• 使用ADDM 的新功能
• 使用自动内存管理
• 使用统计信息增强功能
- Oracle Database 11g 中的ADDM 增强
• 用于RAC 的ADDM
• 指令(隐藏查找结果)
• DBMS_ADDM 程序包
- Oracle Database 11g:RAC 的自动数据库诊断监视器
Oracle Database 11g:RAC 的自动数据库诊断监视器
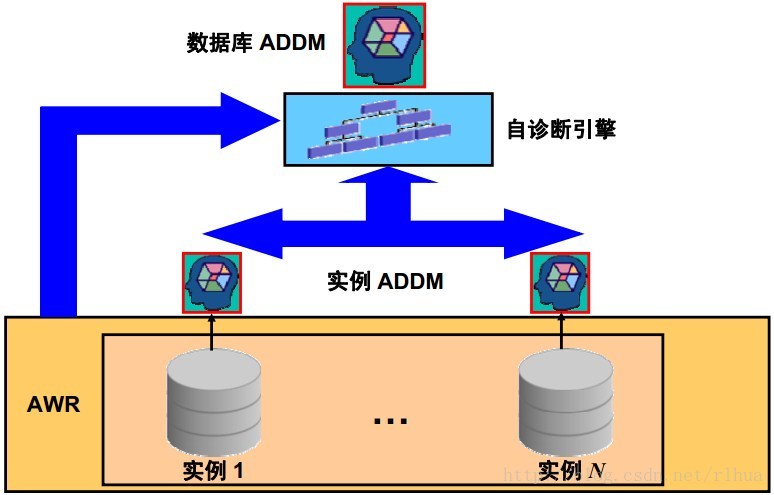
Oracle Database 11 g 对一系列功能进行了扩展,这些扩展的功能通过对整个集群内的性能进行分析提高了数据库的可管理性。自动数据库诊断监视器(ADDM) 的一种特殊模式可以分析Oracle Real Application Clusters (RAC) 数据库集群,并报告影响整个集群的问题以及影响单个实例的问题。这种模式称为“数据库ADDM”,与Oracle
Database 10 g 中已经存在的实例ADDM 相对。
RAC 的数据库ADDM 并不只是众多报表中的一个报表,它还有适用于 RAC 的独立分析。
- RAC 的自动数据库诊断监视器
• 确定整个RAC 集群数据库的最重要的性能问题
• 在生成AWR 快照时自动运行(默认设置)
• 在数据库范围内对以下项进行分析:
– 全局资源(例如,I/O 和全局锁)
– 高负载SQL 和热块
– 全局高速缓存互联通信量
– 网络等待时间问题
– 实例响应时间的偏差
• DBA 用来分析集群性能
RAC 的自动数据库诊断监视器
在Oracle Database 11 g 中,可以为ADDM 创建一个时段分析模式,用于分析整个集群的吞吐量性能。如果指导以此模式运行,则称为“数据库ADDM”。可以为单个实例运行指导;该指导等同于Oracle Database 10 g ADDM,现在称为“实例 ADDM”。数据库ADDM
可以访问所有实例生成的 AWR 数据,因而可以更加精确地分析全局资源。数据库ADDM 和实例 ADDM 都在连续的时段(可以包含实例启动和关闭)中运行。对于数据库ADDM,在分析期间可能会有多个关闭或启动的实例。但是,在整个时间段中必须保持数据库版本相同。
数据库ADDM 会在各个快照生成后自动运行。自动实例 ADDM 的运行方式与其在 Oracle Database 10 g 中的运行方式相同。也可以对集群中的一部分实例进行分析,这称为“部分分析ADDM”。
I/O 容量查找结果(I/O 系统过度使用)是一个全局查找结果,因为它关系到影响多个实例的全局资源。本地查找结果关系到影响单个实例的本地资源或问题。例如,CPU 绑定实例会产生有关CPU 的本地查找结果。
虽然可在应用程序开发过程中使用ADDM 来测试对应用程序、数据库系统或主机的更改,但ADDM 的目标用户是 DBA。
- EM 支持 RAC 的ADDM
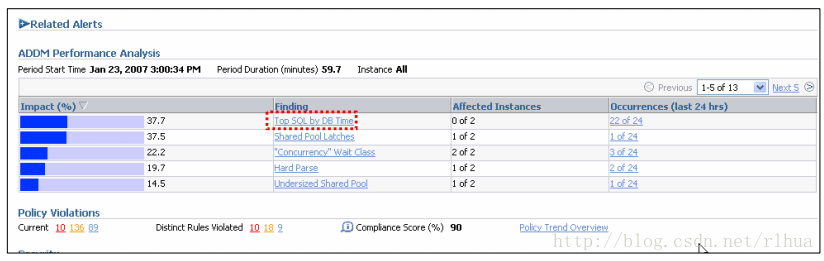
“Cluster Database(集群数据库)”主页:
EM 支持RAC 的ADDM
Oracle Database 11 g Enterprise Manager 可以在“Cluster Database (集群数据库)”主页上显示ADDM 分析。“Finding(查找结果)”表显示在“ADDM Performance Analysis(ADDM 性能分析)”部分。
对于每个查找结果,“Affected Instances(受影响的实例)”列将显示受影响的实例数量( m/n) 。显示内容还指明每个实例的影响百分比。对查找结果进行进一步的细化会将您带到“Performance Finding Details (性能查找结果详细资料)”页。
- EM 支持 RAC 的ADDM
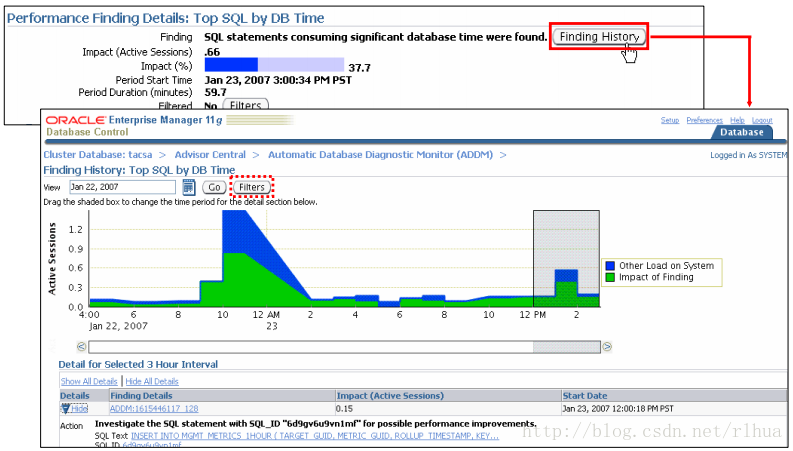
“Finding History(查找结果历史记录)”页:
EM 支持RAC 的ADDM (续)
在“Performance Finding Details (性能查找结果详细资料)”页上,单击“Finding History(查找结果历史记录)”按钮可看到一个页面,该页面上部有一个图,绘制出了随着时间的变化查找结果在活动会话中的影响。默认的显示时段为24 小时。下拉列表支持查看七天的信息。
在显示内容的底部显示了一个类似于结果部分的表,用于显示此指定查找的所有查找结果。可以在此页上设置查找结果的过滤器。不同类型的查找结果(CPU 、登录数、SQL 等)有不同种类的过滤标准。
注:对于查找结果历史记录,只考虑自动运行的 ADDM。这些结果仅反映未过滤的结果。
- 使用DBMS_ADDM 程序包

使用DBMS_ADDM 程序包
DBMS_ADDM 程序包可以简化ADDM 管理。该程序包包含以下过程和函数:
• ANALYZE_DB:创建一个ADDM 任务对数据库进行全局分析
• ANALYZE_INST:创建一个ADDM 任务对本地实例进行分析
• ANALYZE_PARTIAL:创建一个ADDM 任务对一部分实例进行分析
• DELETE :删除创建的ADDM 任务(任何种类)
• GET_REPORT:获取已执行的ADDM 任务的默认文本报表
• 参数1、2 :启动和结束快照
- 已命名的指导查找结果和指令
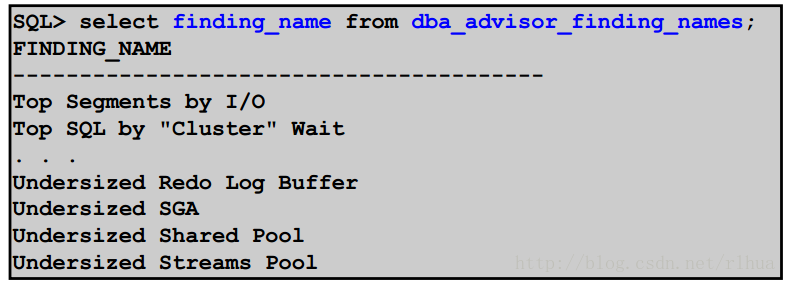
• 现在,已对指导结果进行了分类和命名:
– 存在于DBA{USER}_ADVISOR_FINDINGS视图中
• 可以通过DBA_ADVISOR_F INDING_NAMES视图查询所有查找结果名称:
已命名的指导查找结果和指令
Oracle Database 10 g 引入了指导框架和多种指导来帮助DBA 有效地管理数据库。这些指导提供查找结果形式的反馈。现在,Oracle Database 11 g 对这些查找结果进行了分类,这样您可以通过查询指导视图来了解指定类型的查找结果在数据库中重复出现的频率。以下指导视图中添加了一个FINDING_NAME列:
• DBA_ADVISOR_FINDINGS
• USER_ADVISOR_FINDINGS
新增的DBA_ADVISOR_FINDING_NAMES视图可以显示所有查找结果名称。
- 使用DBMS_ADDM 程序包
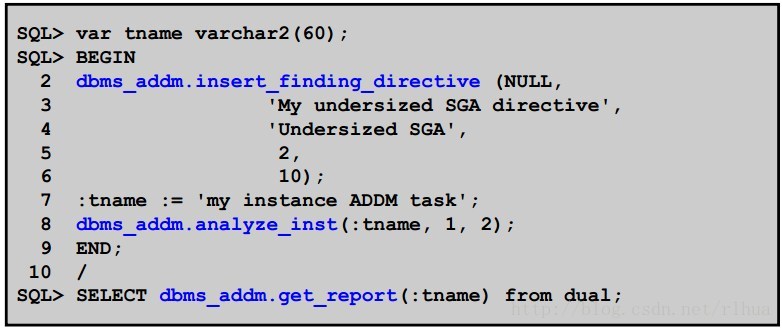
• 创建一个用于过滤“Undersized SGA (不够大的SGA)”查找结果的ADDM 指令:
• DBA_ADVISOR_F INDING_NAMES中的可能查找结果
使用DBMS_ADDM 程序包
可以使用可能的查找结果名称来查询查找结果资料档案库,以获取该特定查找结果的全部出现。
幻灯片中显示了使用查找结果指令创建实例ADDM 任务的过程。如果任务的名称为NULL,则该名称将应用于所有后续的ADDM 任务。查找结果名称“Undersized SGA (不够大的SGA )”必须在DBA_ADVISOR_FINDING_NAMES视图(列出了所有查找结果)中,并且区分大小写。仅当查找结果在分析期间至少涵盖两个(
min_active_sessions) 平均活动会话时,DBMS_ADDM.GET_REPORT的结果才会显示“Undersized SGA (不够大的SGA )”查找结果。即至少占该时段中数据库总时间的10% (
min_perc_impact) 。
- 使用DBMS_ADDM 程序包
• 添加指令的过程:
– INSERT_FINDING_DIRECTIVE
– INSERT_SQL_DIRECTIVE
– INSERT_SEGMENT_DIRECTIVE
– INSERT_PARAMETER_DIRECTIVE
• 删除指令的过程:
– DELETE_FINDING_DIRECTIVE
– DELETE_SQL_DIRECTIVE
– DELETE_SEGMENT_DIRECTIVE
– DELETE_PARAMETER_DIRECTIVE
使用DBMS_ADDM 程序包(续)
附加的PL/SQL 指令过程:
• INSERT_FINDING_DIRECTIVE:创建一个指令以限制特定查找结果类型的报告
• INSERT_SQL_DIRECTIVE:创建一个指令以限制对特定SQL 的操作的报告
• INSERT_SEGMENT_DIRECTIVE:创建一个指令以阻止ADDM 创建为特定段“运行段指导”的操作
• INSERT_PARAMETER_DIRECTIVE :创建一个指令以阻止ADDM 创建更改特定系统参数值的操作
• 参数的长语法将在此处再次发挥了作用。
• 如果指定了ALL ,则将报告指令。
- 修改的指导视图
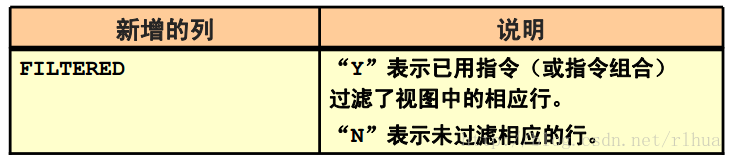
• 位于以下视图中:
– DBA_ADVISOR_FINDINGS
– USER_ADVISOR_FINDINGS
– DBA_ADVISOR_RECOMMENDATIONS
– USER_ADVISOR_RECOMMENDATIONS
– DBA_ADVISOR_ACTIONS
– USER_ADVISOR_ACTIONS
修改的指导视图
添加FILTERED 列增强了包含指导查找结果、建议案和操作的视图。
- 新增的ADDM 视图
• DBA{USER}_ADDM_TASKS:显示所有已执行的ADDM 任务;是对应指导视图的扩展
• DBA{USER}_ADD M_INSTANCES :显示已完成的ADDM 任务的实例级别信息
• DBA{USER}_ADDM_FINDINGS :是对应指导视图的扩展
DBA{USER}_ADD M_FDG_BREAKDOWN:显示来自数据库和部分ADDM 的不同实例的每个查找结果的作用
- Oracle Database 10g SGA 参数
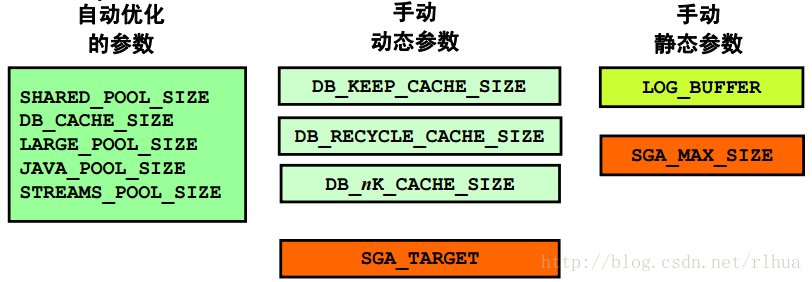
• 使用ASMM,可以自动优化五个重要的SGA 组件。
• 不会自动优化特殊的缓冲区池。
• 日志缓冲区是一个静态组件,但是有一个合适的默认值。
Oracle Database 10g SGA 参数
如幻灯片中所示,激活自动共享内存管理(ASMM) 时将自动优化五个最重要的池。这些参数称为“自动优化的参数”。
第二类称为“手动动态参数”,包括不必关闭实例就可手动调整大小但系统不会自动进行优化的参数。
最后一类是“手动静态参数”,包括大小固定且不先关闭实例就无法调整大小的参数。
- Oracle Database 10g PGA 参数
• PGA_AGGREGATE_TARGET:
– 指定可用于实例的 PGA 内存的目标总计数量
– 可在实例级别以动态方式进行修改
– 示例:100,000 KB、2,500 MB、50 GB
– 默认值:10 MB 或SGA 大小的 20%(取两者中较大的值)
• WORKAREA_SIZE_POLICY:
– 可选
– 可在实例级别或会话级别以动态方式进行修改
– 对特定会话退回到静态 SQL 内存管理
Oracle Database 10g PGA 参数
PGA_AGGREGATE_TARGET指定了可供与该实例关联的所有服务器进程使用的目标总PGA 内存。将PGA_AGGREGATE_TARGET设置为非零值时,会自动将WORKAREA_SIZE_POLICY参数设置为AUTO。这意味着会自动调整由占用大量内存的SQL
操作符使用的SQL 工作区大小。非零值是此参数的默认值,因为除非另行指定,否则Oracle 会将其设置为SGA 大小的20% 或10 MB (取两者中的较大值)。
将PGA_AGGREGATE_TARGET设置为0 时,也会自动将WORKAREA_SIZE_POLICY参数设置为MANUAL 。这意味着可使用*_AREA_SIZE 参数来调整SQL 工作区的大小。请记住,PGA_AGGREGATE_TARGET不是一个固定值。它用于帮助系统更有效地管理PGA
内存,但在必要的情况下,系统将超出该设置。可以根据每个数据库会话对WORK_AREA_SIZE_POLICY 进行更改,这样便可以按需要根据每个会话进行手动内存管理。例如,假定会话加载了大型导入文件,因此需要较大的sort_area_size。可以使用登录触发器为正在执行导入操作的帐户设置WORK_AREA_SIZE_POLICY
。如果WORK_AREA_SIZE_POLICY 为AUTO,PGA_AGGREGATE_TARGET设置为0,则在启动时将引发外部错误ORA-04032 。
注:在Oracle 9i Database 版本2 之前,PGA_AGGREGATE_TARGET一直用于控制所有专用服务器连接的工作区大小。但是,该参数对共享服务器连接没有影响;这种情况下优先使用*_AREA_SIZE 参数。在Oracle Database 10 g 中,PGA_AGGREGATE_TARGET控制由专用连接和共享连接分配的工作区。
- Oracle Database 10g 内存指导
• 缓冲区高速缓存建议(在9i R1 中引入):
– V$DB_CACHE_ADVICE
– 预测不同高速缓存大小的物理读取数和时间
• 共享池建议(在9i R2 中):
– V$SHARED_POOL_ADVICE
– 预测不同大小的共享池的解析时间
• Java 池建议(在9 i R2 中):
– V$JAVA_POOL_ADVICE
– 预测Java 池大小的 Java 类加载时间
• 流池建议(10 g R2)
– V$STREAMS_POOL_ADVICE
– 预测不同大小的溢出和未溢出活动时间
Oracle Database 10g 内存指导
为了帮助您调整最重要的SGA 组件的大小,Oracle Database 11 g 中引入了幻灯片中的指导:
• V$DB_CACHE_ADVICE包含的行预测与每行对应的高速缓存大小的物理读取数和时间。
• V$SHARED_POOL_ADVICE显示有关不同池大小的共享池中估计分析时间的信息。
• V$JAVA_POOL_ADVICE 显示有关不同池大小的Java 池中估计类加载时间的信息。
• V$STREAMS_POOL_ADVICE 显示有关估计的溢出或未溢出消息数,以及用于不同流池大小的溢出或未溢出活动的关联时间的信息。
- Oracle Database 10g 内存指导
• SGA 目标建议(在10g R2 中引入):
– V$SGA_TARGET_ADVICE 视图
– 根据当前大小估计不同 SGA 目标大小的 DB 时间
• PGA 目标建议(在9i R1 中引入):
– V$PGA_TARGET_ADVICE 视图
– 预测不同 PGA 大小的 PGA 高速缓存命中率
– 11g R1 中添加了 ESTD_TIME 时间列
• 对于所有指导,必须至少将STATISTICS_LEVEL 设置为TYPICAL。
Oracle Database 10g 内存指导(续)
• 在Oracle Database 10 g 中,SGA Advisor 会显示出 DB 时间的改善(可针对特定SGA 总大小设置实现此改善)。使用此指导可以减少在设置SGA 大小时反复试验的次数。指导数据存储在V$SGA_TARGET_ADVICE 视图中。
• V$PGA_TARGET_ADVICE 将预测,PGA_AGGREGATE_TARGET参数值的更改会对V$PGASTAT 性能视图显示的PGA 高速缓存命中率产生怎样的影响。预测是根据PGA_AGGREGATE_TARGET参数的多个值(围绕其当前值进行选择)来进行的。建议统计信息是通过模拟过去实例运行的工作量来生成的。11g
中新增了一列( ESTD_TIME) ,对应于处理字节所需的CPU 和I/O 时间。
- 自动内存管理:概览
自动内存管理:概览
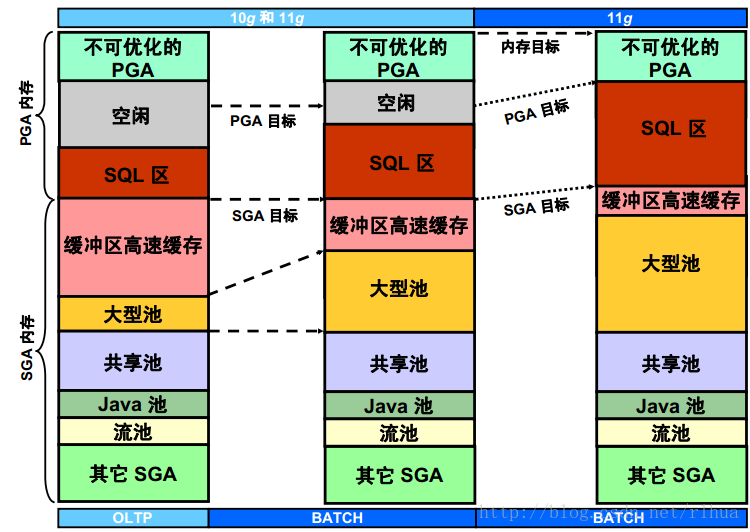
使用自动内存管理时,系统会导致内存发生从SGA 到PGA (或相反)的间接转移,并根据工作量自动调整PGA 和SGA 的大小。
这种间接的内存转移依赖于操作系统的共享内存释放机制。将内存释放给操作系统后,其它组件可以通过向操作系统请求内存来分配内存。
当前,Linux、Solaris 、HP-UX、AIX 和Windows 中已实现了这种功能。设置数据库实例的内存目标,将系统优化到目标内存大小,根据需要在系统全局区(SGA) 和总程序全局区(PGA) 之间重新分配内存。
此幻灯片显示了Oracle Database 10 g 机制与Oracle Database 11 g 新增的自动内存管理之间的差异。
- 自动内存管理:概览
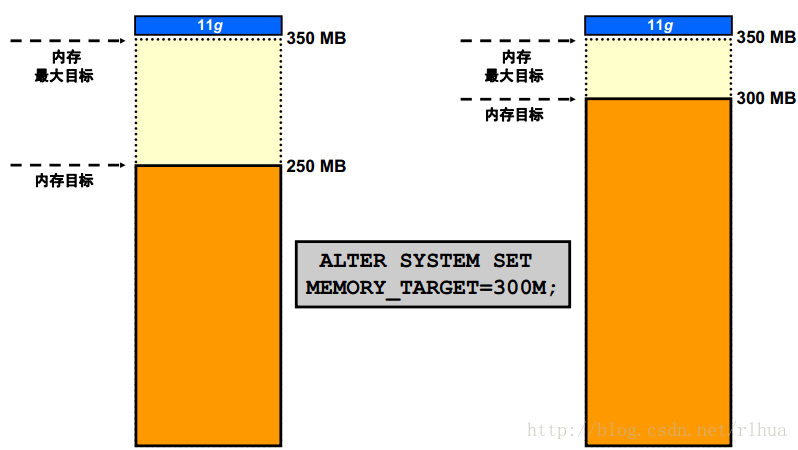
自动内存管理:概览(续)
最简单的内存管理方法是让数据库自动管理和优化内存。为此,在大多数平台上,需要仅设置一个目标内存大小初始化参数( MEMORY_TARGET ) 和一个最大内存大小初始化参数( MEMORY_MAX_TARGET) 。因为目标内存初始化参数是动态的,因此可以随时更改目标内存大小而不必重新启动数据库。最大内存大小相当于一个上限,以防您无意中将目标内存大小设置得太高。因为某些SGA
组件不容易收缩,或者其大小必须保持为最小,所以数据库还要防止您将目标内存大小设置得太低。
- Oracle Database 11g 内存参数
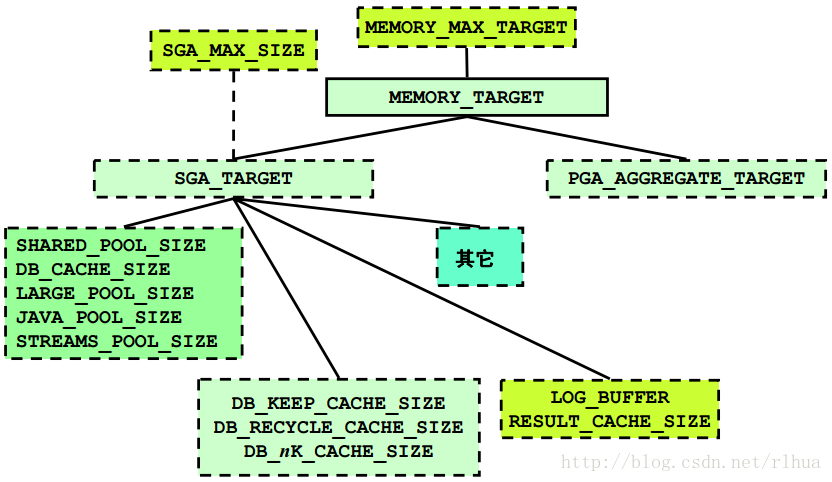
Oracle Database 11g 内存参数
该幻灯片显示了内存初始化参数的层次结构。虽然仅需要设置MEMORY_TARGET 来触发自动内存管理,但仍可以为各种高速缓存设置下限值。因此,如果用户设置了子参数,则这些子参数将是最小值,不会自动优化低于此值的组件。
- 自动内存参数依赖性
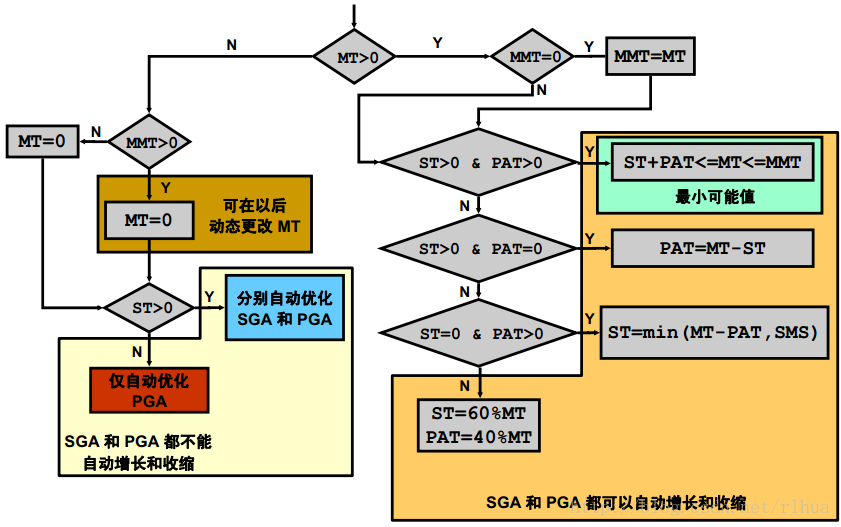
自动内存参数依赖性
该幻灯片展示了各个内存大小参数之间的关系。
MEMORY_TARGET 设置为非零值时:
• 如果设置了SGA_TARGET和PGA_AGGREGATE_TARGET,则会分别将它们当作SGA 大小和PGA 大小的最小值。MEMORY_TARGET 可以将SGA_TARGET +
PGA_AGGREGATE_TARGET的值作为MEMORY_MAX_SIZE。
• 如果设置了SGA_TARGET但未设置PGA_AGGREGATE_TARGET,则仍会自动优化这两个参数。PGA_AGGREGATE_TARGET将初始化为以下值:
(MEMORY_TARGET - SGA_TARGET) 。
• 如果设置了PGA_AGGREGATE_TARGET但未设置SGA_TARGET,则仍会自动优化这两个参数。SGA_TARGET将初始化为值min(MEMORY_TARGET -PGA_AGGREGATE_TARGET, SGA_MAX_SIZE(如果用户已设置)),系统将自动优化子组件。
• 如果未设置任何参数,则无需最小值或默认值即可自动优化这两个参数。有这样一个策略:在初始化过程中,将服务器的总内存按固定比率分配给SGA 和PGA 。该策略将在启动时分配60% 的内存给SGA ,40% 的内存给PGA 。
如果未设置MEMORY_TARGET ,或者将其显式设置为0(11g 中的默认值为0):
• 如果设置了SGA_TARGET,则系统仅自动优化SGA 的子组件大小。PGA 的自动优化与是否显式设置PAG 无关。但是,不会自动优化整个SGA ( SGA_TARGET) 和PGA ( PGA_AGGREGATE_TARGET) ,即SGA 和PGA 不会自动增长或收缩。如果既未设置SGA_TARGET,又未设置PGA_AGGREGATE_TARGET,则遵从当前的策略:自动优化PGA
,但不自动优化 SGA ;必须显式设置部分子组件的参数(对于SGA_TARGET)。
• 如果仅设置了MEMORY_MAX_TARGET,则使用文本初始化文件进行手动设置时,MEMORY_TARGET 默认为0。SGA 和PGA 的自动优化行为默认情况下与10g R2 中的相同。
• 如果SGA_MAX_SIZE不是用户设置的,则在用户设置了MEMORY_MAX_TARGET的情况下,系统会在内部将其设置为MEMORY_MAX_TARGET(与用户是否设置SGA_TARGET无关)。
在文本初始化参数文件中,如果省略了MEMORY_MAX_TARGET行,并包含了MEMORY_TARGET 的值,则数据库会自动将MEMORY_MAX_TARGET设置为MEMORY_TARGET 的值。如果省略了MEMORY_TARGET 行,并包含了MEMORY_MAX_TARGET的值,则MEMORY_TARGET
参数默认为零。启动后,可以将MEMORY_TARGET 动态更改为非零值,但该值不能超过MEMORY_MAX_TARGET的值。
图例:幻灯片中的参数名称缩写对应于以下名称:
• MT = MEMORY_TARGET
• MMT = MEMORY_MAX_TARGET
• ST = SGA_TARGET
• PAT = PGA_AGGREGATE_TARGET
• SMS = SGA_MAX_SIZE
- 启用自动内存管理
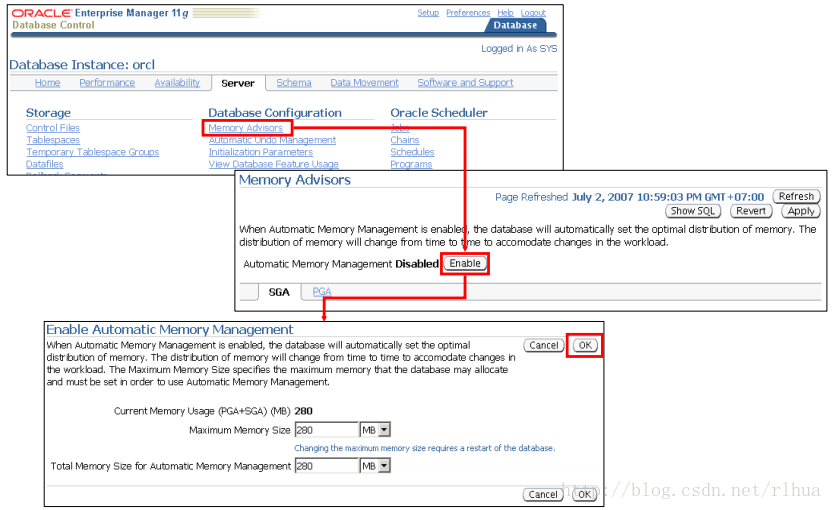
启用自动内存管理
可以使用Enterprise Manager 启用自动内存管理,如幻灯片中所示。
在“Database(数据库)”主页上,单击“Server (服务器)”选项卡。在“Server (服务器)”页上,单击“Database Configuration(数据库配置)”部分中的“Memory Advisors(内存指导)”链接。此时将进入“Memory Advisors(内存指导)”页。在此页上,可以单击“Enable
(启用)”按钮以启用自动内存管理。
“Total Memory Size for Au tomatic Memory Management(自动内存管理的内存总大小)”字段默认设置为当前的SGA + PGA 大小。可以将该字段设置为大于该值但小于“Maximum Memory Size(最大内存大小)”值的任何值。
注:在“Memory Advisors(内存指导)”页上,也可以指定“Maximum Memory Size(最大内存大小)”。如果更改了此字段,则必须自动重新启动数据库使更改生效。
- 监视自动内存管理
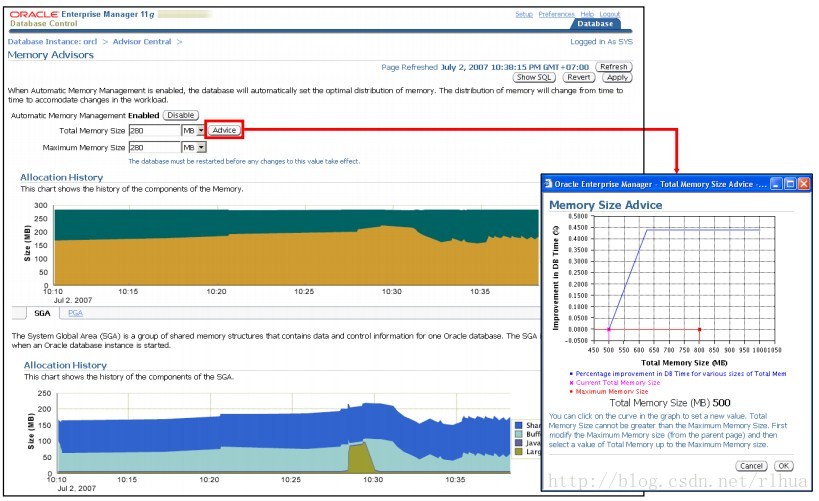
监视自动内存管理
如果启用了自动内存管理,则可以在“Memory Parameters(内存参数)”页的“Allocation History(分配历史记录)”部分看到新增的内存大小组件历史记录图形。第一个图形中的绿色部分代表PGA ,黄褐色部分代表全部 SGA 。下方矩形图中的深蓝色部分代表“Shared Pool
(共享池)”大小;浅蓝色部分代表“Buffer Cache(缓冲区高速缓存)”。
幻灯片中的变化显示了执行多个苛刻的查询后可能发生的内存重新分区情况。SGA 和PGA 都可能因此而收缩。请注意,SGA 收缩时,其子组件也会在大约相同的时间收缩。
在此页上,还可以通过单击“Advice (建议)”按钮访问内存目标指导。此指导将提供对于各种内存总大小可能的DB 时间改善。
注:V$MEMORY_TARGET_ADVICE将显示MEMORY_TARGET 初始化参数的优化建议。
- 监视自动内存管理
如果要从命令行监视自动内存管理做出的决定:
• V$MEMORY_DYNA MIC_COMPONENTS 包含所有内存组件的当前状态
• V$MEMORY_RESIZE_OPS 包含最近完成的800 个内存大小调整请求的循环历史记录缓冲区
• V$MEMORY_CURR ENT_RESIZE_OPS 包含当前的内存大小调整操作
• 为了具有向后兼容性,保留了所有SGA 和PGA 对等项
下列视图提供有关动态调整大小操作的信息:
• V$MEMORY_DYNAMIC_COMPONENTS显示有关所有动态优化的内存组件的信息,其中包括SGA 和PGA 的总大小。
• V$MEMORY_RESIZE_OPS 显示有关最近完成的800 个内存大小调整操作(自动和手动)的信息,不包括正在进行的操作。
• V$MEMORY_CURRENT_RESIZE_OPS显示有关当前正在进行的内存大小调整操作(自动和手动)的信息。
• V$SGA_CURRENT_RESIZE_OPS 显示有关当前正在进行的SGA 大小调整操作的信息。操作可以是增加或收缩动态SGA 组件。
• V$SGA_RESIZE_OPS 显示有关最近完成的800 个SGA 大小调整操作的信息,不包括当前正在进行的操作。
• V$SGA_DYNAMIC_COMPONENTS 显示有关SGA 中动态组件的信息。此视图基于启动后完成的所有SGA 大小调整操作来汇总信息。
• V$SGA_DYNAMIC_FREE_MEMORY显示有关将来动态SGA 大小调整操作可用的SGA 内存量的信息。
- DBCA 和自动内存管理
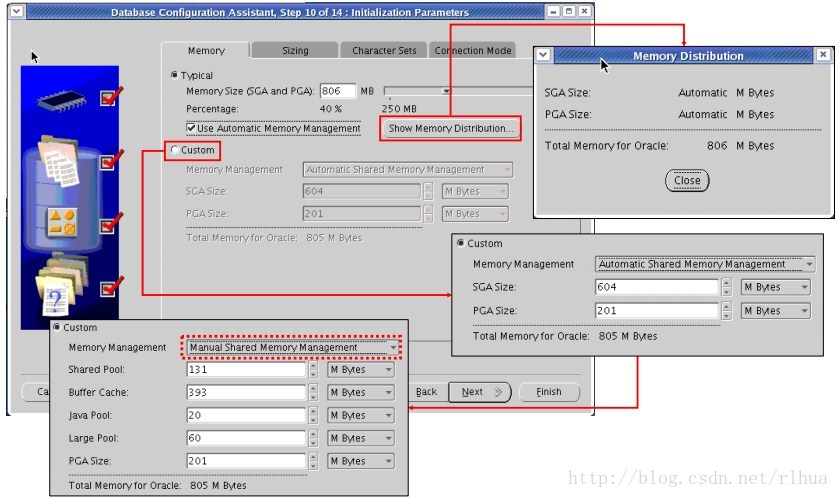
DBCA 和自动内存管理
使用Oracle Database 11 g,DBCA 可以使用一些新选项来调整自动内存管理(AMM)。使用“Initialization Parameters (初始化参数)”页上的“Memory(内存)”选项卡可以设置初始化参数,以控制数据库管理其内存使用状况的方式。可以选择两种基本的内存管理方式之一:
• Typical(典型):所需的配置很少,数据库可以管理使用系统总内存的百分比的方式。选中“Typical(典型)”将创建一个具有最低配置或最少用户输入的数据库。对于大多数环境以及不熟悉高级数据库创建过程的DBA 来说,此选项已经足够了。在“Memory
Size(内存大小)”字段中输入一个值(以MB 为单位)。要使用AMM,请在该页的“Typical(典型)”部分选中相应的选项。未选中AMM 选项时,单击“Show Memory Distribution(显示内存分布)”可查看DBCA 分配给SGA 和PGA
的内存数量。
• Custom(定制)(使用或不使用ASMM):需要较多的配置,但增加了对数据库如何使用可用系统内存的控制。要为SGA 和PGA 分配特定的内存数量,请选择“Automatic(自动)”。要定制SGA 内存在 SGA 内存结构(缓冲区高速缓存、共享池等)中的分布方式,请选择“Manual(手动)”,然后为每个SGA
子组件输入特定的值。稍后在DBCA 中复查和修改这些初始化参数。
注:使用DBCA 或手动创建DB 时,MEMORY_TARGET 参数将默认为0。
- 统计信息首选项:概览
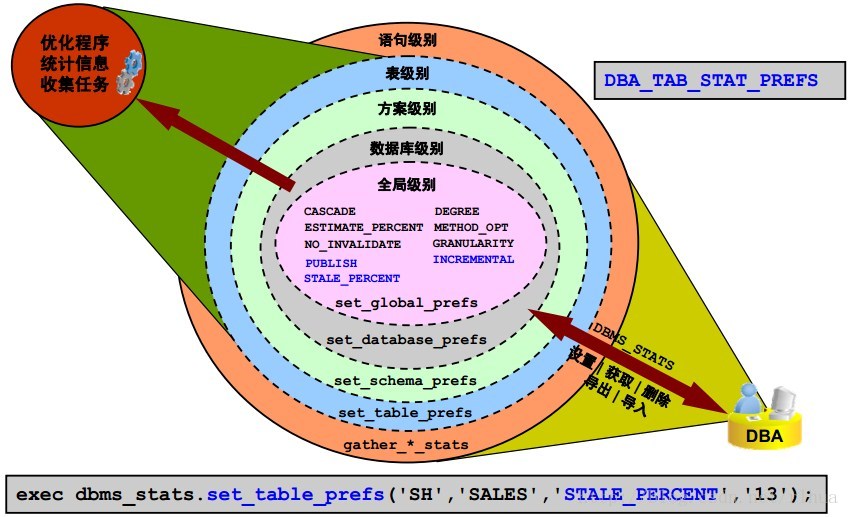
统计信息首选项:概览
自动统计信息收集功能是在Oracle Database 10 g 版本1 中引入的,用于减轻维护优化程序统计信息的工作。但是,在有些情况下,必须禁用该功能,并运行自己的脚本。其中的一个原因是缺少对象级别的控制。只要发现一小部分对象的默认收集统计信息选项的效果不佳,就必须锁定统计信息,并使用您自己的选项单独对其进行分析。例如,对于其中数据的频率具有很大偏差的列,自动尝试确定足够样本大小的功能(
ESTIMATE_PERCENT=AUTO_SAMPLE_SIZE ) 的效果就不太好。解决此问题的唯一方法就是用自己的脚本手动指定样本大小。
Oracle Database 11 g 中的统计信息首选项功能具有一定的灵活性,因此,如果有些对象需要不同于数据库默认设置的设置,则可以更多地依赖自动统计信息收集功能来维护优化程序统计信息。
通过此功能,您可以在对象级别或方案级别,将覆盖GATHER_* _STATS 过程的默认行为的统计信息收集选项与自动优化程序统计信息收集任务关联起来。DBA 可以使用DBMS_STATS程序包管理幻灯片中显示的收集统计信息选项。
一般情况下,可以在表、方案、数据库和全局等级别设置、获取、删除、导出和导入这些首选项。全局首选项用于没有首选项的表,而数据库首选项则用于设置针对所有表的首选项。以各种方式指定的首选项值的优先顺序为从外圈到内圈(如幻灯片中所示)。
最后三个突出显示的选项是Oracle Database 11 g 版本1 中的新增选项:
• PUBLISH用于确定是将统计信息发布到字典还是先将其存储在临时等待区中。
• STALE_PERCENT 用于确定阈值级别,系统认为该级别的对象拥有过时的统计信息。
该值是上次收集统计信息以来修改过的行数的百分比。示例仅将SH.SALES 的默认值10% 更改为13% 。
• INCREMENTAL 用于以递增方式收集有关分区表的全局统计信息。
注:可以使用 DBA_TAB_STAT_PREFS 视图说明所有相关表的全部有效统计信息首选项设置。
- 使用Enterprise Manager 设置全局首选项
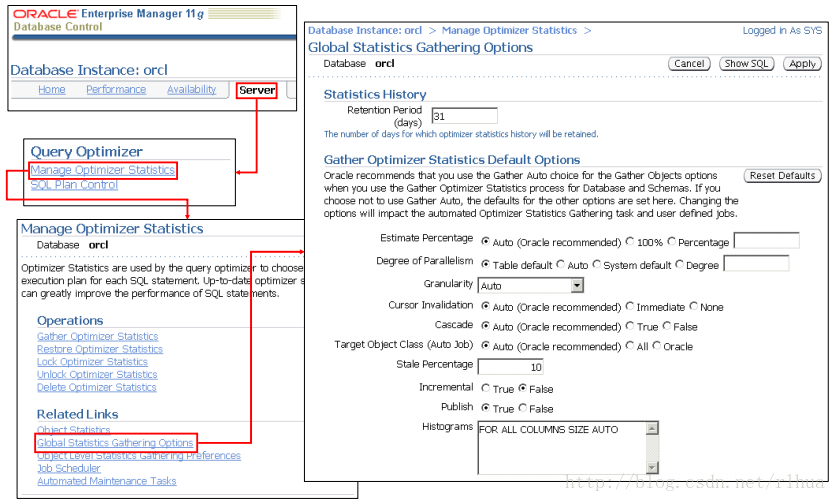
使用Enterprise Manager 设置全局首选项
可以使用Enterprise Manager 来控制全局首选项设置。可以在“Manage Optimizer Statistics(管理优化程序统计信息)”页上执行此操作;此页的访问方法如下:在“Database(数据库)”主页上单击“Server (服务器)”选项卡,然后单击“Manage Optimizer
Statistics(管理优化程序统计信息)”链接,再单击“Global Statistics Gathering Options(全局统计信息收集选项)”链接。
在“Global Statistics Gathering Options(全局统计信息收集选项)”页上,在“Gather Optimizer Statistics Default Options(收集优化程序统计信息默认选项)”部分更改全局首选项。完成后,单击“Apply(应用)”按钮。
注:要在对象级别或方案级别更改统计信息收集选项,请在“Manage Optimizer Statistics(管理优化程序统计信息)”页上单击“Object Level Statistics Gathering Preferences (对象级别统计信息收集首选项)”链接。
- 分区表和增量统计信息:概览
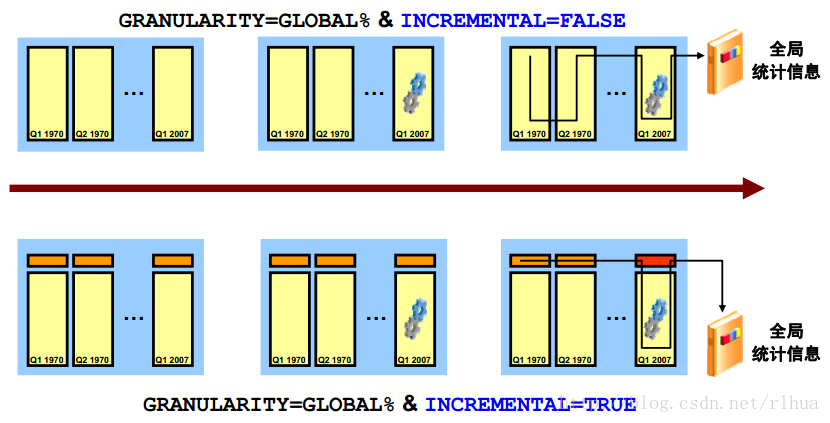
分区表和增量统计信息:概览
对于分区表,系统会维护每个分区上的统计信息和表的整体统计信息。一般情况下,如果使用日期范围值对表进行了分区,则进行数据修改(DML) 的分区会非常少。例如,假定有一个存储销售事务处理的表。您可以根据销售日期对表进行分区,每个分区包含一个季度的事务处理。大多数DML
活动都发生在存储当前季度事务处理的分区上。其它分区中的数据将保持不变。系统当前跟踪的是表级别和(子)分区级别的DML 监视信息。仅为自上次收集统计信息以来已发生了显著更改(当前阈值为10% )的那些分区(幻灯片的示例中为当前季度的分区)收集统计信息。但是,全局统计信息是通过扫描整个表来收集的,这使得收集分区表的统计信息的开销很大,特别是在有些分区存储在低速设备中并且不经常修改时。
Oracle Database 11 g 可以加快某些全局统计信息(如不同值的数量)的收集速度。与扫描整个表的传统方式不同,有一种新的机制可以定义全局统计信息;这种机制只扫描发生了更改的那些分区,而继续使用以前为未更改的那些分区收集的统计信息。简而言之,可对这些全局统计信息进行增量维护。
当前可以使用DBMS_STATS程序包来指定分区表的粒度。例如,可以指定自动、全局、全局和分区、全部、分区以及子分区。如果指定的粒度包括GLOBAL (全局),并且表的收集选项被标记为INCREMENTAL (增量),则使用增量机制收集全局统计信息。此外,不管是否指定了PARTITION(分区)粒度,都会收集已更改分区的统计信息。
注:新的机制不以增量方式维护直方图和密度全局统计信息。
- 基于散列的列统计信息采样
• 计算列统计信息是统计信息收集过程中开销最大的步骤。
• 行采样技术提供的是带偏差数据分布的不精确结果。
• 在将ESTIMATE_PERCENT 设置为AUTO_SAMPLE_SIZE时使用新的近似计数技术。
– 推荐使用 AUTO_SAMPLE_SIZE。
• 其它情况下,使用旧的行采样技术。
基于散列的列统计信息采样
对于查询优化,必须准确估计不同值的数量。默认情况下,如果没有直方图,优化程序将使用不同值的数量来估计列谓词的选择性。Oracle Database 10 g 使用的算法利用一个SQL 语句来计算不同值的数量;该语句可以计算基础表样本中存在的不同值数量。使用Oracle Database
10 g,可以在收集列统计信息时使用两个选项:
1. 使用小样本大小,这样得到的结果虽然精确度较低,但可缩短执行时间。
2. 使用大样本或全表扫描,这将获得很精确的结果,但执行时间很长。
在Oracle Database 11 g 中有一种收集列统计信息的新方法,其精确度与扫描接近,执行时间等于小样本的执行时间(1% 至5%)。如果从DBMS_STATS调用某个过程,并且已将ESTIMATE_PERCENT 收集选项设置为AUTO_SAMPLE_SIZE (默认设置),则会使用这项新技术。如果您指定了AUTO_SAMPLE_SIZE
以外的其它值,则将使用基于行采样的算法来收集不同值的数量。这样可以在指定采样百分比时保留旧的行为。
注:使用Oracle Database 11 g 时,建议使用AUTO_SAMPLE_SIZE 。新的估算机制修复了Oracle Database 10 g 中以下最常遇到的问题:
• 自动选项停止得太早,并且生成了不准确的统计信息,用户指定的样本大小大于自动使用的样本大小。
• 自动选项停止得太晚,性能很差,用户指定的样本大小小于自动使用的样本大小。
- 多列统计信息:概览
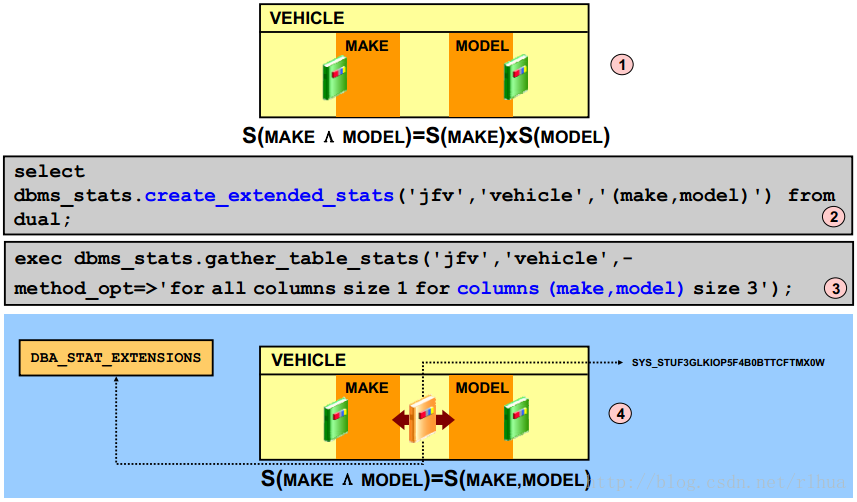
多列统计信息:概览
使用Oracle Database 10 g 时,在以下有限的情况下,查询优化程序在计算多个谓词的选择性时,将考虑列之间的相互关系:
• 如果连接谓词的所有列与连接索引键的所有列匹配,并且谓词是等值联接中的等式,则优化程序将使用索引中的不同键(NDK) 数量来估计选择性 (1/NDK) 。
• 如果将DYNAMIC_SAMPLING 设置为级别4 ,则查询优化程序将使用动态采样来估计涉及同一个表中多个列的复杂谓词的选择性。但是,样本的大小很小,并且解析时间有所增加。因此,样本的统计信息可能不准确,因此可能会弊大于利。
在其它所有情况下,优化程序将假定复杂谓词中所用的列的值互不相关。优化程序会通过将各个谓词中的选择性相乘来估计连接谓词的选择性。这种方式势必会低估选择性。为了避开此问题,Oracle Database 11 g 允许收集、存储和使用以下统计信息来捕获两个或更多列(也称为列组)之间的功能相关性:不同值的数量、Null
值的数量、频率直方图和密度。
例如,假定有一个VEHICLE表,其中存储了有关汽车的信息。MAKE 列和MODEL列是高度相关的,并且由MODEL决定MAKE。这是一种很强的依赖关系,优化程序应将这两个列看成是高度相关的两个列。可以使用CREATE_EXTENDED_STATS 函数将该关系传送给优化程序(如幻灯片上的示例所示),然后计算所有列的统计信息(包括创建的相关组的统计信息)。
注:
• CREATE_EXTENDED_STATS 函数会返回一个虚拟的隐藏列名称,如SYS_STUW_5RHLX443AN1ZCLPE_GLE4。
• 根据幻灯片中的示例,可以使用以下SQL 确定名称:select dbms_stats.show_extended_stats_name('jfv','vehicle','(make,model)')
from dual
• 创建以后,可以使用ALL | DBA | USER_STAT_EXTENSIONS视图检索统计信息扩展。
- 表达式统计信息:概览
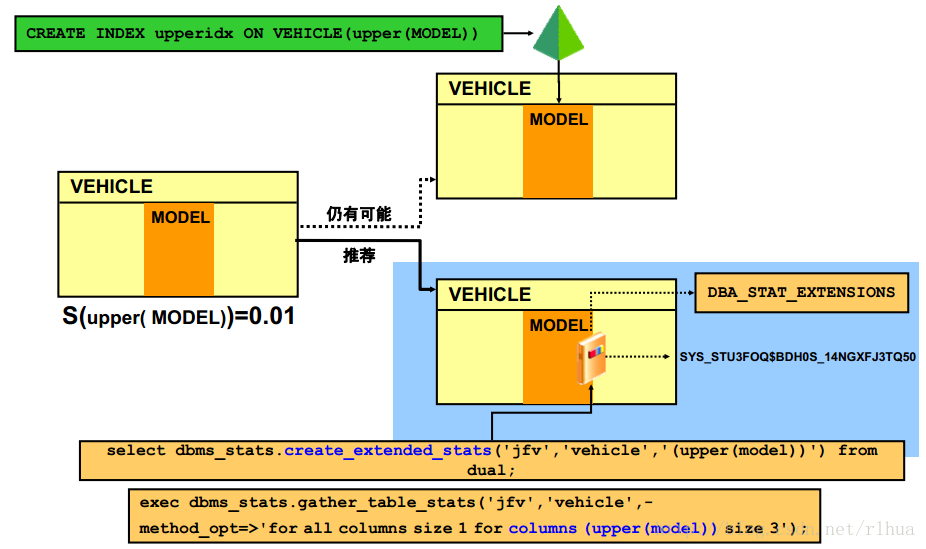
表达式统计信息:概览
与列表达式相关的谓词是查询优化程序的一个重要的问题。计算function(Column) =constant 形式的谓词的选择性时,优化程序将假定静态选择性值为1%。很明显,这种方式是错误的,会导致优化程序生成不是最理想的计划。
查询优化程序已得到了扩展,可以在有限的情况下更好地处理此类谓词。在这些情况下,函数将保留列的数据分布特征,因而允许优化程序使用列统计信息。例如,TO_NUMBER 就是此类函数之一。
为了在查询优化过程中对内置函数求值,以便使用动态采样来获得更好的选择性,进一步增强了相应的功能。最后,优化程序将收集所创建的虚拟列的统计信息以支持基于函数的索引。
但是,这些解决方案或者局限于特定的函数类,或者仅适合于用于创建基于函数的索引的表达式。通过使用Oracle Database 11 g 中的表达式统计信息,您可以使用更加全面的解决方案;这些解决方案包括了用户定义的任意函数,并且与是否存在基于函数的索引无关。如幻灯片中的示例所示,此功能将依靠虚拟列基础结构来创建列表达式的统计信息。
- 延迟统计信息发布:概览
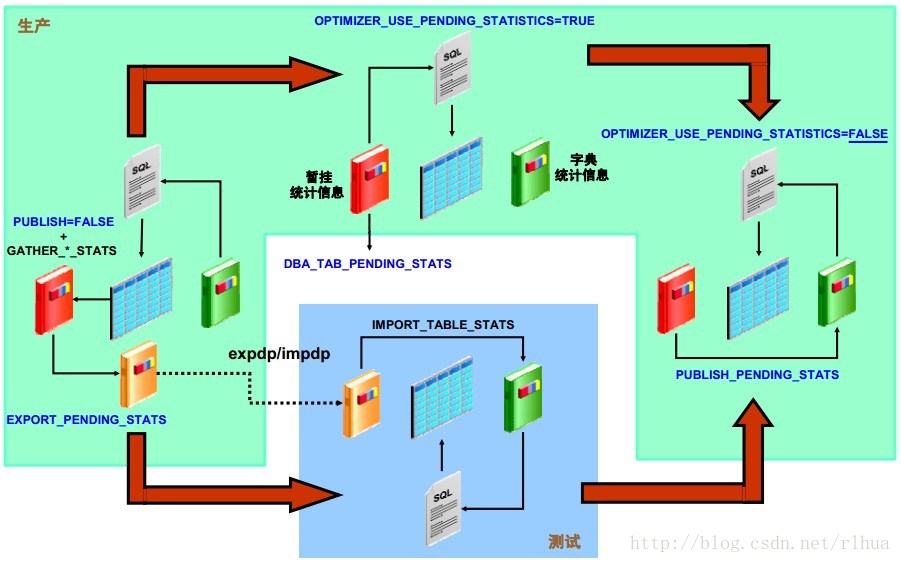
延迟统计信息发布:概览
默认情况下,统计信息收集操作每次完成一个对象(表、分区、子分区或索引)的迭代时,都会自动将新的统计信息存储在数据字典中。优化程序会在这些新的统计信息写入到数据字典中时立即发现它们;这些新的统计信息称为“当前统计信息”。这种自动发布功能可能会给DBA
造成困扰,因为永远无法确定新统计信息在几天或几个星期后会是什么状态。此外,优化程序所用的统计信息可能会不一致;例如,如果表统计信息的发布时间早于其索引、分区或子分区的统计信息的发布时间,就会出现统计信息不一致的情况。要避免这些潜在的问题,在Oracle
Database 11 g 版本1 中,可以将优化程序统计信息的收集步骤与发布步骤中相分离。将这两个步骤分离有两个优点:
• 支持作为原子事务处理的统计信息收集操作。方案中的所有表和从属对象(索引、分区、子分区)的统计信息将在同一时间发布。这种新的模式有两个有利的属性:优化程序将始终有一个一致的统计信息视图;如果收集步骤在收集过程中由于某种原因而失败,则当使用DBMS_STAT.RESUME_GATHER_STATS
过程重新启动该步骤时,可以从中断的位置继续操作。
•DBA 可以通过使用测试系统上新收集的统计信息运行所有或部分工作量来验证新统计信息;如果对测试结果感到满意,则继续执行发布步骤使这些统计信息成为生产环境中的当前统计信息。
将收集选项PUBLISH指定为FALSE时,收集的统计信息将存储在暂挂统计信息表中,而不会成为当前统计信息。可通过一些视图访问这些暂挂统计信息:{ALL | DBA |USER}_{ TAB | COL | IND | TAB_HISTGRM }_PENDING_STATS。
要测试暂挂统计信息,您有两种选择:
• 使用新的DBMS_STAT.EXPORT_PENDING_STATS过程,将暂挂统计信息传送至自己的统计信息表,从可以重新导入统计信息表的位置将其导出到测试系统,然后使用DBMS_STAT.IMPORT_TABLE_STATS 过程将暂挂统计信息作为当前统计信息呈现。
• 通过将会话初始化参数OPTIMIZER_USE_PENDING_STATISTICS更改为TRUE,启用会话暂挂统计信息。默认情况下,这个新的初始化参数被设置为FALSE。这意味着,在您的会话中将使用当前优化程序统计信息来分析SQL 语句。通过在会话中将该参数设置为TRUE,可以切换为暂挂统计信息。如果测试了暂挂统计信息后对其感到满意,则可使用新的DBMS_STAT.PUBLISH_PENDING_STATS
过程在生产环境中将其发布为当前统计信息。
- 延迟统计信息发布:示例

延迟统计信息发布:示例
1. 使用SET_TABLE_PREFS过程将PUBLISH选项设置为FALSE。这将阻止下一个统计信息收集操作自动将统计信息发布为当前统计信息。根据第一条语句,此情况仅对SH.CUSTOMERS表有效。
2. 在字典的临时等待区中收集SH.CUSTOMERS表的统计信息。
3. 通过将OPTIMIZER_USE_PENDING_STATISTICS设置为TRUE,从会话中测试新的暂挂统计信息集。
4. 发布对SH.CUSTOMERS的查询。
5. 如果对测试结果感到满意,则使用PUBLISH_PENDING_STATS 过程将SH.CUSTOMERS的暂挂统计信息作为当前统计信息呈现。
注:要分析暂挂统计信息与当前统计信息之间的差异,可以将暂挂统计信息导出到自己的统计信息表,然后使用新增的DBMS_STAT.DIFF_TABLE_STATS 函数。
- 小结
• 使用ADDM 的新功能
• 使用自动内存管理
• 使用统计信息增强功能