欢迎关注WX公众号:【程序员管小亮】
专栏——TensorFlow学习笔记
文章目录
下面我们准备使用 Keras 中预定义的经典卷积神经网络结构进行迁移学习。
一、数据处理
1.1_下载数据集
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
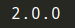
print(tf.__version__)
tensorflow_datasets 中包含了许多数据集,我们可以按照需求添加自己的数据集,下面列出所有可用的数据集:
import tensorflow_datasets as tfds
print(tfds.list_builders())

这里即将使用的 tf_flowers 数据集,其大小为 218MB,返回值为 FeaturesDict 对象,尚未进行分割。
- 由于该数据集尚未定义标准分割形式,首先将利用
subsplit函数将数据集分割为三部分,80% 用于训练,10% 用于验证,10% 用于测试; - 其次如果想加载整个数据集到内存中,可以设置
batch_size=-1; - 然后使用
tfds.load()函数来下载数据,需要特别注意设置参数as_supervised=True,这样函数就会返回tf.data.Dataset,一个二元组(input, label),而不是返回FeaturesDict,因为二元组的形式更方便理解和使用; - 最后再指定
with_info=True,这样就可以得到函数处理的信息,以便加深对数据的理解。
代码如下:
import tensorflow_datasets as tfds
SPLIT_WEIGHTS = (8, 1, 1)
splits = tfds.Split.TRAIN.subsplit(weighted=SPLIT_WEIGHTS)
(raw_train, raw_validation, raw_test), metadata = tfds.load(name="tf_flowers",
with_info=True,
split=list(splits),
# batch_size=-1,
as_supervised=True)
print(raw_train)
print(raw_validation)
print(raw_test)

1.2_数据预处理
从 tensorflow_datasets 中下载的数据集包含很多不同尺寸的图片,因此需要将这些图像的尺寸调整为固定的大小,并且将所有像素值都进行标准化,使得像素值的变化范围都在 0~1 之间。尽管这些操作显得繁琐无用,但是必须进行这些预处理操作,因为在训练一个卷积神经网络之前,必须指定它的输入维度。不仅如此,网络中最后全连接层的 shape 取决于 CNN 的输入维度,因此这些预处理的操作是很有必要的。最明显的例子就是上面复现的 LeNet 的 flatten 层,如果你不知道确切的维度,那么就会各种报错。。。
如下所示,构建一个函数 format_exmaple(),并将它传递给 raw_train, raw_validation 和 raw_test 的映射函数,从而完成对数据的预处理。需要指明的是,format_exmaple() 的参数和传递给 tfds.load() 的参数有关:
- 如果
as_supervised=True,那么tfds.load()将下载一个二元组(image, labels),该二元组将作为参数传递给format_exmaple(); - 如果
as_supervised=False,那么tfds.load()将下载一个字典<image,lable>,该字典将作为参数传递给format_exmaple()。
IMG_SIZE = 128
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
def format_example(image, label):
image = tf.cast(image, tf.float32)
# 归一化化像素值
image = image / 255.0
# 调整图像大小
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, label
train = raw_train.map(format_example)
validation = raw_validation.map(format_example)
test = raw_test.map(format_example)
print(train)
print(validation)
print(test)

除此之外
-
还对
train对象调用.shuffle(BUFFER_SIZE),用于打乱训练集的顺序,该操作能够消除样本的 次序偏差。 -
再用
.batch(BATCH_SIZE)来定义这三类数据集的batch大小,这里batch的大小设置为 32 。 -
最后用
.prefetch()在后台预加载数据,该操作能够在模型训练的时候进行,从而减少训练时间。
下图直观地描述了 .prefetch() 的作用。

不采取 prefetch 操作,CPU 和 GPU/TPU 的大部分时间都处在空闲状态。

采取 prefetch 操作后,CPU 和 GPU/TPU 的空闲时间显著较少。
在该步骤中,有几点值得注意:
- 操作顺序很重要。
- 如果先执行
.shuffle()操作,再执行.repeat()操作,那么将进行跨batch的数据打乱操作,每个epoch中的batch数据都是被提前打乱的,而不用每次加载一个batch就打乱依一次它的数据顺序;- 如果先执行
.repeat()操作,再执行.shuffle()操作,那么每次只有单个batch内的数据次序被打乱,而不会进行跨batch的数据打乱操作。- 将
buffer_size设置为和数据集大小一样,这样数据能够被充分的打乱,但是buffer_size过大会导致消耗更多的内存。- 在开始进行打乱操作之前,系统会分配一个缓冲区,用于存放即将进行打乱的数据,因此在数据集开始工作之前,过大的
buffer_size会导致一定的延时。- 在缓冲区没有完全释放之前,正在执行打乱操作的数据集不会报告数据集的结尾,而数据集会被
.repeat()重启,这将会又一次导致延时。
train = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation = validation.batch(BATCH_SIZE)
test = test.batch(BATCH_SIZE)
train = train.prefetch(tf.data.experimental.AUTOTUNE)
其中 tf.data.experimental.AUTOTUNE 可以让程序自动的选择最优的线程并行个数。
1.3_数据增强
在训练阶段,对数据进行实时增广操作,而不是手动的将这些增广图像添加到数据上。
代码如下:
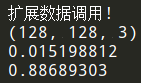
def augment_data(image, label):
print("扩展数据调用!")
# 将图片随机进行水平翻转
image = tf.image.random_flip_left_right(image)
# 随机设置图片的对比度
image = tf.image.random_contrast(image, lower=0.0, upper=1.0)
# 将图片随机进行垂直翻转
# image = tf.image.random_flip_up_down(img)
# 随机设置图片的亮度
# image = tf.image.random_brightness(img, max_delta=0.5)
# 随机设置图片的色度
# image = tf.image.random_hue(img, max_delta=0.3)
# 随机设置图片的饱和度
# image = tf.image.random_saturation(img, lower=0.3, upper=0.5)
# 增加更多选择
return image, label
train = train.map(augment_data)
SHUFFLE_BUFFER_SIZE = 1024
BATCH_SIZE = 32
train = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation = validation.batch(BATCH_SIZE)
test = test.batch(BATCH_SIZE)
train = train.prefetch(tf.data.experimental.AUTOTUNE)
print(train)
print(validation)
print(test)
print(metadata)

其中 metadata 是 tfds.load 的返回值之一 ds_info : tfds.core.DatasetInfo。请注意 ds_info,无论 split 请求如何,对象都会记录整个数据集。Split-specific 的信息可在 ds_info.splits 中找到。
1.4_数据可视化
通过可视化数据集中的一些随机样本,不仅可以发现其中存在的异常或者偏差,还可以发现特定类别的图像的变化或相似程度。使用 train.take() 可以批量获取数据集,并将其转化为 numpy 数组, tfds.as_numpy(train) 也具有相同的作用,如下代码所示:
# 获取将标签索引转换为字符串的函数
get_label_name = metadata.features['label'].int2str
在这里,我们逐批获取数据集,并在将其传递给 plotting 函数之前,将其转换为 numpy 数组。
plt.figure(figsize=(12,12))
for batch in train.take(1):
for i in range(9):
image, label = batch[0][i], batch[1][i]
plt.subplot(3,3,i+1)
plt.imshow(image.numpy())
plt.title(get_label_name(label.numpy()))
plt.grid(False)
plt.show()
print(image.shape)
print(np.min(image))
print(np.max(image))


我们还可以使用 tfds.as_numpy(train) 而不是 train.take() 直接获取 numpy 数组。
plt.figure(figsize=(12,12))
for batch in tfds.as_numpy(train):
for i in range(9):
image, label = batch[0][i], batch[1][i]
plt.subplot(3, 3, i+1)
plt.imshow(image)
plt.title(get_label_name(label))
plt.grid(False)
# We need to break the loop else the outer loop
# will loop over all the batches in the training set
break
print(image.shape)
print(np.min(image))
print(np.max(image))
plt.show()

二、构建模型
tf.keras 是一个符合 Keras API 标准的 TensorFlow 实现,它是一个用于构建和训练模型的高级 API,而且对 TensorFlow 特定功能的支持相当好(例如 eager execution 和 tf.data 管道)。tf.keras 不仅让 TensorFlow 变得更加易于使用,而且还保留了它的灵活和高效。
from tensorflow import keras
print(keras.__version__)
张量 (image_height, image_width, color_channels) 作为模型的输入,在这里不用考虑 batch 的大小。黑白图像只有一个颜色通道,而彩色图像具有三个颜色通道 (R,G,B) 。
- 在这里,采用彩色图像作为输入,输入图像尺寸为
(128,128,3),将该参数传递给shape,从而完成输入层的构建。 - 接下来,将用一种很常见的模式构建
CNN的卷积部分:一系列堆叠的Conv2D层和MaxPooling2D层。 - 最后,将卷积部分的输出(
(28,28,64)的张量)馈送到一个或多个全连接层中,从而实现分类。
# 使用函数api在keras中创建一个简单的cnn模型
def create_model():
img_inputs = keras.Input(shape=IMG_SHAPE)
conv_1 = keras.layers.Conv2D(32, (3, 3), activation='relu')(img_inputs)
maxpool_1 = keras.layers.MaxPooling2D((2, 2))(conv_1)
conv_2 = keras.layers.Conv2D(64, (3, 3), activation='relu')(maxpool_1)
maxpool_2 = keras.layers.MaxPooling2D((2, 2))(conv_2)
conv_3 = keras.layers.Conv2D(64, (3, 3), activation='relu')(maxpool_2)
flatten = keras.layers.Flatten()(conv_3)
dense_1 = keras.layers.Dense(64, activation='relu')(flatten)
output = keras.layers.Dense(
metadata.features['label'].num_classes,
activation='softmax')(dense_1)
model = keras.Model(inputs=img_inputs, outputs=output)
return model
注意,全连接层的输入必须是一维的向量,而卷积部分的输出却是三维的张量。因此需要先将三维的张量展平成一维的向量,然后再将该向量输入到全连接层中。数据集中有 5 个类别,这些信息可以从数据集的元数据中获取。因此,模型最后一个全连接层的输出是一个长度为 5 的向量,再用 softmax 函数对它进行激活,至此就构建好了 CNN 模型。
2.1_可视化模型
.summary() 为我们提供了完整的模型架构。
simple_model = create_model()
simple_model.summary()

keras.utils.plot_model(simple_model, 'flower_model_with_shape_info.png', show_shapes=True)

2.2_设置训练参数
我们指定了 tensorboard 保存日志的目录。
import datetime, os
log_dir="logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
os.makedirs(log_dir)
我们还得到了在训练集、验证集和测试集中的示例数的值。
steps_per_epoch:在一个epoch中训练模型的批数。其计算方法是将训练实例的数量除以每批的大小。validation_steps:与steps_per_epoch相同,但适用于验证数据集。
num_train, num_val, num_test = (
metadata.splits['train'].num_examples * weight / 10 for weight in SPLIT_WEIGHTS
)
steps_per_epoch = round(num_train) // BATCH_SIZE
validation_steps = round(num_val) // BATCH_SIZE
print('Number of examples in the train set:', num_train)
print('Number of examples in the validation set:', num_val)
print('Number of examples in the test set:', num_test)

2.3_编译和训练模型
import os
def train_model(model):
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Creating Keras callbacks
tensorboard_callback = keras.callbacks.TensorBoard(
log_dir=log_dir, histogram_freq=1)
model_checkpoint_callback = keras.callbacks.ModelCheckpoint(
'training_checkpoints/weights.{epoch:02d}-{val_loss:.2f}.hdf5', period=5)
os.makedirs('training_checkpoints/', exist_ok=True)
early_stopping_checkpoint = keras.callbacks.EarlyStopping(patience=5)
history = model.fit(train.repeat(),
epochs=5,
steps_per_epoch=steps_per_epoch,
validation_data=validation.repeat(),
validation_steps=validation_steps,
callbacks=[tensorboard_callback,
model_checkpoint_callback,
early_stopping_checkpoint])
return history
history = train_model(simple_model)

2.4_可视化训练指标
TF2.0 中的另一个新特性是能够在 jupyter 笔记本内部使用成熟的 tensorboard。在开始模型训练之前,先启动tensorboard,这样就可以在模型训练时查看指标。
%load_ext tensorboard.notebook
%tensorboard --logdir logs
# 使用以下命令停止TensorBoard
# 需要传递进程的ID
!kill 100276
我们将训练集和验证集上的评估指标进行了可视化,该指标为 train_model() 的返回值,使用 Matplotlib 绘制曲线图:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()

这些可视化图能让我们更加深入了解模型的训练程度。在模型训练过程中,确保训练集和验证集的精度在逐渐增加,而损失逐渐减少,这是非常重要的。
-
如果训练精度高但验证精度低,那么模型很可能出现了 过拟合。这时需要对进行 数据增广,或者直接从网上下载更多的图像,从而增加训练集。此外,还可以采用一些防止过拟合的技术,例如
Dropout或者BatchNormalisation等等,详细的可以看这个博客——深度学习100问之神经网络中解决过拟合的几种方法。 -
如果训练精度和验证精度都较高,但是验证精度比训练精度略高,那么验证集很可能包含较多易于分类的图像。有时我们使用
Dropout和BatchNorm等技术来防止过拟合,但是这些操作会为训练过程添加一些 随机性,使得训练更加困难,因此模型在验证集上表现会更好些。
稍微拓展一点讲,由于训练集的评估指标是对一个
epoch的平均估计,而验证集的评估指标却是在这个epoch结束后,再对验证集进行评估的,因此验证集所用的模型可以说要比训练集的模型训练的更久一些。
Jupyer notebook 中的 TensorBoard 视图:

三、使用预训练的模型
在上面,我们训练了一个简单的 CNN 模型,它给出了大约 60% 的准确率。通过使用更大、更复杂的模型,获得更高的准确率,预训练模型 是一个很好的选择,可以直接使用 预训练模型 来完成分类任务,因为 预训练模型 通常已经在大型的数据集上进行过训练,通常用于完成大型的图像分类任务。
当然也可以运用 迁移学习 的方法,只使用预训练模型的一部分,重新构建属于自己的模型。简单来讲,迁移学习 可以理解为:一个在足够大的数据集上经过训练的模型,能够有效地作为视觉感知的通用模型,通过使用该模型的特征映射,我们就可以构建一个鲁棒性很强的模型,而不需要很多的数据去训练。
3.1_下载预训练模型
tf.keras.applications 中有一些预定义好的经典卷积神经网络结构(Application应用),如下:

可以直接调用这些经典的卷积神经网络结构(甚至载入预训练的参数),而无需手动定义网络结构。
例如,本次将要用到的模型是由谷歌开发的 MobileNetV2 网络结构,该模型已经在 ImageNet 数据集上进行过预训练,共含有 1.4M 张图像,而且学习了常见的 1000 种物体的基本特征,因此,该模型具有强大的特征提取能力。
model = tf.keras.applications.MobileNetV2()
当执行以上代码时,TensorFlow 会自动从网络上下载 MobileNetV2 网络结构,因此在第一次执行代码时需要具备网络连接。但是每个网络结构具有自己特定的详细参数设置,比如我们这里的 tf.keras.applications.MobileNetV2,详细的可以看这个 Keras 文档;一些共通的常用参数如下:
-
input_shape:输入张量的形状(不含第一维的Batch),大多默认为224 × 224 × 3。一般而言,模型对输入张量的大小有下限,长和宽至少为32 × 32或75 × 75; -
include_top:在网络的最后是否包含全连接层,默认为True; -
weights:预训练权值,默认为imagenet,即为当前模型载入在ImageNet数据集上预训练的权值。如需随机初始化变量可设为None; -
classes:分类数,默认为1000。修改该参数需要include_top参数为True且weights参数为None。
模型下载时,需要指定参数 include_top=False,这样网络的最后就不包含全连接层了,因为我们只想使用该模型进行特征提取,而不是直接使用该模型进行分类。此外,它还将我们的输入维度限制为该模型所训练的维度,默认值:299x299。预训练模型 的分类模块通常受原始的分类任务限制,如果想将 预训练模型 用在新的分类任务上,需要自己构建模型的分类模块,而且需要将该模块在新的数据集上进行训练,这样才能使模型适应新的分类任务。
现在使用 MobileNetV2 网络在 tf_flowers 分类数据集上进行训练(为了代码简短高效,直接使用了 TensorFlow Datasets 和 tf.data 载入和预处理数据)。通过将 weights 设置为 imagenet,随机初始化变量且使用在 imagenet 上的预训练权值,同时不设置 classes,默认对应于 1000 分类的数据集。
from tensorflow import keras
# 从预先训练的模型MobileNetV2导入为基础模型
base_model = keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')


base_model.trainable = False
# 让我们看看基本模型架构
base_model.summary()

我们将 预训练模型 当做一个特征提取器,输入 (128,128,3) 的图像,得到 (4,4,1280) 的输出特征。特征提取器可以理解为一个特征映射过程,最终的输出特征是输入的多维表示,在新的特征空间中,更加利于图像的分类。
注:在编译和训练模型之前,冻结卷积模块是很重要的。通过冻结(或设置
layer.trainable=false),我们可以防止在训练期间更新这些层中的权重。
3.2_添加分类层
由于指定了参数 include_top=False,下载的 MobileNetV2 模型不包含最顶层的分类层,因此我们需要添加一个新的分类层,而且它是为 tf_flowers 所专门定制的。
要从特征块生成预测,请使用 keras.layers.GlobalAveragePooling2D() 层在 2x2 空间位置上平均,以将特征转换为每个图像的单个 1280 元素向量。在顶部,应用 keras.layers.Dense 层将这些特征转换为每个图像的单个预测。然后使用 tf.keras.sequential api来堆叠特征提取程序和这两个层,在训练之前不要忘记编译模型。
代码如下:
def build_model():
model = keras.Sequential([
base_model,
keras.layers.GlobalAveragePooling2D(),
keras.layers.Dense(metadata.features['label'].num_classes,
activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
Mobile_model = build_model()
Mobile_model.summary()

3.3_训练Mobile模型
# 训练前评估模型(可选)
loss0, accuracy0 = Mobile_model.evaluate(validation.repeat(), steps = validation_steps)

log_dir = os.path.join(
"logs",
"fit",
datetime.datetime.now().strftime("%Y%m%d-%H%M%S"),
)
os.makedirs(log_dir)
# Creating Keras callbacks
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model_checkpoint_callback = keras.callbacks.ModelCheckpoint(
'training_checkpoints/weights.{epoch:02d}-{val_loss:.2f}.hdf5', period=5)
os.makedirs('training_checkpoints/', exist_ok=True)
early_stopping_checkpoint = keras.callbacks.EarlyStopping(patience=5)
history = Mobile_model.fit(train.repeat(),
epochs=5,
steps_per_epoch = steps_per_epoch,
validation_data=validation.repeat(),
validation_steps=validation_steps,
callbacks=[tensorboard_callback,
model_checkpoint_callback,
early_stopping_checkpoint])
Train for 91 steps, validate for 11 steps
Epoch 1/5
91/91 [===========] - 134s 1s/step - loss: 1.0087 - accuracy: 0.6075 - val_loss: 1.2909 - val_accuracy: 0.5511
Epoch 2/5
91/91 [===========] - 139s 2s/step - loss: 0.6338 - accuracy: 0.7720 - val_loss: 0.7929 - val_accuracy: 0.7131
Epoch 3/5
91/91 [===========] - 130s 1s/step - loss: 0.5578 - accuracy: 0.7959 - val_loss: 0.8869 - val_accuracy: 0.7131
Epoch 4/5
91/91 [===========] - 140s 2s/step - loss: 0.5147 - accuracy: 0.8108 - val_loss: 0.8605 - val_accuracy: 0.7330
Epoch 5/5
91/91 [===========] - 137s 2s/step - loss: 0.4757 - accuracy: 0.8264 - val_loss: 0.9297 - val_accuracy: 0.6903
经过5个阶段的训练,我们得到了约 70% 的准确率,绘制了训练和验证精度/损失的学习曲线。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()

开始训练预训练模型后,训练集和验证集的评估指标随着训练 epoch 的变化。
从图中可以看到,验证集的精度高略低于训练集的精度。使用测试集来评估模型可以进一步验证模型的泛化能力。如果想让模型取得更好的效果,对模型进行微调。
# 保存Keras模型
Mobile_model.save('Mobile_v2_128_tf_flowes.h5')

loaded_model = keras.models.load_model('Mobile_v2_128_tf_flowes.h5')
loaded_model.evaluate(test)

3.4_微调预训练网络
在特征提取实验中,我们只在 Mobile_v2 的基础模型上训练了几层。训练过程中,训练前网络的权值不更新。进一步提高性能的一种方法是在训练顶级分类器的同时 微调 预训练模型 顶层的权重。训练过程将强制将权重从通用特征映射调整到与我们的数据集特定关联的特征。
注意:只有在预先训练的模型设置为 non-trainable 的 top-level 分类器之后,才能尝试此操作。如果在预先训练的模型上添加一个随机初始化的分类器并尝试联合训练所有层,则梯度更新的幅度将过大(由于来自分类器的随机权重),并且预先训练的模型将忘记它所学到的一切。
此外,微调 预训练模型 的顶层而不是 预训练模型 的所有层背后的原因如下:在 convnet 中,一个层越高,它就越专业。convnet 的前几层学习了非常简单和通用的特性,这些特性几乎可以推广到所有类型的图像,但是当你往上走的时候,这些特性对模型所训练的数据集越来越具体。微调 的目标是使这些专门的特性适应新的数据集。
# 取消冻结模型的顶层
base_model.trainable = True
# 让我们看看基本模型中有多少层
print("Number of layers in the base model: ", len(base_model.layers))

# Fine tune from this layer onwards
fine_tune_at = 129
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
# Compile the model using a much-lower training rate.
Mobile_model_model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.0001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Mobile_model_model.summary()

history_fine = Mobile_model.fit(train.repeat(),
steps_per_epoch = steps_per_epoch,
epochs=10,
initial_epoch = 5,
validation_data=validation.repeat(),
validation_steps=validation_steps,
callbacks=[tensorboard_callback,
model_checkpoint_callback,
early_stopping_checkpoint])
Train for 91 steps, validate for 11 steps
Epoch 6/10
91/91 [=========] - 148s 2s/step - loss: 0.4520 - accuracy: 0.8359 - val_loss: 0.9207 - val_accuracy: 0.7273
Epoch 7/10
91/91 [=========] - 139s 2s/step - loss: 0.3368 - accuracy: 0.8773 - val_loss: 0.8071 - val_accuracy: 0.7614
Epoch 8/10
91/91 [=========] - 141s 2s/step - loss: 0.2874 - accuracy: 0.8954 - val_loss: 0.7512 - val_accuracy: 0.7784
Epoch 9/10
91/91 [=========] - 127s 1s/step - loss: 0.2340 - accuracy: 0.9175 - val_loss: 0.7784 - val_accuracy: 0.7812
Epoch 10/10
91/91 [=========] - 136s 1s/step - loss: 0.2130 - accuracy: 0.9200 - val_loss: 0.8010 - val_accuracy: 0.7812
注意:如果训练数据集相当小,并且与 MobileNet V2 所使用的原始数据集相似,那么微调可能会导致过度拟合。
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
initial_epochs=5
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()

总之,我们介绍了如何使用预先训练的模型进行转移学习以提高准确性:
- 使用 预训练模型 特征提取:在处理小数据集时,通常会利用在同一域中的较大数据集上训练的模型所学习的特征,这是通过实例化 预训练模型 并在上面添加一个全连接分类器来完成的。训练前的模型被冻结,训练过程中只更新分类器的权值,在这种情况下,卷积部分提取与每个图像相关联的所有特征,并且训练一个在给定特征集上确定类别的分类器。
- 微调 预训练模型:为了进一步提高性能,可能需要通过 微调 将 预训练模型 的顶层重新利用到新的数据集。在这种情况下,调整权重以便学习特定于我们数据集的高度指定和高维特征。只有当训练数据集很大并且非常类似于预先训练模型所使用的原始数据集时,这才有意义。
推荐阅读
- TensorFlow2.0 学习笔记(一):TensorFlow 2.0 的安装和环境配置以及上手初体验
- TensorFlow2.0 学习笔记(二):多层感知机(MLP)
- TensorFlow2.0 学习笔记(三):卷积神经网络(CNN)
- TensorFlow2.0 学习笔记(四):迁移学习(MobileNetV2)
- TensorFlow2.0 学习笔记(五):循环神经网络(RNN)
参考文章
- TensorFlow 官方文档
- 简单粗暴 TensorFlow 2.0
- tfds.load
- https://github.com/himanshurawlani/practical_intro_to_tf2