2019-04-08 13:30:58
模型的名称——“VGG”代表了牛津大学的Oxford Visual Geometry Group,该小组隶属于1985年成立的Robotics Research Group,该Group研究范围包括了机器学习到移动机器人。
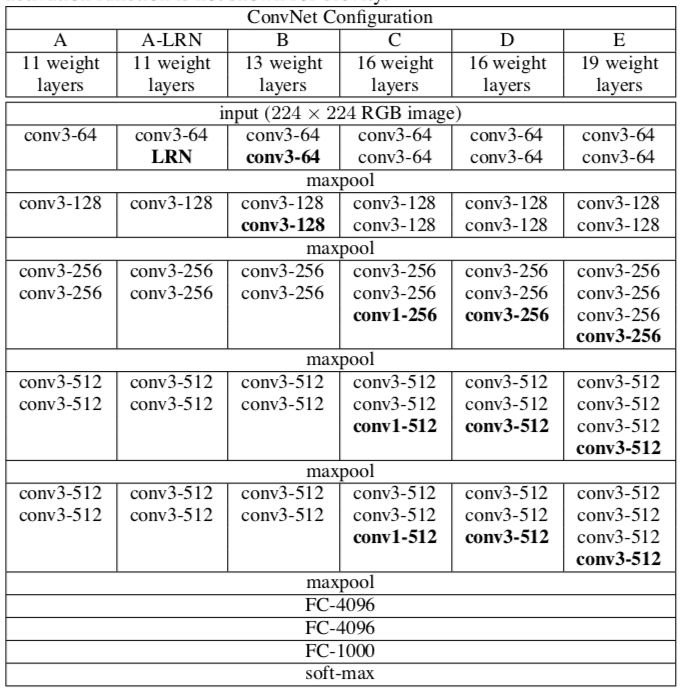
目前使用比较多的网络结构主要有ResNet(152-1000层),GooleNet(22层),VGGNet(19层)。大多数模型都是基于这几个模型上改进,采用新的优化算法,多模型融合等,这里重点介绍VGG。
 二、VGG网络的特点
二、VGG网络的特点
- 将网络的深度加深到了19层,可以说证明了Depth在深度学习领域的核心作用,为之后的ResNet打下了伏笔;
- 使用了更小的3 * 3卷积核,和更深的网络。两个3 * 3卷积核的堆叠相对于5 * 5卷积核的视野,三个3 * 3卷积核的堆叠相当于7 * 7卷积核的视野。这样一方面可以有更少的参数,另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力;
对于输入通道为cin,输出通道为cout的卷积层来说,7 * 7的卷积核参数量是:7 * 7 * cin * cout = 49 * cin * cout;
对于输入通道为cin,输出通道为cout的卷积层来说,3 * 3的卷积核达到相同的接受域参数量是:3 * 3 * 3 * cin * cout = 27 * cin * cout;
显然小卷积核的参数量要大大少于大卷积核的参数量,同时由于卷积层的最后会引入Relu进行激活,这样也增加了更多的非线性变换。
- 使用了1 * 1卷积,作者首先认为1x1卷积可以增加决策函数(decision function,这里的决策函数就是softmax)的非线性能力,非线性是由激活函数ReLU决定的,本身1x1卷积则是线性映射,即将输入的feature map映射到同样维度 的feature map;
- 层数更深特征图更宽。基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓;
- VGG网络模型泛化能力强,在做年龄估计时候,采用VGG误差比GoogLeNet还要好;
- 采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率。

在内存使用方面最初的卷积层使用的内存最多;
在参数使用方面最后的卷积层参数数量最大;
四、模型评估方法
- 预初始化权重
对于深度网络来说,网络权值的初始化十分重要。为此,论文中首先训练一个浅层的网络结构A(网络结构见上图),训练这个浅层的网络时,随机初始化它的权重就足够得到比较好的结果。然后,当训练深层的网络时,前四层卷积层和最后的三个全连接层使用的是学习好的A网络的权重来进行初始化,而其余层则随机初始化。这也就是上一点提到的某些层的预初始化。(随机初始化权重时,使用的是0均值,方差0.01的正态分布;偏置则都初始化为0)。
- 训练图像尺寸选择
S是训练图像的最小边,训练尺度。
Q是测试图像的最小边,测试尺度。
对原始图片进行等比例缩放,使得S大于224,然后在图片上随机提取224x224窗口,进行训练。
单一尺度训练:固定 S 的大小,对应了单一尺度的训练,训练多个分类器。训练S=256和S=384两个分类器,其中S=384的分类器用S=256的权重进行初始化;
多尺度(Multi-scale)训练(尺度抖动):直接训练一个分类器,每次数据输入的时候,每张图片被重新缩放,缩放的短边S随机从[256,512]中选择一个,也可以认为通过尺度抖动(scale jittering)进行训练集增强。图像中的目标可能具有不同的大小,所以训练时认为这是有用的。
- 模型评估
1. 单一尺度评估(single scale)
即测试图像大小Q固定,若S固定,则Q=S;若S抖动,则Q=0.5(Smin+Smax)
作者将深层次网络B与与具有5×5卷积层的浅层网络进行了比较,浅层网络可以通过用单个5×5卷积层替换B中每对3×3卷积层得到。测量的浅层网络性能比网络B差,这证实了具有小滤波器的深层网络优于具有较大滤波器的浅层网络。
训练时的尺度抖动(S∈[256;512])得到了与固定最小边(S=256或S=384)的图像训练相比更好的结果,即使在测试时使用单尺度。这证实了通过尺度抖动进行的训练集增强确实有助于捕获多尺度图像统计。
2. 多尺度评估(multi-scale)
即评估图像大小Q不固定,Q = {S_{min}, 0.5(S_{min} + S_{max}), S_{max}
作者通过试验发现当使用固定值S训练时,Q的范围在[S−32,S,S+32]之间时,测试的结果与训练结果最接近,否则可能由于训练和测试尺度之间的巨大差异导致性能下降。
实验结果表明测试时的尺度抖动与在单一尺度上相同模型的评估相比性能更优,并且尺度抖动优于使用固定最小边S的训练。
3. 多裁剪评估(multi-crop)
Dense(密集评估),即指全连接层替换为卷积层(第一FC层转换到7×7卷积层,最后两个FC层转换到1×1卷积层),最后得出一个预测的score map,再对结果求平均。
multi-crop,即对图像进行多样本的随机裁剪,然后通过网络预测每一个样本的结构,最终对所有结果平均。
多剪裁表现要略好于密集评估,并且这两种方法确实是互补的,因为它们的结合优于它们中的每一种。
多裁剪图像评估是密集评估的补充:当将ConvNet应用于裁剪图像时,卷积特征图用零填充,而在密集评估的情况下,相同裁剪图像的填充自然会来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的上下文。
由于全卷积网络被应用在整个图像上,所以不需要在测试时对采样多个裁剪图像,因为它需要网络重新计算每个裁剪图像,这样效率较低。使用大量的裁剪图像可以提高准确度,因为与全卷积网络相比,它使输入图像的采样更精细。