一、安装
1.1、kubernetes硬件支持问题说明
Kubernetes目前主要在很小程度上支持CPU和内存的发现。Kubelet本身处理的设备非常少。
Kubernetes对于硬件都使用都依赖于硬件厂商的自主研发kubernetes插件,通过硬件厂商的插件从而让kubernetes进行硬件支持。
实现的逻辑如下: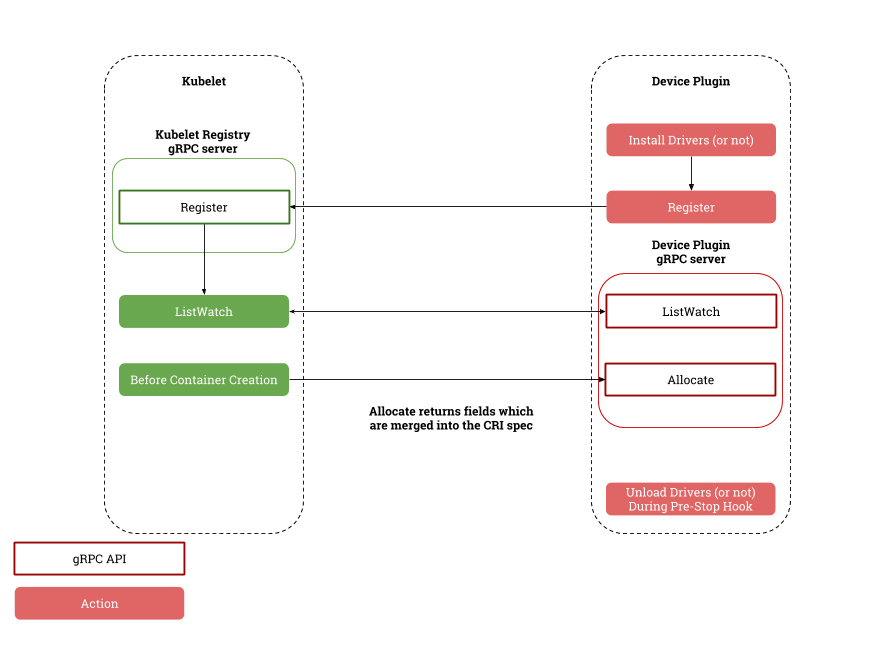
1.2、适用于Kubernetes的NVIDIA设备插件说明
Kubernetes的NVIDIA设备插件是一个Daemonset,允许您自动:
公开群集的每个节点上的GPU数量
跟踪GPU的运行状况
在Kubernetes集群中运行启用GPU的容器。
该存储库包含NVIDIA的Kubernetes设备插件的官方实现。
1.3、使用Kubernetes的NVIDIA设备插件条件(官方)
运行Kubernetes NVIDIA设备插件的先决条件列表如下所述:
- NVIDIA驱动程序〜= 361.93
- nvidia-docker version> 2.0(请参阅如何安装及其先决条件)
- docker配置了nvidia作为默认运行时。
- Kubernetes版本>= 1.11
运行nvidia-docker 2.0 先决条件列表如下所述:
- 内核版本> 3.10的GNU / Linux x86_64
- Docker> = 1.12
- 采用架构的NVIDIA GPU> Fermi(2.1)
- NVIDIA驱动程序〜= 361.93(旧版本未经测试)
1.4、删除nvidia-docker 1.0
在继续之前,必须彻底删除nvidia-docker软件包的1.0版。
您必须停止并删除所有使用nvidia-docker 1.0启动的容器。
1.4.1、Ubuntu发行版删除nvidia-docker 1.0
docker volume ls -q -f driver = nvidia-docker | xargs -r -I {} -n1 docker ps -q -a -f volume = {} | xargs -r docker rm -f
sudo apt-get purge nvidia-docker
1.4.2、CentOS发行版删除nvidia-docker 1.0
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo yum remove nvidia-docker
1.5、安装nvidia-docker 2.0
确保已为您的发行版安装了NVIDIA驱动程序和受支持的Docker 版本(请参阅先决条件)。
如果有自定义/etc/docker/daemon.json,则nvidia-docker2程序包可能会覆盖它,先做好相关备份。
1.5.1、Ubuntu发行版安装nvidia-docker 2.0
安装nvidia-docker2软件包并重新加载Docker守护程序配置:
sudo apt-get install nvidia-docker2 sudo pkill -SIGHUP dockerd
1.5.2、CentOS发行版安装nvidia-docker 2.0
安装nvidia-docker2软件包并重新加载Docker守护程序配置:
sudo yum install nvidia-docker2 sudo pkill -SIGHUP dockerd
1.5.3、较旧版本的Docker安装nvidia-docker 2.0(不推荐)
如果必须要使用旧版本的docker进行安装nvidia-docker 2.0
必须固定nvidia-docker2以及nvidia-container-runtime安装时的版本,例如:
sudo apt-get install -y nvidia-docker2=2.0.1+docker1.12.6-1 nvidia-container-runtime=1.1.0+docker1.12.6-1
使用
apt-cache madison nvidia-docker2 nvidia-container-runtime
或
yum search --showduplicates nvidia-docker2 nvidia-container-runtime
列出可用版本。
基本用法
nvidia-docker向Docker守护程序注册一个新的容器运行时。使用时必须选择nvidia运行时docker run:
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
nvidia-docker 2.0安装和使用方法详见《docker在Ubuntu下1小时快速学习》
二、配置
2.1、配置docker
需要启用nvidia运行时作为节点上的默认运行时。需要编辑docker守护进程配置文件,该文件通常出现在/etc/docker/daemon.json,配置内容如下:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
如果runtimes不存在,请重新安装nvidia-docker,或参考nvidia-docker官方页面
2.2、Kubernetes启用GPU支持
在您希望使用的所有 GPU节点上启用此选项后,您可以通过部署以下Daemonset在群集中启用GPU支持:
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.11/nvidia-device-plugin.yml
2.3、运行GPU作业
可以使用资源属性nvidia.com/gpu配置,来通过容器级资源使用NVIDIA GPU要求:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvidia/cuda:9.0-devel
resources:
limits:
nvidia.com/gpu: 2 #请求2个GPU
- name: digits-container
image: nvidia/digits:6.0
resources:
limits:
nvidia.com/gpu: 2 #请求2个GPU
警告: 如果在使用带有NVIDIA映像的设备插件时,未配置GPU请求个数,则宿主机上所有GPU都将暴露在容器内。
2.4、Kubernetes运行GPU容器
2.4.1、使用告示
- Nvidia的GPU设备插件功能是Kubernetes v1.11的测试版
- NVIDIA设备插件仍被视为测试版并且缺失
- 更全面的GPU健康检查功能
- GPU清理功能
- ...
- 仅为官方NVIDIA设备插件提供支持。
2.4.2、kubernetes在依赖Docker下运行GPU容器
1、获取镜像
方法1,从Docker Hub中提取预构建的映像:
docker pull nvidia/k8s-device-plugin:1.11
方法2,不使用镜像,采用官方build方法:
docker build -t nvidia/k8s-device-plugin:1.11 https://github.com/NVIDIA/k8s-device-plugin.git#v1.11
方法3,采用自定义build文件方法:
git clone https://github.com/NVIDIA/k8s-device-plugin.git && cd k8s-device-plugin docker build -t nvidia/k8s-device-plugin:1.11 .
2、在本地运行
docker run --security-opt=no-new-privileges --cap-drop=ALL --network=none -it -v /var/lib/kubelet/device-plugins:/var/lib/kubelet/device-plugins nvidia/k8s-device-plugin:1.11
3、kubernetes部署为守护进程集:
kubectl create -f nvidia-device-plugin.yml
2.4.3、kubernetes不依赖Docker下运行GPU容器
1、构建
C_INCLUDE_PATH=/usr/local/cuda/include LIBRARY_PATH=/usr/local/cuda/lib64 go build
2、在本地运行
./k8s-device-plugin