一、折线绘图
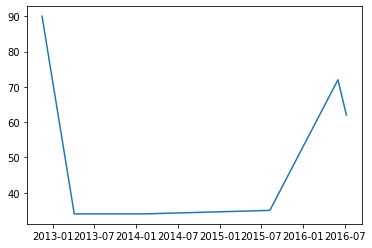
import pandas as pd import matplotlib.pyplot as plt data = pd.read_csv("F:\ml\机器学习\01\1.csv") print(data)
date values 0 2012/11/15 90 1 2013/4/5 34 2 2014/2/3 34 3 2015/8/9 35 4 2016/6/2 72 5 2016/7/9 62
data['date'] = pd.to_datetime(data['date']) #将日期转化为以-的格式,方便阅读 print(data)
date values 0 2012-11-15 90 1 2013-04-05 34 2 2014-02-03 34 3 2015-08-09 35 4 2016-06-02 72 5 2016-07-09 62
#以下将以图形式表现出来 plt.figure()#以这个开始,创建figure的一个对象 plt.plot(data['date'], data['values']) #plot()的里面的参数,第一个为横轴,第二个参数为纵轴画图 plt.show() #显示图
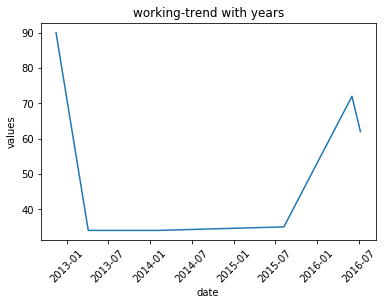
#但是上面的图中横坐标很不清楚,改变其显示方式,以及加上标题。 plt.figure()#以这个开始,创建figure的一个对象 plt.plot(data['date'], data['values']) #plot()的里面的参数,第一个为横轴,第二个参数为纵轴画图 plt.xticks(rotation = 45) #将横坐标的斜向45°显示 plt.xlabel('date') #给横轴一个标签 plt.ylabel('values') #给纵轴一个标签 plt.title('working-trend with years') #给整个图一个题目 plt.show() #显示图
二、子图的操作
import matplotlib.pyplot as plt fig = plt.figure() #以这个开始,创建figure的一个对象 ax1 = fig.add_subplot(2, 2, 1) #建立子图,add_subplot中的参数2,2表示建立2*2的四个子图,最后一个参数1表示四个子图中的第一个。 ax3 = fig.add_subplot(2, 2, 3) #最后一个参数3表示四个子图中的第三个 ax4 = fig.add_subplot(2, 2, 4) #最后一个参数4表示四个子图中的第四个 plt.show()

import numpy as np import matplotlib.pyplot as plt fig = plt.figure(figsize = (3, 3)) #figsize指定大小,第一个参数表示长度,第二个参数表示宽度 ax1 = fig.add_subplot(2, 2, 1) ax4 = fig.add_subplot(2, 2, 4) ax1.plot(np.arange(10), np.arange(10)) #画出子图ax1所需要的图 ax4.plot(np.random.random(10), np.arange(10)) #画出子图ax4所需要的图 plt.show()
#如果我想要在一个图上画几条线呢 x = np.linspace(-1, 1, 10) #使用np.linspace定义x:范围是(-1,1);个数是10. 仿真一维数据组(x ,y)表示曲线1. y1 = 2*x y2 = x**2 plt.figure(figsize = (4, 3)) #figsize指定大小,第一个参数表示长度,第二个参数表示宽度 plt.plot(x, y1, color = 'red', linewidth = 1.0, linestyle = '--', label="y1") #其中label是标注,但想要标注后在图中显示,用legend的表示 plt.plot(x, y2, color = 'blue', linewidth = 1.0, linestyle = '-', label = 'y2') plt.xlabel('x') plt.ylabel('y') plt.legend(loc = 'best') #best表示最好的显示方式,还有其他指定的方式 plt.show()
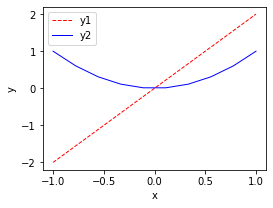
其中’loc’参数有多种,’best’表示自动分配最佳位置,其余的如下:
'best' : 0,
'upper right' : 1,
'upper left' : 2,
'lower left' : 3,
'lower right' : 4,
'right' : 5,
'center left' : 6,
'center right' : 7,
'lower center' : 8,
'upper center' : 9,
'center' : 10,
三、条形图与散点图
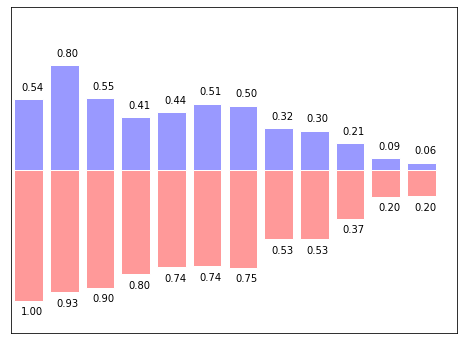
#条形图的绘制 import matplotlib.pyplot as plt import numpy as np n = 12 X = np.arange(n) Y1 = (1-X/float(n))*np.random.uniform(0.5, 1.0, n) #Y是相应的均匀分布的随机数据 Y2 = (1-X/float(n)*np.random.uniform(0.5, 1.0, n)) plt.figure(figsize = (8, 6)) plt.bar(X, +Y1, facecolor = '#9999ff', edgecolor = 'white') #facecolor表示主体颜色,具体的其他颜色表示可以百度,edgecolor表示边框颜色 plt.bar(X, -Y2, facecolor = '#ff9999', edgecolor = 'white') plt.xlim(-0.5, n) plt.ylim(-1.25, 1.25) plt.xticks(()) plt.yticks(()) #在条形图上标注值 for x, y in zip(X, Y1): #zip的意思就是可以将每个数值分别赋值 plt.text(x+0.1, y+0.05, '%.2f' % y, ha = 'center', va = 'bottom') #x+0.4向右偏移0.4, y+0.05向上偏0.05, '%.2f' % y的意思是y保留两位小数。 for x, y in zip(X, Y2): plt.text(x+0.1, -y-0.05, '%.2f' % y, ha = 'center', va = 'top') #ha = 'center'的意思是横向居中对齐,va = 'top'的意思是纵向顶部对齐 plt.show()
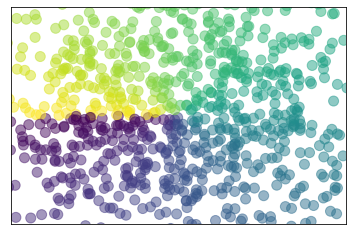
#散点图的绘制 import matplotlib.pyplot as plt import numpy as np n = 1024 #生成1024个呈标准正态分布的二维数据组 (平均数是0,方差为1) 作为一个数据集 X = np.random.normal(0 , 1, n) #每个点的x值 Y = np.random.normal(0, 1, n) #每个点的y值 T = np.arctan2(Y, X) #这个是颜色的显示值 plt.scatter(X, Y, s = 100, c = T, alpha = 0.5) #s表示size, c表示color, alpha表示透明度 plt.xlim(-1.5, 1.5) #x轴的限制 plt.ylim(-1.5, 1.5) #y轴的限制 plt.xticks(()) #消除x轴的标注 plt.yticks(()) #消除y轴的标注 plt.show()
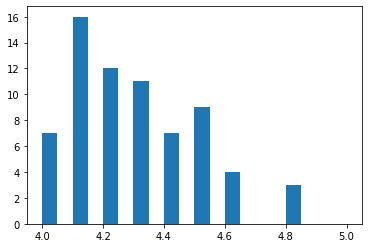
四、柱形图
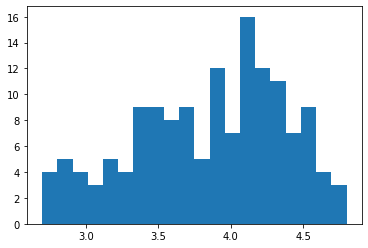
#柱形图 import matplotlib.pyplot as plt import numpy as np import pandas as pd norm_reviews = pd.read_csv("F:\ml\机器学习\01\2.csv") fig, ax = plt.subplots() ax.hist(norm_reviews['Fandango_Ratingvalue'], bins = 20) #bins进行均匀的分布,默认是10 plt.show()
import matplotlib.pyplot as plt import numpy as np import pandas as pd norm_reviews = pd.read_csv("F:\ml\机器学习\01\2.csv") fig, ax = plt.subplots() ax.hist(norm_reviews['Fandango_Ratingvalue'], range = (4, 5), bins = 20) #只显示4-5区间,总的还是20条,只是在4-5之间是8条 plt.show()