本文主要区分机器学习中的三种数据集,尤其是验证集和测试集,并介绍常用的交叉验证训练方法。
Training Set
训练集,即用于训练模型内参数(fit the model)的数据集。
Testing Set
即测试集,在使用训练集调整参数之后,使用测试集来评价模型泛化能力。
Validation Set
实际上使用测试集评价模型泛化能力之后并不意味着机器学习任务就此完成,最后还需要使用一个没有见过的数据集来判断模型是否work。在Kaggle中,Testing Set分为Public和Private Testing Set,Public就是用于评价模型泛化能力的通常意义上的测试集,而Private则是未知分布的测试集,决定最终排名的正是Private而不是Public测试。但是,通常训练好的模型在Public Testing Set上的error并不能代表模型在Private Testing Set上的error。例如,通过训练集训练出的model的error为0.1,那么在Public Testing Set中error一般大于且接近于0.1,而在Private Testing Set就不确定了,也可能大于0.5,也可能小于0.1。
形象说来训练集就像是课本,学生通过课本学习知识,Public测试集就是平时的测验,而Private才是最终的高考。但是平时的测验往往只涵盖课本知识的一小部分,而高考则考查得更为全面,这也是为什么有些同学平时测验很好但是高考失常,平时较差但是高考成了黑马的原因之一。如何让Public测试集,即平时的测验变成有水准的模拟考试,从而反映学生在高考的水平呢?一种方法就是在学生学习课本知识的过程中增加平时作业。
即可以从训练集中随机分出一部分作为验证集(Validation Set),如下:
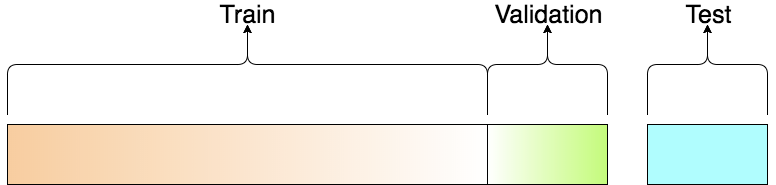
在训练集中调整参数以后,比如训练model1,model2,model3,将模型在验证集上测试,选出error最小的比如model1,然后用model1在整个Training Set上再训一次,然后使用Testing Set(Public)评价其泛化能力,这样此时在Testing Set(Public)上的结果就能跟最终的Private Testing Set相近了。
交叉验证
其实上面的验证集也只是从Training Set中抽出了一次,也就是只根据课本知识的某一部分布置了作业,想要得到最终好的结果就需要进行多组实验。交叉验证的做法就是将数据集分为近似均等且不相交的kkk份,如下:
D=D1∪D2∪...∪DkDi≠Di(i≠j) D=D_1 cup D_2 cup ... cup D_k \ D_i eq D_i (i eq j) D=D1∪D2∪...∪DkDi�=Di(i�=j)
然后依次取其中一份作为验证集,其余作为训练集进行训练,然后求得error的均值作为用于评价来调整模型参数,如下:
