一、Requests库的使用
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。
(1)安装、在cmd下执行:pip install requests
(2)TP协议对资源的操作
GET 获取URL位置的资源
HEAD 获取URL位置资源的头部信息
POST 向URL位置的资源后附加新的数据
PUT 覆盖URL位置的资源
PATCH 局部更新URL位置的资源
DELETE 删除URL位置的资源
(3)requests库中的方法
requests.request() 构造请求,支持下面各方法的基础
requests.get() 获取HTML网页的主要方法,对应于HTTP的GET
requests.head() 获取HTML网页的头信息的方法
requests.post() 向HTML网页提交POST请求的方法,对应HTTP的POST
requests.put() 向HTML提交PUT请求,对应HTTP的PUT
requests.patch() 对应于HTTP的PATCH
requests.delete() 向HTTP页面提交删除请求,对应HTTP的DELETE
(4)方法的原型及用法
5.1、get方法原型
requests.get(url,params=None,**kwargs)
5.2、params url中的额外参数,字典或字节流格式,可选
**kwargs 12个控制访问的参数,如headers等
5.3、post方法原型
requests.post(url,data=None,json=None,**kwargs)
payload={"key":"value"}
r=requests.post(url,data=payload)
5.4、put,patch与post类似
5.5、delete方法原型
request.deete(url,**kwargs)
requests.request(method,url,**kwargs)
method 请求方式,get,put,post...
(5)**kwargs(访问控制参数)
5.1、params 字典或字节序列,作为参数增加到url中
如:
kv={'k1':'v1','k2':'v2'}
r=requests.request('GET','http://python123.io/ws',params=kv)
print(r.url)
结果:http://python123.io/ws?k1=v1&k2=v2
5.2、data 字典,字节序或文件对象,作为Request的内容,post请求的参数
5.3、json JSON格式数据,作为Request的内容
5.4、headers 字典,HTTP定制头
如:
h={'User-Agent':'...'}
r=requests.get(url,headers=h)
5.5、cookies 字典或CookieJar,Request中的cookie
5.6、auth 元组,支持HTTP认证功能
5.7、files 字典,传输文件
如:
fs={'file':open('data.xls','rb')}
r=requests.request('POST',url,files=fs)
5.8、timeout 设定超时时间,以秒为单位,超时会产生timeout异常
r=requests.request('GET',url,timeout=10)
5.9、proxies 字典,设置访问代理服务器,可以防止逆追踪
如:
pxs={'http':'http://user:pass@10.10.10.1:1234','https':'https://10.10.10.1:4321'}
r=requests.get(url,proxies=pxs)
5.10、allow_redirects True/False 默认True,重定向开关
5.11stream True/False 默认True,立即下载开关
5.12、verify True/False 默认True,认证SSL证书开关
5.13、cert 本地SSL证书路径
(5)Response对象的属性
r=requests.get() //r为Response对象
r.status_code HTTP请求的返回状态码
r.text HTTP响应内容的字符串形式,即url对应的页面内容
r.encoding 从HTTP header中猜测的响应内容的编码方式
r.apparent_encoding 从内容中分析出的响应内容的编码方式
r.content HTTP响应内容的二进制形式
(6)Requests库的异常
requests.ConnectionError 网络连接异常,如DNS查询失败、拒绝连接
requests.HTTPError HTTP错误异常
requests.URLRequired URL缺失异常
requests.TooManyRedirects 超过最大重定向次数产生的重定向异常
requests.ConnectTimeout 连接远程服务器超时异常
requests.Timeout 请求URL超时产生的超时异常
raise_for_status 如果返回的status_code不是200产生requests.HTTPError
实例一:get方法的使用
import requests
url='https://blog.csdn.net/qq_32261191/article/details/80338091'
#使用try...except捕捉异常
try:
#请求url
r=requests.get(url)
#请求状态码不是200,则产生异常
r.raise_for_status()
#设置显示的编码为apparent_encoding检测到的编码格式
r.encoding=r.apparent_encoding
#输出前1000个字符
print(r.text[:1000])
except:
print("ERROR!!!")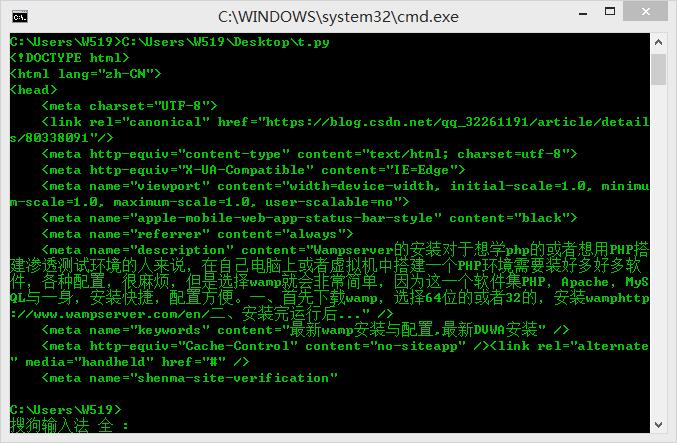
实例二:修改headers
import requests
url='https://blog.csdn.net/qq_32261191/article/details/80338091'
#使用try...except捕捉异常
h={'user-agent':'Mozilla/5.0'}
try:
#请求url
r=requests.get(url)
#默认请求头
print(r.request.headers)
r=requests.get(url,headers=h)
#请求状态码不是200,则产生异常
r.raise_for_status()
#设置显示的编码为apparent_encoding检测到的编码格式
r.encoding=r.apparent_encoding
#修改后的请求头
print(r.request.headers)
except:
print("ERROR!!!")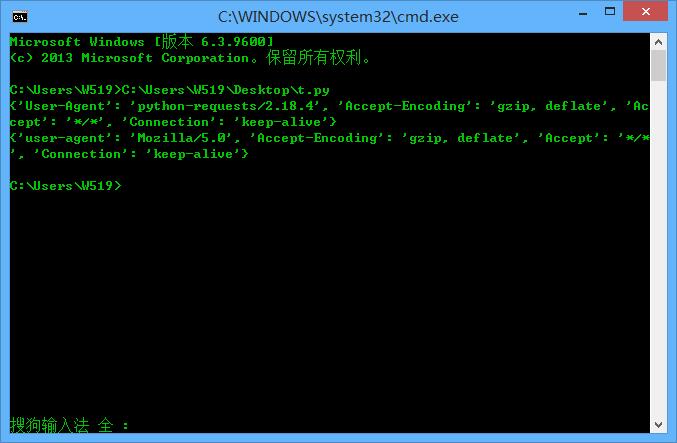
实例三:GET传入参数
百度搜索ip时URL为:http://www.baidu.com/s?wd=ip
import requests
url='http://www.baidu.com/s'
#GET传的参数设置
kv={'wd':'ip'}
#使用try...except捕捉异常
try:
#请求url:http://www.baidu.com/s?wd=ip
r=requests.get(url,params=kv)
#请求状态码不是200,则产生异常
r.raise_for_status()
#设置显示的编码为apparent_encoding检测到的编码格式
r.encoding=r.apparent_encoding
#输出请求的url,
print(r.request.url)
except:
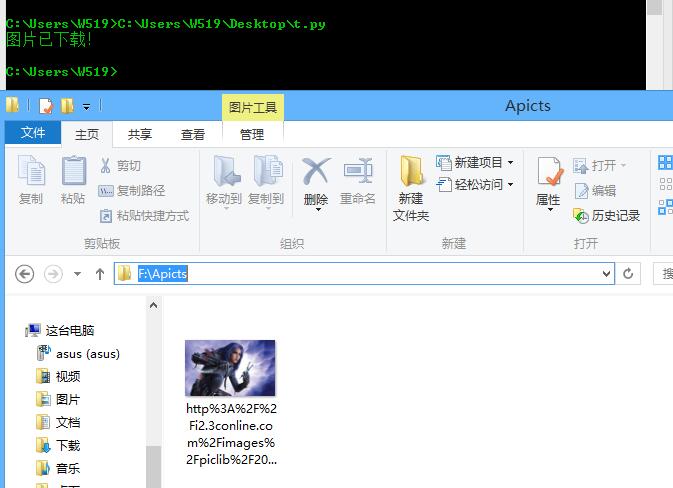
print("ERROR!!!")实例四:图片下载
import requests,os
#图片的URL
url="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1526560867378&di=da4e7dc76d9b54647d1356ba6d3d73ef&imgtype=0&src=http%3A%2F%2Fi2.3conline.com%2Fimages%2Fpiclib%2F201006%2F23%2Fbatch%2F1%2F62615%2F12772647784528c3naeziee.jpg"
#设置存放图片的目录
path="F://Apicts//"
try:
#如果目录不存在,创建目录
if not os.path.exists(path):
os.mkdir(path)
#请求url
r=requests.get(url)
#截取URL中最后一个"="之后的内容,视情况而定
path=path+url.split('=')[-1]
#创建文件并写入
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("图片已下载!")
except:
print("ERROR!!!")
二、Beautiful Soup库的使用
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库
(1)安装beautiful soup库,pip install beautifulsoup4
(2)简单的网站克隆实例
import requests
#BeautifulSoup库简写为bs4,从bs4库中导入BeautifulSoup类
from bs4 import BeautifulSoup
r=requests.get("http://www.baidu.com")
r.encoding=r.apparent_encoding
demo=r.text
#使用html.parser解析器解析得到的html页面
soup=BeautifulSoup(demo,"html.parser")
#输出解析的结果
print(soup.prettify())
demo=soup.prettify()
#创建一个abc.html文件,设置文件编码为目标网页的编码
fn=open("abc.html",'w',encoding=r.encoding)
#写入demo
fn.write(demo)
fn.close()(3)BeautifulSoup库可以使用的解析器
解析器 使用方法 条件
bs4的HTML解析器 BeautifulSoup(mk,'html.parser') 安装bs4
lxml的HTML解析器 BeautifulSoup(mk,'lxml') 安装lxml库
lxml的XML解析器 BeautifulSoup(mk,'xml') 安装lxml库
html5lib的解析器 BeautifulSoup(mk,'html5lib') 安装html5lib
(4)基本元素
Tag 标签,最基本的信息组织单元,用<>和</>标明开头和结尾
Name 标签的名字,<p>...</p>的名字是p,格式:<tag>.name
Attributes 标签的属性,字典形式,格式:<tag>.attrs
NavigableString 标签非属性字符串,<>...</>中的...,格式:<tag>.string
Comment 标签内字符串的注释部分,一种特殊的Comment类型
接上面的代码,如:
soup.title 表示获取解析后的页面的<title>标签
soup.title.name 表示获取title标签的名字
soup.title.parent.name 表示获取title标签的上一层标签的名字
soup.title.parent.parent.name 表示获取title标签的上上层标签的名字
类型全为string
(5)标签的属性
soup.a.attrs 获取标签a的属性,字典类型
soup.a.attrs['href'] 获取a标签属性中href的值
soup.a.string 获取a标签中的字符串,即<a>...</a>中的...
通过string属性可以查看注释和字符串,通过类型区分注释
(6)HTML文档遍历
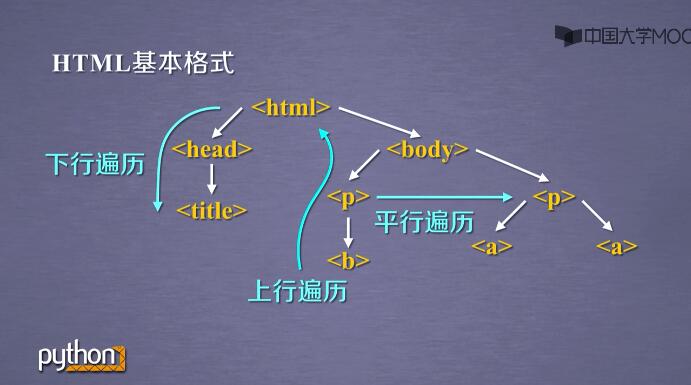
6.1、标签树的下行遍历
.contents 获取子标签列表,将标签所有子标签存入列表
.children 循环遍历子标签
.descendants 包含所有子孙标签
soup.body.contents 获取body标签的所有子标签
#遍历body的子标签
for child in soup.body.children:
print(child)
6.2、标签树的上行遍历
.parent 标签的父标签
.parents 标签的先辈标签
#标签树上行遍历
for parent in soup.a.parents:
print(parent.name)
6.3、标签树的平行遍历
.next_sibling 返回HTML文本顺序的下一个平行节点标签
.previous_sibling 返回HTML文本顺序的上一个平行节点标签
.next_siblings 返回HTML文本顺序的后续所有平行节点标签
.previous_siblings 返回HTML文本顺序的前续所有平行节点标签
获取的结果不一定是标签类型
#遍历后续节点
for sibling in soup.a.next_siblings:
print(sibling)
#遍历前续节点
for sibling in soup.a.previous_siblings:
print(sibling)
(7)find_all()函数使用
find_all(name,attrs,recursive,string,**kwargs)
返回为列表类型
name 要查找的标签
attrs 要查找的标签属性值
recursive 是否全部查找,默认True
string 查找标签字符串域的字符串
<tag>(...) <==> <tag>.find_all(...) 等价
soup(...) <==> soup.find_all(...)
soup.find_all('p','course') 查找<p>标签中包含course的字符串
soup.find_all(string="abc") 查找<>...<>中...包含abc的字符串
#遍历页面中所有链接
ls=soup.find_all('a')
for j in ls:
print(j)
扩展方法(参数与find_all相同)
.find() 搜索且只返回一个结果,str类型
.find_parents() 先辈节点中搜索,返回列表类型
.find_parent() 先辈节点返回一个结果,str类型
.find_next_siblings() 后续平行节点搜索,返回列表类型
.find_next_sibling() 后续平行节点搜索,返回str类型
.find_previous_sibligs() 前序搜索,返回列表类型
.find_previous_siblig() 前序搜索一个,str类型
三、Re库的使用
(1)正则表达式常用操作符
. 表示单个字符
[] 字符集 如[abc]表示a、b、c,[a-z]表示a-z
[^] 非字符集 如[^abc]表示除a、b、c外的字符集
* 前一个字符0或无限次 如abc*表示ab,abc,abccc...
+ 前一个字符1或无限次 如abc+表示abc,abcc,abccc,...
? 前一字符0或1次 如abc?表示ab、abc
| 表示左右任意一个 如ab|cd表示ab、cd
{m} 扩展前一字符m次 如ab{2}c表示abbc
{m,n} 扩展前一字符m-n次 如ab{1,2}表示abc、abbc
^ 匹配字符串开头 如^abc表示匹配字符串开头为abc的字符串
$ 匹配字符串结尾 如abc$表示结尾为abc的字符串
() 分组标记,内部只能用| 如(abc)表示abc,(a|b)表示a、b
d 数字,等价[0-9]
w 单词字符,等价[A-Za-z0-9_]
(2)Re库主要功能函数
re.search() 搜索字符串中匹配的第一个对象,match对象
re.match() 从字符串的开始位置起匹配正则表达式,match对象
re.findall() 搜索字符串,返回符合的全部字符串,列表
re.split() 分割匹配的结果的列表为,子列表
re.finditer() 搜索字符串,返回结果的迭代类型,每个迭代为match类型
re.sub() 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的结果
2.1、re.search函数
re.search(pattern,string,flags=0)
pattern 正则表达式的字符串或原生字符串
string 待匹配的字符串
flags 正则表达式使用时的控制标记
flags的值有
re.I 忽略正则表达式的大小写,使[a-z]可以匹配大写
re.M 正则表达式中的^操作符能将给定字符串的每行当中匹配开始
re.S 正则表达式中的.操作符能匹配所有字符,默认匹配除换行外的字符
import re
match=re.search(r'[1-9]d{5}','BIT 100081')
if match:
print(match.group(0))
运行上面代码输出:100081,使用match函数输出为空,使用findall函数成功输出,search,match,findall,finditer函数参数相同
2.2、re.split函数
re.split(pattern,string,maxsplit=0,flags=0)
其他3个参数同上,maxsplot表示最大分割数,剩余部分作为最后一个元素输出
import re
ls=re.split(r'[1-9]d{5}','BIT 100081 ABC 100081')
print(ls)
ls=re.split(r'[1-9]d{5}','BIT 100081 ABC 100081',maxsplit=1)
print(ls)2.3、re.finditer函数
import re
for m in re.finditer(r'[1-9]d{6}','BIT100081 TSU 100084'):
if m:
print(m.group(0))
2.4、re.sub函数
re.sub(pattern,repl,string,count=0,flags=0)
repl表示替换匹配字符串的字符串
count表示匹配的次数
import re
ls=re.sub(r'[1-9]d{5}','8888','BIT 100081 ABC 100081')
print(ls)
(3)match对象的属性和方法
属性
.string 待匹配的文本
.re 匹配时使用的pattern对象(正则表达式)
.pos 正则表达式搜索文本的开始位置
.endpos 正则表达式搜索文本的结束位置
方法
.group(0) 获得匹配后的字符串
.start() 匹配字符串在原始字符串的开始位置
.end() 匹配字符串在原始字符串的结束位置
.span() 返回(.start(),.end())元组
import re
m=re.search(r'[1-9]d{5}','BIT 100081 ABC 100081')
print(m.string)
print(m.re)
print(m.pos)
print(m.endpos)
print(m.group(0))
print(m.start())
print(m.end())
print(m.span())(4)贪婪匹配(默认)和最小匹配
match=re.search(r'PY.*N','PYANBNCNDN')
match.group(0)
这段代码会返回PYANBNCNDN
如果想要得到最小匹配,在*和N直接加入?即可,在*,+,?,{m,n}后加?就扩展为对应的最小匹配