本文为作者原创,转载请注明出处(http://www.cnblogs.com/mar-q/)by 负赑屃
写在前面:
请参考之前的文章安装好CentOS、NVIDIA相关驱动及软件、docker及加速镜像。
主机运行环境
$ uname -a Linux CentOS 3.10.0-514.26.2.el7.x86_64 #1 SMP Tue Jul 4 15:04:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux $ cat /usr/local/cuda/version.txt CUDA Version 8.0.61 $ cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2 #define CUDNN_MAJOR 6 #define CUDNN_MINOR 0 #define CUDNN_PATCHLEVEL 21 #define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL) #include "driver_types.h" # NVIDIA 1080ti
一、关于GPU的挂载
1. 在docker运行时指定device挂载
先查看一下有哪些相关设备
$ ls -la /dev | grep nvidia crw-rw-rw- 1 root root 195, 0 Nov 15 13:41 nvidia0 crw-rw-rw- 1 root root 195, 1 Nov 15 13:41 nvidia1 crw-rw-rw- 1 root root 195, 255 Nov 15 13:41 nvidiactl crw-rw-rw- 1 root root 242, 0 Nov 15 13:41 nvidia-uvm crw-rw-rw- 1 root root 242, 1 Nov 15 13:41 nvidia-uvm-tools
电脑上装了两个显卡。我需要运行pytorch,dockerhub中pytorch官方镜像没有gpu支持,所以只能先pull一个anaconda镜像试试,后面可以编排成Dockerfile。
$ docker run -it -d --rm --name pytorch -v /home/qiyafei/pytorch:/mnt/home --privileged=true --device /dev/nvidia-uvm:/dev/nvidia-uvm --device /dev/nvidia1:/dev/nvidia1 --device /dev/nvidiactl:/dev/nvidiactl okwrtdsh/anaconda3 bash
okwrtdsh的镜像似乎是针对他们实验室GPU环境的,有点过大了,不过勉强运行一下还是可以的。在容器内部还需要安装pytorch:
$ conda install pytorch torchvision -c pytorch
这里运行torch成功,但是加载显卡失败了,可能还是因为驱动不匹配的原因吧,需要重新安装驱动,暂时不做此尝试;
二、通过nvidia-docker在docker内使用显卡

(1)安装nvidia-docker
nvidia-docker其实是docker引擎的一个应用插件,专门面向NVIDIA GPU,因为docker引擎是不支持NVIDIA驱动的,安装插件后可以在用户层上直接使用cuda。具体看上图。这个图很形象,docker引擎的运行机制也表现出来了,就是在系统内核之上通过cgroup和namespace虚拟出一个容器OS的用户空间,我不清楚这是否运行在ring0上,但是cuda和应用确实可以使用了(虚拟化的问题,如果关心此类问题可以了解一些关于docker、kvm等等虚拟化的实现方式,目前是系统类比较火热的话题)
下载rpm包:https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.1/nvidia-docker-1.0.1-1.x86_64.rpm
这里也可以通过添加apt或者yum sourcelist的方式进行安装,但是我没有root权限,而且update容易引起docker重启,如果不是实验室的个人环境不推荐这么做,防止破坏别人正在运行的程序(之前公司一个小伙子就是在阿里云上进行了yum update,结果导致公司部分业务停了一个上午)。
$ sudo rpm -i nvidia-docker-1.0.1-1.x86_64.rpm && rm nvidia-docker-1.0.1-1.x86_64.rpm $ sudo systemctl start nvidia-docker
(2)容器测试
我们还需要NVIDIA官方提供的docker容器nvidia/cuda,里面已经编译安装了CUDA和CUDNN,或者直接run,缺少image的会自动pull。
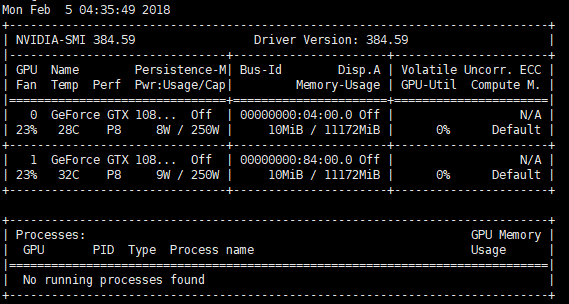
$ docker pull nvidia/cuda $ nvidia-docker run --rm nvidia/cuda nvidia-smi
在容器内测试是可以成功使用nvidia显卡的:
(3)合适的镜像或者自制dockerfile
- 合适的镜像:这里推荐Floydhub的pytorch,注意对应的cuda和cudnn版本。
docker pull floydhub/pytorch:0.3.0-gpu.cuda8cudnn6-py3.22 nvidia-docker run -ti -d --rm floydhub/pytorch:0.3.0-gpu.cuda8cudnn6-py3.22 bash

.png)
- 自制dockerfile
首先,我们需要把要装的东西想清楚:
1. 基础镜像肯定是NVIDIA官方提供的啦,最省事,不用装cuda和cudnn了;
2. vim、git、lrzsz、ssh这些肯定要啦;
3. anaconda、pytorch肯定要啦;
所以需要准备好国内源source.list,否则安装速度很慢。
deb-src http://archive.ubuntu.com/ubuntu xenial main restricted #Added by software-properties deb http://mirrors.aliyun.com/ubuntu/ xenial main restricted deb-src http://mirrors.aliyun.com/ubuntu/ xenial main restricted multiverse universe #Added by software-properties deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted multiverse universe #Added by software-properties deb http://mirrors.aliyun.com/ubuntu/ xenial universe deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe deb http://mirrors.aliyun.com/ubuntu/ xenial multiverse deb http://mirrors.aliyun.com/ubuntu/ xenial-updates multiverse deb http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverse #Added by software-properties deb http://archive.canonical.com/ubuntu xenial partner deb-src http://archive.canonical.com/ubuntu xenial partner deb http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted multiverse universe #Added by software-properties deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe deb http://mirrors.aliyun.com/ubuntu/ xenial-security multiverse
下载anaconda的地址:https://repo.continuum.io/archive/Anaconda3-5.0.1-Linux-x86_64.sh,这里直接在Dockerfile里下了,具体如下:
$ vim Dockerfile
FROM nvidia/cuda LABEL author="qyf" ENV PYTHONIOENCODING=utf-8 RUN mv /etc/apt/sources.list /etc/apt/sources.list.bak ADD $PWD/sources.list /etc/apt/sources.list RUN apt-get update --fix-missing && apt-get install -y vim net-tools curl wget git bzip2 ca-certificates libglib2.0-0 libxext6 libsm6 libxrender1 mercurial subversion apt-transport-https software-properties-common RUN apt-get install -y openssh-server -y RUN echo 'root:passwd' | chpasswd RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed -i 's/#PasswordAuthentication yes/PasswordAuthentication yes/' /etc/ssh/sshd_config RUN echo 'export PATH=/opt/conda/bin:$PATH' > /etc/profile.d/conda.sh && wget --quiet https://repo.continuum.io/archive/Anaconda3-5.0.1-Linux-x86_64.sh -O ~/anaconda.sh && /bin/bash ~/anaconda.sh -b -p /opt/conda && rm ~/anaconda.sh ENV PATH /opt/conda/bin:$PATH RUN conda install pytorch torchvision -c pytorch -y ENTRYPOINT [ "/usr/bin/tini", "--" ] CMD [ "/bin/bash" ]
通过docker build构造镜像:
docker build -t pytorch/cuda8 ./
运行成功调用cuda。
.png)
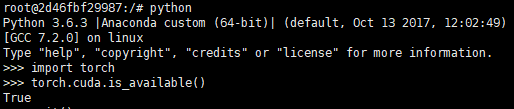
三、关于一些bug
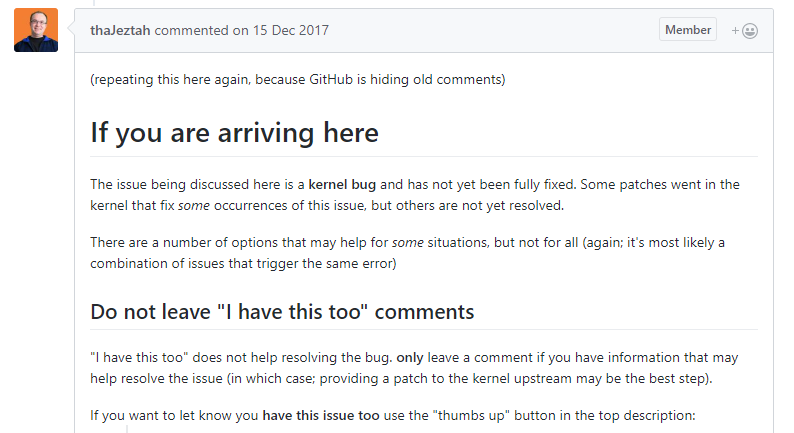
这里有部分debian的配置,我照着dockerhub上anaconda镜像抄的,这里就不再配置了,反正跑起来后有镜像也可以用。系统随后可能会出现错误:
kernel:unregister_netdevice: waiting for lo to become free. Usage count = 1
.png)
这是一个Ubuntu的内核错误,截止到到目前为止似乎还没完全解决。
.png)
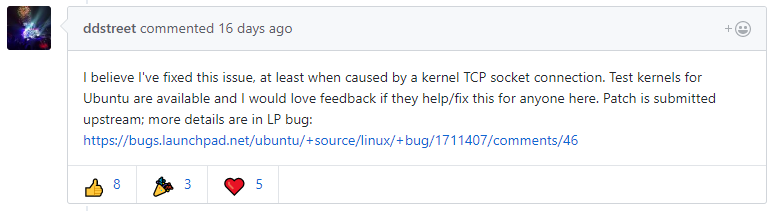
这个小哥给出了一个解决方案,至少他给出的错误原因我是相信的:是由内核的TCP套接字错误引发的。这里我给出一些思考,关于上面的结构图,在显卡上,通过nvidia-docker,docker之上的容器可以使用到底层显卡(驱动显然是在docker之下的),而TCP套接字,我猜测也是这种使用方法,而虚拟出来的dockerOS,应该是没有权限来访问宿主机内核的,至少内核限制了部分权限。这位小哥给出了测试内核,如果有兴趣可以去帮他测试一下:https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1711407/comments/46。