1. 一些对象说明
- PluginRepository:这是一个用于存储所有插件描述对象(PluginDescriptor),插件扩展点(ExtensionPoint)和被激活的插件。
- PluginDescriptor:用于描述单个扩展插件的元信息,它的内容主要是从plugin.xml中得到。
- Plugin: 用于描述插件的一个抽象,其中包括了一个插件描述符,它们是一对一的关系。
- ExtensionPoint: 这个扩展点主要是一个面象对象中的接口的意思,就是说可以有多个扩展来实现这个接口,一个或者多个扩展点实际上就是一个插件,如nutch-extensionpoints.
- Extension: 扩展是对于扩展点的实现,一个插件可以包含多个扩展。
- PluginManifestParser: 主要是用于解析插件目录下的plugin.xml文件,生成相应的PluginDescriptor对象。
- PluginClassLoader: 它继承自URLClassLoader,用来根据urls动态生成相应的插件实现对象
2. 插件仓库初始化流程
PluginRepository的生成有两种方法,一个是直接new一个相应的对象,另一个是调用PluginRepository的静态的get方法,从Cache中得到相应的PluginRepository,在Nutch的流程中,一般是通用使用第二种方法来得到PluginRepository,这样可以保证资源在多个流程中得到共享。
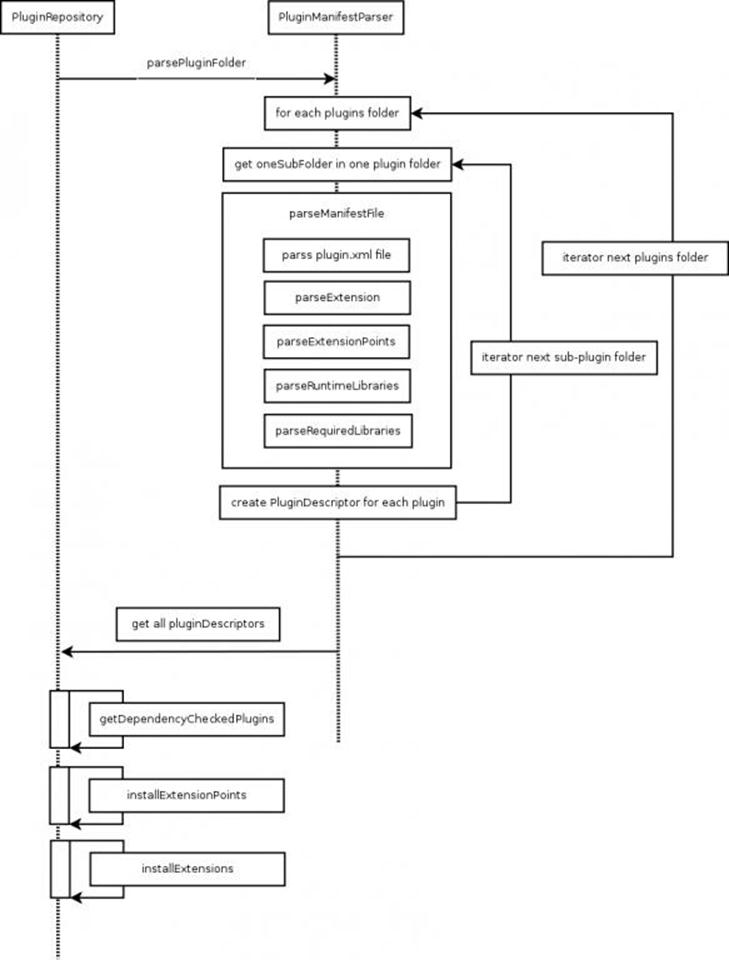
2.1 PluginRepostory的初始化在其ctr函数中进行
源代码如下:
-
fActivatedPlugins = new HashMap<String, Plugin>();
-
fExtensionPoints = new HashMap<String, ExtensionPoint>();
-
this.conf = conf;
-
// 当被配置为过滤(即不加载),但是又被其他插件依赖的时候,是否自动启动,缺省为 true
-
this.auto = conf.getBoolean("plugin.auto-activation", true);
-
// 插件的目录名,可以是多个目录
-
String[] pluginFolders = conf.getStrings("plugin.folders");
-
PluginManifestParser manifestParser = new PluginManifestParser(conf, this);
-
Map<String, PluginDescriptor> allPlugins = manifestParser.parsePluginFolder(pluginFolders);
-
// 要排除的插件名称列表,支持正则表达式方式定义
-
Pattern excludes = Pattern.compile(conf.get("plugin.excludes", ""));
-
// 要包含的插件名称列表,支持正则表达式方式定义
-
Pattern includes = Pattern.compile(conf.get("plugin.includes", ""));
-
// 对不使用的插件进行过滤,返回过滤后的插件
-
Map<String, PluginDescriptor> filterfilteredPlugins = filter(excludes, includes,allPlugins);
-
// 对插件的依赖关系进行检查
-
fRegisteredPlugins = getDependencyCheckedPlugins(filteredPlugins,this.auto ? allPlugins : filteredPlugins);
-
// 安装扩展点,主要是针对nutch-extensionpoints这个插件的
-
installExtensionPoints(fRegisteredPlugins);
-
try {
-
// 安装特定扩展点的相应扩展集
-
// NOTE:其实这边的扩展点与扩展都是以插件的形式表现的
-
installExtensions(fRegisteredPlugins);
-
} catch (PluginRuntimeException e) {
-
LOG.fatal(e.toString());
-
throw new RuntimeException(e.getMessage());
-
}
-
displayStatus();
2.2 下面分析一个插件描述符的生成
插件描述符的生成主要是通用调用PluginManifestParser这个对象的parsePluginFolder这个方法生成的,源代码如下:
-
/**
-
* Returns a list of all found plugin descriptors.
-
*
-
* @param pluginFolders
-
* folders to search plugins from
-
* @return A {@link Map} of all found {@link PluginDescriptor}s.
-
*/
-
public Map<String, PluginDescriptor> parsePluginFolder(String[] pluginFolders) {
-
Map<String, PluginDescriptor> map = new HashMap<String, PluginDescriptor>();
-
-
-
if (pluginFolders == null) {
-
throw new IllegalArgumentException("plugin.folders is not defined");
-
}
-
-
-
for (String name : pluginFolders) {
-
// 遍历所有插件目录,这里的getPluginFolder方法解析一个资源的相对路径的问题
-
File directory = getPluginFolder(name);
-
if (directory == null) {
-
continue;
-
}
-
-
LOG.info("Plugins: looking in: " + directory.getAbsolutePath());
-
// 遍历所有子插件目录中的插件
-
for (File oneSubFolder : directory.listFiles()) {
-
if (oneSubFolder.isDirectory()) {
-
String manifestPath = oneSubFolder.getAbsolutePath() + File.separator
-
+ "plugin.xml";
-
try {
-
LOG.debug("parsing: " + manifestPath);
-
// 分析plugin.xml文件
-
PluginDescriptor p = parseManifestFile(manifestPath);
-
map.put(p.getPluginId(), p);
-
} catch (MalformedURLException e) {
-
LOG.warn(e.toString());
-
} catch (SAXException e) {
-
LOG.warn(e.toString());
-
} catch (IOException e) {
-
LOG.warn(e.toString());
-
} catch (ParserConfigurationException e) {
-
LOG.warn(e.toString());
-
}
-
}
-
}
-
}
-
return map;
-
}
-
private PluginDescriptor parseManifestFile(String pManifestPath)
-
throws MalformedURLException, SAXException, IOException,
-
ParserConfigurationException {
-
// 解析xml文件,生成Document对象
-
Document document = parseXML(new File(pManifestPath).toURL());
-
String pPath = new File(pManifestPath).getParent();
-
// 对xml进行分析
-
return parsePlugin(document, pPath);
-
}
-
private PluginDescriptor parsePlugin(Document pDocument, String pPath)
-
throws MalformedURLException {
-
Element rootElement = pDocument.getDocumentElement();
-
// 这里是解析xml中的如下信息
-
// <plugin id="index-anchor" name="Anchor Indexing Filter" version="1.0.0" provider-name="nutch.org">
-
String id = rootElement.getAttribute(ATTR_ID);
-
String name = rootElement.getAttribute(ATTR_NAME);
-
String version = rootElement.getAttribute("version");
-
String providerName = rootElement.getAttribute("provider-name");
-
// 插件类属性,不过这里好像没有用到过
-
String pluginClazz = null;
-
if (rootElement.getAttribute(ATTR_CLASS).trim().length() > 0) {
-
pluginClazz = rootElement.getAttribute(ATTR_CLASS);
-
}
-
// 生成插件描述符对象
-
PluginDescriptor pluginDescriptor = new PluginDescriptor(id, version, name,
-
providerName, pluginClazz, pPath, this.conf);
-
LOG.debug("plugin: id=" + id + " name=" + name + " version=" + version
-
+ " provider=" + providerName + "class=" + pluginClazz);
-
// 这里是解析如下内容
-
// <extension id="org.apache.nutch.indexer.anchor" name="Nutch Anchor Indexing Filter" point="org.apache.nutch.indexer.IndexingFilter">
-
// <implementation id="AnchorIndexingFilter"
-
// class="org.apache.nutch.indexer.anchor.AnchorIndexingFilter" />
-
// </extension>
-
parseExtension(rootElement, pluginDescriptor);
-
// 这里主要是解析nutch-extensionPoints这个插件,xml内容如下
-
// <extension-point id="org.apache.nutch.indexer.IndexingFilter" name="Nutch Indexing Filter"/>
-
// <extension-point id="org.apache.nutch.parse.Parser" name="Nutch Content Parser"/>
-
// <extension-point id="org.apache.nutch.parse.HtmlParseFilter" name="HTML Parse Filter"/>
-
parseExtensionPoints(rootElement, pluginDescriptor);
-
// 这里主要是解析插件的动态库与插件所使用的第三方库,xml内容如下
-
// <runtime>
-
// <library name="parse-tika.jar">
-
// <export name="*"/>
-
// </library>
-
// <library name="apache-mime4j-0.6.jar"/>
-
// <library name="asm-3.1.jar"/>
-
// <library name="bcmail-jdk15-1.45.jar"/>
-
// <library name="bcprov-jdk15-1.45.jar"/>
-
// </runtime>
-
parseLibraries(rootElement, pluginDescriptor);
-
// 这里解析插件依赖的插件库,xml内容如下
-
// <requires>
-
// <import plugin="nutch-extensionpoints"/>
-
// <import plugin="lib-regex-filter"/>
-
// </requires>
-
parseRequires(rootElement, pluginDescriptor);
-
return pluginDescriptor;
-
}
要注意的是这个PluginManifestParser就是用来解析相应的plugin.xml文件,生成PluginRepository对象的,这个有一个很奇怪的概念就是一个插件描述符(PluginDescriptor)可以包含多个可扩展点或者可扩展点的实现,这里为什么不把可扩展点分离出来,PluginDescriptor就只包含一个或者多个可扩展点的实现。而可扩展点就是插件的接口定义。
2.3 插件依赖关系的检查
这个依赖关系的检查很有趣,主要是根据plugin.auto-activation这个参数来定的,部分源代码如下:
-
/**
-
* @param filtered
-
* is the list of plugin filtred
-
* @param all
-
* is the list of all plugins found.
-
* @return List
-
*/
-
private List<PluginDescriptor> getDependencyCheckedPlugins(
-
Map<String, PluginDescriptor> filtered, Map<String, PluginDescriptor> all) {
-
if (filtered == null) {
-
return null;
-
}
-
Map<String, PluginDescriptor> checked = new HashMap<String, PluginDescriptor>();
-
-
-
// 遍历所有过滤后的插件
-
for (PluginDescriptor plugin : filtered.values()) {
-
try {
-
// 保存当前插件的依赖插件描述符
-
checked.putAll(getPluginCheckedDependencies(plugin, all));
-
// 保存当前插件描述符
-
checked.put(plugin.getPluginId(), plugin);
-
} catch (MissingDependencyException mde) {
-
// Log exception and ignore plugin
-
LOG.warn(mde.getMessage());
-
} catch (CircularDependencyException cde) {
-
-
// Simply ignore this plugin
-
LOG.warn(cde.getMessage());
-
}
-
}
-
return new ArrayList<PluginDescriptor>(checked.values());
-
}
3. 插件调用流程
插件调用流程主要分成如下几步:
- 根据扩展点ID号从插件仓库中得到相应的扩展点对象
- 根据扩展点对象得到相应的扩展集
- 遍历扩展集,从扩展对象中实例化出相应的扩展来,实例化的过滤就是调用PluginClassLoader
下面是生成URLFilter插件的部分代码:
-
(1)
-
ExtensionPoint point = PluginRepository.get(conf).getExtensionPoint(URLFilter.X_POINT_ID);
-
if (point == null)
-
throw new RuntimeException(URLFilter.X_POINT_ID + " not found.");
-
(2)
-
Extension[] extensions = point.getExtensions();
-
Map<String, URLFilter> filterMap = new HashMap<String, URLFilter>();
-
for (int i = 0; i < extensions.length; i++) {
-
Extension extension = extensions[i];
-
(3)
-
URLFilter filter = (URLFilter) extension.getExtensionInstance();
-
if (!filterMap.containsKey(filter.getClass().getName())) {
-
filterMap.put(filter.getClass().getName(), filter);
-
}
-
}
4. 总结
Nutch的插件机制还是比较经典的,上面只是做了一个简单的分析,要深入理解还是要多实践。
作者:http://blog.csdn.net/amuseme_lu
相关文章阅读及免费下载:
《Apache Nutch 1.3 学习笔记三(Inject)》
《Apache Nutch 1.3 学习笔记三(Inject CrawlDB Reader)》
《Apache Nutch 1.3 学习笔记四(Generate)》
《Apache Nutch 1.3 学习笔记四(SegmentReader分析)》
《Apache Nutch 1.3 学习笔记五(FetchThread)》
《Apache Nutch 1.3 学习笔记五(Fetcher流程)》
《Apache Nutch 1.3 学习笔记六(ParseSegment)》
《Apache Nutch 1.3 学习笔记七(CrawlDb - updatedb)》
《Apache Nutch 1.3 学习笔记八(LinkDb)》
《Apache Nutch 1.3 学习笔记九(SolrIndexer)》
《Apache Nutch 1.3 学习笔记十(Ntuch 插件机制简单介绍)》
《Apache Nutch 1.3 学习笔记十(插件扩展)》
《Apache Nutch 1.3 学习笔记十(插件机制分析)》
《Apache Nutch 1.3 学习笔记十一(页面评分机制 OPIC)》
《Apache Nutch 1.3 学习笔记十一(页面评分机制 LinkRank 介绍)》