队友链接:
http://www.cnblogs.com/waaaafool/p/9768456.html
具体分工:
胡青元实现词频统计、代码复审、性能分析、单元测试、改进
何宇恒实现爬虫、博客编写
代码规范:https://www.cnblogs.com/waaaafool/p/9664877.html
PSP表格:
| PSP | Personal Software Process Stages 2 | 预估时间(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 35 |
| Estimate | · 估计这个任务需要多少时间 | 960 | 1400 |
| Development | 开发 | 180 | 280 |
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 100 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 60 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 300 | 500 |
| · Coding | · 具体编码 | 200 | 240 |
| · Code Review | · 代码复审 | 50 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 45 |
| Reporting | 报告 | 30 | 30 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1380 | 1440 |
解题思路描述与设计实现说明
爬虫使用
最开始使用的是工具爬虫。采用八爪鱼采集器,简略使用方法:
登陆后点击向导采取
输入网址:
选择:

即可爬取网页中的链接的内容
缺点:虽可以较快完整爬取信息,但格式极难调整
后用python实现
import requests
from urllib.request import urlopen
from bs4 import BeautifulSoup
txt = open (r'C:Users胖若两人Desktop
esult.txt' , 'w', encoding='utf-8' )//result文件地址
i=0
def getPaper (newsUrl) :
res = requests. get (newsUrl)
res. encoding = ' utf-8'
soup = BeautifulSoup (res. text, 'htm1. parser' )
Title = soup. select( '#papertitle') [0]. text. strip()
print("Title:", Title, file=txt)
Abstract = soup. select( '#abstract' ) [0]. text. strip()
print ( "Abstract:", Abstract,"
" , file=txt)
return
sUr1 = 'http:// openaccess. thecvf. com/ CVPR2018. py'
res1 = requests. get (sUrl)
res1. encoding = 'utf-8'
soup1 = BeautifulSoup (res1. text, 'htm1. parser' )
for titles in soup1. select('. ptitle') :
t ='http://openaccess thecvf. com/'+ titles. select( 'a' )[0][ 'href ']
print(i, file=txt)
getPaper (t)
i=i+1
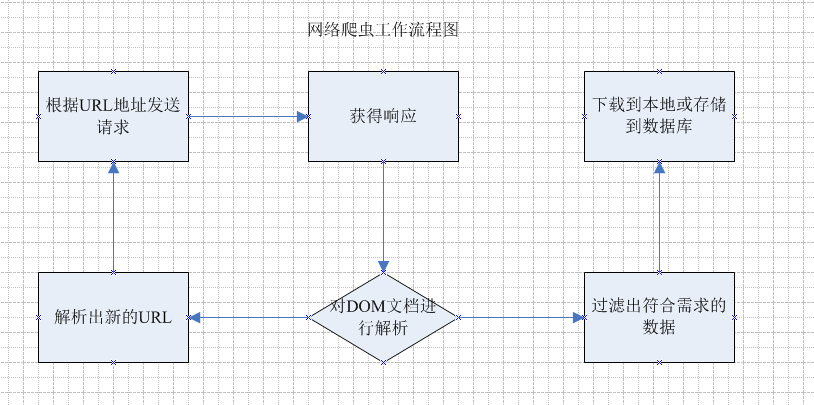
大致思路如下:
根据指定的url地址 去发送请求,获得响应, 然后解析响应 , 一方面从响应中查找出想要查找的数据,另一方面从响应中解析出新的URL路径,
然后继续访问,继续解析;继续查找需要的数据和继续解析出新的URL路径
代码组织与内部实现设计
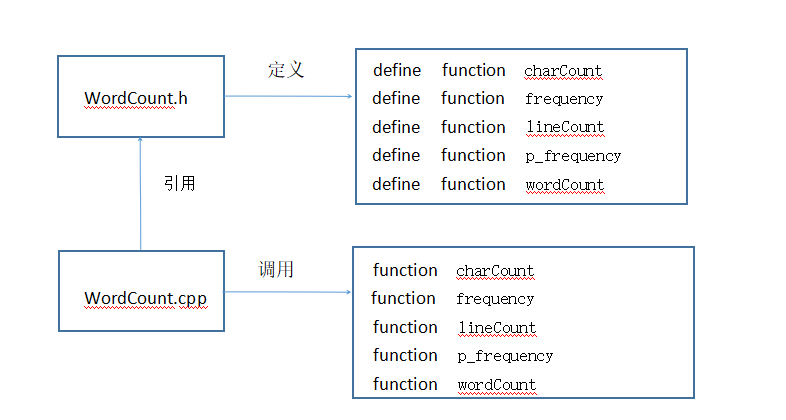
void charCount(const char* file, const char* file1);
//统计单词个数
void frequency(int w_flag,int times, const char* file, const char* file1);
//统计单词频率,w_flag判定是否启用加权,times确定输出个数。
void lineCount(const char* file, const char* file1);
//统计行数
void p_frequency(int w_flag,int times, int m, const char* file, const char* file1);
//统计词组频率,w_flag判定是否启用加权,times确定输出个数,m是词组的单词组成数量
void wordCount(const char* file, const char* file1);
//统计单词个数
说明算法的关键与关键实现部分流程图
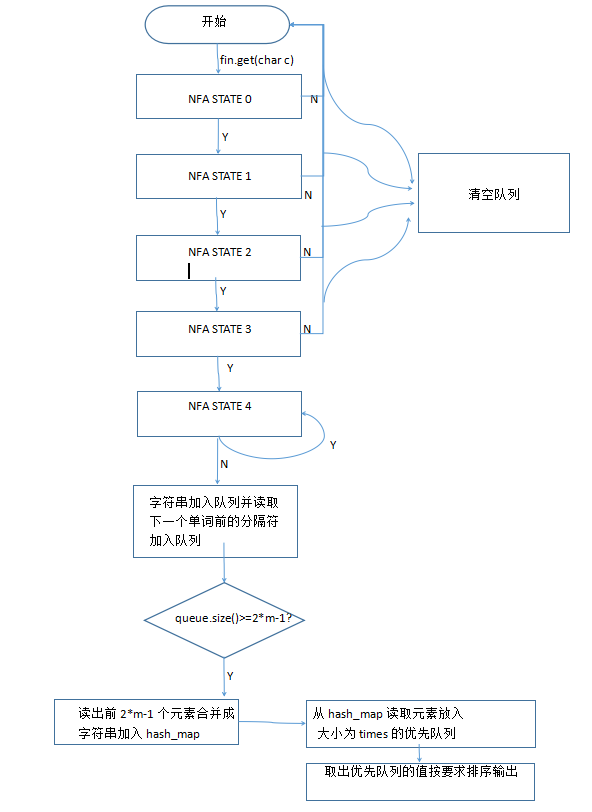
3、算法的关键是用NFA读取单词,进行判定,如果是单词就入队,然后记录此单词与下一个单词之间的分隔符,也入队。如果队列的大小大于等于2*m-1,就可以进行读出字符串记录在hash_map里,若遇到非法单词,则清空队列。流程图如下:
关键代码解释
string s = "";
unordered_map<string, int> wordList;
queue<string>que;
queue<string>que_temp;
int num = 0;//状态转换标识 0,1,2,3,4
int flag = 1;
int more_flag = 0;
while (1) {
char c;
if (!more_flag) {
fin.get(c);
if (fin.eof()) {
break;
}
}
else {
more_flag = 0;
}
if ('A' <= c && c <= 'Z') c = c + 32;
if (num == 0) {
if ('a' <= c && c <= 'z') {
s += c;
num++;
}
else {
while (!que.empty()) {
que.pop();
}
}
}
else if (num == 1) {
if (('a' <= c && c <= 'z') || ('0' <= c && c <= '9')) {
s += c;
num++;
}
else {
num = 0;
s = "";
while (!que.empty()) {
que.pop();
}
}
}
else if (num == 2) {
if (('a' <= c && c <= 'z') || ('0' <= c && c <= '9')) {
s += c;
num++;
}
else {
num = 0;
s = "";
while (!que.empty()) {
que.pop();
}
}
}
else if (num == 3) {
if (('a' <= c && c <= 'z') || ('0' <= c && c <= '9')) {
s += c;
num++;
}
else {
num = 0;
s = "";
while (!que.empty()) {
que.pop();
}
}
}
else if (num == 4) {
if (('a' <= c && c <= 'z') || ('0' <= c && c <= '9')) {
s += c;
num = 4;
}
else {
string s1 = s + c;
if (s1 == "title:"&&w_flag==1) {
flag = 10;
}
else if (s1 == "abstract:"&&w_flag==1) {
flag = 1;
}
else {
que.push(s);
string s2;
s2 += c;
//读分隔符
while (1) {
fin.get(c);
if (fin.eof()) {
break;
}
if ('A' <= c && c <= 'Z') c = c + 32;
if (!(('a' <= c && c <= 'z')||('0'<=c&&c<='9'))&&c>=32) {
s2 += c;
}
else {
que.push(s2);
more_flag = 1;
break;
}
}
}
//如果满足条件,就进行队列访问,获取数组字符串
if (que.size() >= (unsigned)(2 * m - 1)) {
que_temp = que;
string s3;
for (int i = 0; i < 2 * m - 1; i++) {
s3 += que_temp.front();
que_temp.pop();
}
wordList[s3] += flag;
if (que.size() >= 2) {
que.pop();
que.pop();
}
}
s = "";
num = 0;
}
}
}
//如果文件末尾不属于分割符,需要补充
if (num == 4) {
string s3;
if (que.size() >=(unsigned) (2 * m - 2)) {
while (!que.empty()) {
s3 += que.front();
que.pop();
}
s3 += s;
wordList[s3] += flag;
}
}
流程图
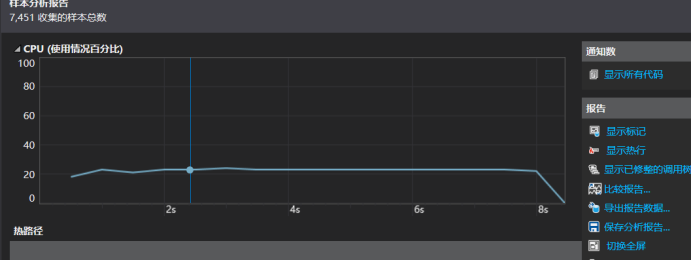
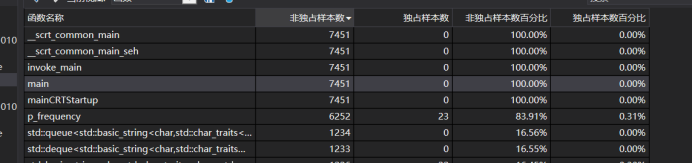
性能分析与改进
性能分析:读取字符串时间复杂度为o(n),hash_map的添加操作是o(n),查找为o(1)。
性能改进:查询时发现,map的组织形式是有序,而我们的算法并不需要有序,所以换成了unordered_map。
展示性能分析图和程序中消耗最大的函数
单元测试
单元测试:
因为IDE中出现了问题,没有test,百度以及重装了也没办法,所以只能手工测试。
下面是参考网上写的简单测试模板:
namespace UnitTest1
{ TEST_CLASS(UnitTest1)
{ public: TEST_METHOD(TestMethod1)
{ char file[] = "E:\222.txt"; int num = Tool::CharCount(file); Assert::IsTrue(num == 1);// TODO: 在此输入测试代码 }
};
Github的代码签入记录
Github:
https://github.com/hyh1998/pair-project
遇到的代码模块异常或结对困难及解决方法
写代码时设计好了算法,以及数据结构,但是在书写过程中犯了很多低级错误,比如(==写成=),所以debug了很久也没debug出来。
最后只能通过对代码进行明确的规划,以及重新写一遍并注意编程细节来解决。
评价你的队友
值得学习的地方
对代码认真负责、准时完成任务,对待队友耐心负责
需要改进的地方
对待队友太宽容
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 4 | 135 | 135 | 3 | 3 | 熟悉java语言基础 |
| 5 | 350 | 485 | 5 | 8 | 初步建立前端 |