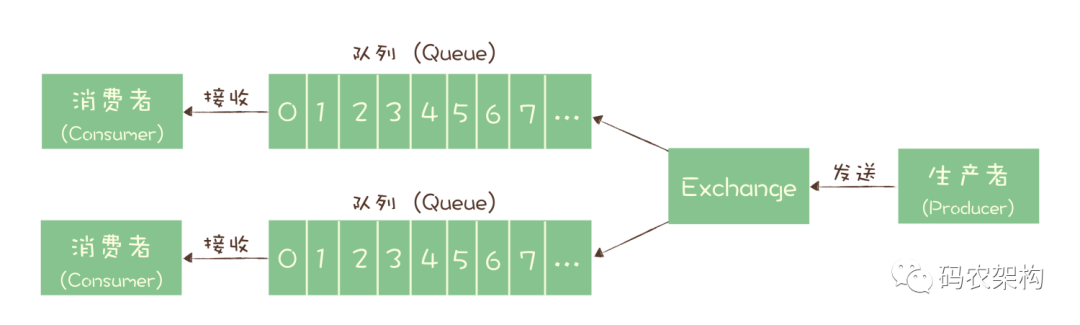
同一份消息如果需要被多个消费者来消费,需要配置 Exchange 将消息发送到多个队列,每个队列中都存放一份完整的消息数据,可以为一个消费者提供消费服务。
这也可以变相地实现新发布 - 订阅模型中,“一份消息数据可以被多个订阅者来多次消费”这样的功能。
RocketMQ的消息模型
RocketMQ 使用的消息模型是标准的发布 - 订阅模型
确认机制很好地保证了消息传递过程中的可靠性,但是,引入这个机制在消费端带来了一个不小的问题。为了确保消息的有序性,在某一条消息被成功消费之前,下一条消息是不能被消费的,否则就会出现消息空洞,违背了有序性这个原则。
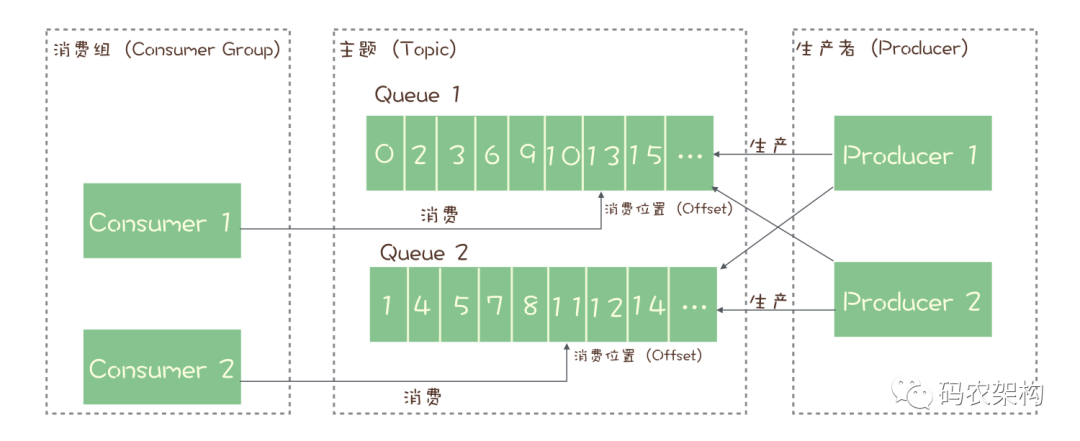
也就是说,每个主题在任意时刻,至多只能有一个消费者实例在进行消费,那就没法通过水平扩展消费者的数量来提升消费端总体的消费性能。为了解决这个问题,RocketMQ 在主题下面增加了队列的概念。
-
每个主题包含多个队列,通过多个队列来实现多实例并行生产和消费
-
RocketMQ 只在队列上保证消息的有序性,主题层面是无法保证消息的严格顺序的 (同一队列有序, 队列之间无序)
RocketMQ 中,订阅者的概念是通过消费组(Consumer Group)来体现的。每个消费组都消费主题中一份完整的消息,不同消费组之间消费进度彼此不受影响,也就是说,一条消息被 Consumer Group1 消费过,也会再给 Consumer Group2 消费。
消费组中包含多个消费者,同一个组内的消费者是竞争消费的关系,每个消费者负责消费组内的一部分消息。如果一条消息被消费者 Consumer1 消费了,那同组的其他消费者就不会再收到这条消息。
在 Topic 的消费过程中,由于消息需要被不同的组进行多次消费,所以消费完的消息并不会立即被删除,这就需要 RocketMQ 为每个消费组在每个队列上维护一个消费位置(Consumer Offset),这个位置之前的消息都被消费过,之后的消息都没有被消费过,每成功消费一条消息,消费位置就加一。这个消费位置是非常重要的概念,我们在使用消息队列的时候,丢消息的原因大多是由于消费位置处理不当导致的。
Kafka的消息模型
Kafka 的消息模型和 RocketMQ 是完全一样的.
唯一的区别是,在 Kafka 中,队列这个概念的名称不一样,Kafka 中对应的名称是分区(Partition)
总结
-
主题: 发布-订阅
-
队列: 先进先出
业务模型不等于就是实现层面的模型。比如说 MySQL 和 Hbase 同样是支持 SQL 的数据库,它们的业务模型中,存放数据的单元都是“表”,但是在实现层面,没有哪个数据库是以二维表的方式去存储数据的,MySQL 使用 B+ 树来存储数据,而 HBase 使用的是 KV 的结构来存储。同样,像 Kafka 和 RocketMQ 的业务模型基本是一样的,并不是说他们的实现就是一样的,实际上这两个消息队列的实现是完全不同的。