锁的内存语义
中所周知,锁可以让临界区互斥执行。这里将介绍锁的另一个同样重要但常常被忽视的功能:锁的内存语义
锁的释放-获取建立的happens-before关系
锁是Java并发编程中最重要的同步机制。锁除了让临界区互斥执行外,还可以让释放锁的线程向获取同一个锁的线程发送消息。
下面是锁释放-获取的示例代码
public class MonitorExample { int a = 0; public synchronized void writer(){ //1 a++; //2 } //3 public synchronized void reader(){ //4 int i = a; //5 ... } //6 }
假设线程A执行writer()方法,随后线程B执行reader()方法。根据happens-before规则,这个过程包含的happens-before关系可以分为3类
(1)根据程序次序规则,1 happens-before 2,2 happens-before 3,4 happens-before 5,5 happens-before 6
(2)根据监视器锁规则,3 happens-before 4
(3)根据happens-before的传递性,2 happens-before 5
上述happens-before关系图形化表现形式如下图所示
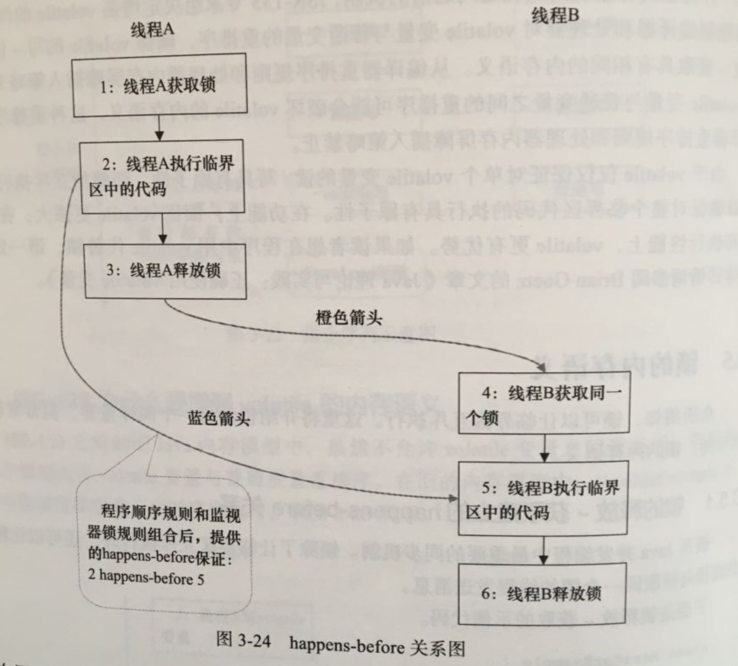
上图每一个箭头链接的两个节点,代表一个happens-before关系。黑色箭头表示程序顺序规则;橙色箭头表示监视器锁规则;蓝色箭头表示组合这些规则后提供的happens-before保证。
在线程A释放锁之后,随后线程B获取同一个锁,2 happens-before 5,因此线程A在释放锁之前所有可见的共享变量,在线程B获取同一个锁之后,将立刻变得对B线程可见。
锁的释放-获取的内存语义
当线程释放锁时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存中。
当线程获取琐时,JMM会把该线程对应的本地内存置为无效。从而使得被监视器保护的临界区代码必须从主内存中读取共享变量。
对比锁释放-获取的内存语义与volatile写-读的内存语义可以看出:锁释放与volatile写有相同的内存语义,锁获取与volatile读有相同的内存语义。
下面对锁释放-获取内存语义做个总结:
- 线程A释放一个锁,实质上是线程A向接下来将要获取这个锁的某个线程发出出了(线程A对共享变量所做修改的)消息
- 线程B获取一个锁,实质上是线程B接受了之前某个线程发出的(在释放这个锁之前对共享变量所做修改的)消息
- 线程A释放锁,随后线程B获取这个锁,这个过程实质上是线程A通过住内存向线程B发送消息
锁内存语义的实现
本文将借助ReentrantLock的源代码,来分析锁内存语义的具体实现机制。
在ReentrantLock中,调用lock()方法获取锁,调用unlock()方法释放锁。ReentrantLock的实现依赖于Java同步框架AbstactQueuedSynchronizer(本文简称之AQS)。AQS使用一个整型的 volatile变量(命名为state)为维护同步状态,这个volatile变量是ReentrantLock内存语义实现的关键。
ReentrantLock分为公平锁和非公平锁,我们首先分析公平锁。
使用公平锁时,加锁方法lock()调用的轨迹如下:
- ReentrantLock:lock()
- FairSync:lock()
- AbstactQueuedSynchronizer: acquire(int arg)
- ReentrantLock:tryAcquire(int acquries)
在第4步真正开始加锁,下面是该方法的源代码
protected final boolean tryAcquire(int acquires){ final Thread current = Thread.currentThread(); int c = getState(); //获取锁的开始,首先读volatile变量的state if(c ==0){ if(isFirst(current) && copareAndSetState(0,acquires)){ setExclusiveOwnerThread(current); return true; } }else if (current == getExclusiveOwnerThread()){ int nextc = c + acquires; if(nextc < 0){ throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; } }
从上面的源代码我们可以看出,加锁方法是先读volatile变量state。
使用公平锁时,解锁方法unlock()调用轨迹如下:
- ReentrantLock:unlock()
- AbstactQueuedSynchronizer: release(int arg)
- Sync:tryRelease(int release)
protected final boolean tryRelease(int releases) { int c = getState() - releases; if (Thread.currentThread() != getExclusiveOwnerThread()) throw new IllegalMonitorStateException(); boolean free = false; if (c == 0) { free = true; setExclusiveOwnerThread(null); } setState(c); //释放锁的最后,写volatile变量state return free; }
从上面的源代码我们可以看出,在释放锁的最后写volatile变量state。
公平锁在释放锁的最后写volatile变量state,在获取锁时首先读这个volatile变量。根据volatile的happens-before规则,释放锁的线程在写volatile变量之前可见的共享变量,在获取锁的线程读取同一个volatile变量后将立即变得对获取锁的线程可见。
现在来分析非公平锁的内存语义的实现。非公平锁的释放和公平锁完全一样,所以这里仅仅分析非公平锁的获取。使用非公平锁时,加锁方法lock(),加锁方法lock()调用轨迹如下:
- ReentrantLock:lock()
- NonfairSync: lock()
- AbstactQueuedSynchronizer:tryRelease(int release)
在第3步开始加锁,下面是该方法的源代码
protected final boolean compareAndSetState(int ,expect, int update){ return unsafe.compareAndSwapInt(this, stateOffset, expect, update); }
该方法以原子操作的方式更新state变量,本来把Java的compareAndSet()方法调用简称为CAS。JDK文档对该方法的说明如下:如果当前状态值等于预期值,则以原子方式将同步状态设置为给定的更新值。此操作具有volatile读和写的内存语义。
现在对公平锁和非公平锁的内存语义做个总结:
-
公平锁和非公平锁释放时,最后都要写一个colatile变量state
-
公平锁获取时,首先会去读volatile变量
- 非公平锁获取时,首先会用CAS更新volatile变量,这个操作同时具有volatile读和volatile写的内存语义
本文对ReentrantLock的分析可以看出,锁释放-获取的内存语义的实现至少有下面两种方式:
(1)利用volatile变量的写-读所具有的内存语义
(2)利用CAS所附带的volatile读和volatile写的内存语义
concurrent包的实现
由于Java的CAS同时具有volatile读和volatile写的内存语义,因此Java线程之间的通信有下面4种方式
- A线程写volatile变量,随后B线程读这个volatile变量
- A线程写volatile变量,随后B线程用CAS更新这个volatile变量
- A线程用CAS更新一个volatile变量,随后B线程用CAS更新这个volatile变量
- A线程用CAS更新一个volatile变量,随后B线程读这个volatile变量
Java的CAS会使用现代处理器上提供的高效机器级别的原子指令,这些原子指令以原子方式对内存执行读-改-写操作,这是在多处理器中实现同步的关键。同时,volatile变量的读/写和CAS可以实现线程之间的通信。把这些特性整合在一起,就形成了整个concurrent包得以实现的基石。如果我们仔细分析concurrent包的源代码实现,会发现一个通用化的实现模式:
首先,声明共享变量为volatile
然后,使用CAS的原子条件更新来实现线程之间的同步
同时,配合以volatile的读/写和cas所具有的volatile读和写的内存语义来实现线程之间的通信
以下是concurrent包的实现示意图

final域的内存语义
前面介绍锁和volatile相比,对final域的读和写更像是普通的变量访问。下面介绍final域的内存语义
final域的重排序规则
对于final域,编译器和处理器要遵守两个重排序规则
(1)在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序
(2)初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序
写final域的重排序规则
写final域的重排序规则禁止把final域的写重排序到构造函数之外。这个规则的实现包含下面2个方面
(1)JMM禁止编译器把final域的写重排序到构造函数之外
(2)编译器会在final域的写之后,构造函数return之前,插入一个StoreStore屏障。这个屏障禁止处理器把final域的写重排序到构造函数之外
现在让我们粉笔writer()方法。writer()方法只包含一行代码:finalExample = new FinalExample(),这行代码先构造一个FinalExample类型的对象,然后把这个对象引用赋值给引用变量的obj。假设线程B读对象引用与读对象的成员域之间没有重排序,下图是一种可能的执行时序
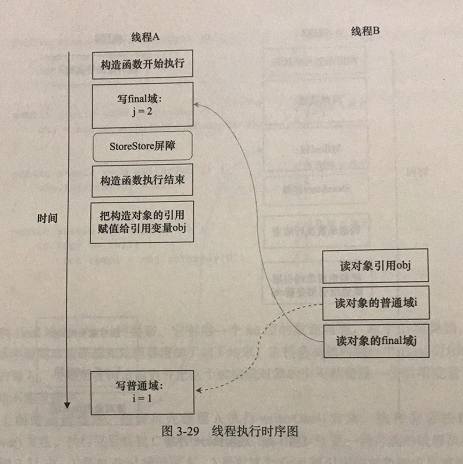
图中,写普通域的操作被编译器重排序到了构造函数之外,读线程B错误地读取了普通变量I初始化之前的值。而写final域的操作,被写final域的重排序规则“限定”在了构造函数之内,读线程B正确地读取了final变量初始化之后的值。
写final域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域不具有这个保障。
读final域的重排序规则
读final域的重排序规则是,在一个线程中,初次读对象引用与初次读该对象包含的final域,JMM禁止处理器重排序这两个操作(注意。这个规则仅仅针对处理器)。编译器会在读final域操作的前面拆入一个LoadLoad屏障。
初次读对象引用与初次读该对象包含的final域,这两个操作之间存在间接依赖关系。由于编译器遵守间接依赖关系,因此编译器不会重排序这两个操作。大多数处理器也会遵守间接依赖,也不会重排序这两个操作,但有少数处理器允许对存在间接依赖关系的操作做重排序(比如alpha处理器),这个规则就是专门用来针对这种处理器的。
reader()方法包含3个操作
(1)初次读引用变量obj
(2)初次读引用变量obj指向对象的普通域 j
(3)初次读引用变量obj指向对象的final域 i
现在假设写线程A没有发生任何重排序,同事程序在不遵守哦间接依赖的处理器上执行,下图所示是一种可能的执行时序
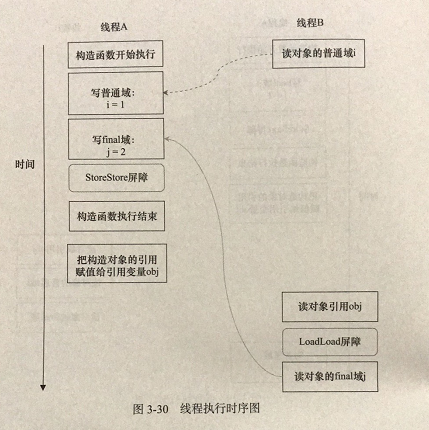
上图中,读对象的普通域的操作被处理器重排序到读对象引用之前。读普通域时,该域还没有被写线程A写入,这是一个错误的读取操作。而读final域的重排序规则会把读对象final域的操作“限定”在读对象引用之后,此时该final域已经被A线程初始化过了,这是一个正确的读取操作。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读包含这个final域的对象的引用。在这个示例程序中,如果该引用不为null,那么引用对象的final域一定已经被A线程初始化过了。
上面看到是final域是基础数据类型,final域为引用类型将会有什么效果?
在构造函数内对一个final引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
JSR-133为什么要增强final的语义
在旧的Java内存模型中,一个最严重的缺陷就是线程可能看到final域的值会改变。比如,一个线程当前看到一个整型final域值为0(还未初始化之前的默认值),过一段时间之后这个线程再去读这个final域的值时,却发现值变为1(被某个线程初始化之后的值)。最常见的例子就是在旧的Java内存模型中,String的值可能会改变。
为了修补这个漏洞,JSR-133专家组增加了final的语义。通过为final域增加写和读重排序规则,可以为Java程序员提供初始化安全保证:只要对象是正确构造的(被构造对象的引用在构造函数中没有“逸出”),那么不需要使用同步(指lock和volatile的使用)就可以保证任意线程都能看到这个final域在构造函数中被初始化之后的值。
happens-before
JSR-133使用happens-before的概念来指定两个操作之间的执行顺序。由于这两个操作可以在一个线程之内,也可以是在不同线程之间。因此,JMM可以通过happens-before关系向程序员提供跨线程的内存可见性保证(如果A线程的写操作A与B线程的读操作b之间存在happens-before关系,尽管a操作和b操作在不同的线程中执行,但JMM向程序员保证a操作将对b操作可见)。
happens-before定义如下:
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前
- 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一直,那么这种重排序并不非法(也就是说,JMM允许这种重排序)
as-if-seria语义保证单线程内程序的执行结果不被改变,happens-before关系保证正确同步的多线程程序的执行结果不被改变
as-id-serial语义给编写单线程程序的程序员创造了一个幻境:单线程程序是按照程序的顺序来执行的。happens-before关系给编写正确同步的多线程程序的程序员创造了一个幻境:正确同步的多线程程序是按照happens-before指定的顺序来执行的
happens-before规则
- 程序顺序规则:一个线程中的每个操作,happens-before与该线程中的任意后续操作
- 监视器锁规则:对一个锁的解锁,happens-before与随后对这个锁的加锁
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读
- 传递性:如果A happens-before B,且 B happens-before C,那么A happens-before C
- start()规则:如果线程A执行操作ThreadB.start(),那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作
- join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中任意操作happens-before于线程A从ThreadB.join()操作成功返回
Java内存模型综述
前面对Java内存模型的基础知识和内存模型的具体实现进行了说明。下面对Java内存模型的相关知识做一个总结。
处理器的内存模型
顺序一致性内存模型是一个理论参考模型,JMM和处理器内存模型在设计时通常会以顺序一致性内存模型为参照。在设计时,JMM和处理器内存模型会对顺序一致性模型做一些放松,因为如果完全按照顺序一致性模型来实现处理器和JMM,那么很多的处理器和编译器优化都要被禁止,这对执行性能将会有很大的影响。
根据对不同类型的读/写操作组合的执行顺序的放松,可以分为如下几种类型:
- 放松程序中写-读操作的顺序,由此产生了Total Store Ordering内存模型(简称TSO)
- 在上面的基础上,继续放松程序中写-写操作的顺序,由此产生了Partial Store Order内存模型(简称PSO)
- 在前面两条的基础上,继续放松程序中读-写和读-读操作的顺序,由此产生了Relaxed Memory Order内存模型(简称RMO)和PowerPC内存模型
注意,这里处理器对读/写操作的放松,是以两个操作之间不存在数据依赖性为前提的(因为处理器要遵守as-if-serial语义,处理器不会对存在数据依赖性的两个内存操作做重排序)。
下表展示了常见处理器内存模型的细节特征
| 内存模型名称 | 对应的处理器 | Store-Load重排序 | Store-Store重排序 | Load-Load和Load-Store重排序 | 可以更早读取到其他处理器的写 | 可以更早读取到当前处理器的写 |
| TSO | sparc-TSO X64 | Y | Y | |||
| PSO | sparc-PSO | Y | Y | Y | ||
| RMO | ia64 | Y | Y | Y | Y | |
| PowerPC | PowerPC | Y | Y | Y | Y | Y |
各种内存模型之间的关系
JMM是一个语言及的内存模型,处理器内存模型是硬件级的内存模型,顺序一致性内存模型是一个理论参考模型。下面是语言内存模型、处理器内存模型和顺序一致性内存模型强弱对比示意图
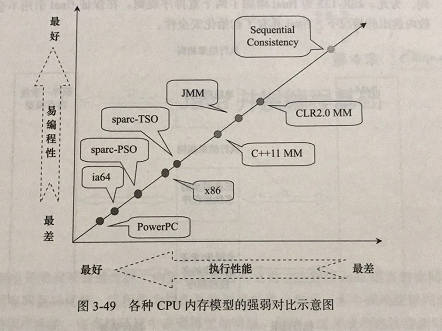
从图中可以看出:常见的4中处理器内存模型比常用的3种语言内存模型要弱,处理器内存模型和语言内存模型都比顺序一致性内存模型要弱。同处理器内存模型一样,越是追求执行性能的语言,内存模型设计得会越弱。