MySQL
MySQL相关文章这里不在赘述,想了解的点击下面的链接:
Python操作MySQL
本篇对于Python操作MySQL主要使用两种方式:
- 原生模块 pymsql
- ORM框架 SQLAchemy
pymysql
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同。
下载安装
pip3 install pymysql
使用操作
1、执行SQL
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
# 创建连接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
# 创建游标
cursor = conn.cursor()
# 执行SQL,并返回收影响行数
effect_row = cursor.execute("update hosts set host = '1.1.1.2'")
# 执行SQL,并返回受影响行数
#effect_row = cursor.execute("update hosts set host = '1.1.1.2' where nid > %s", (1,))
# 执行SQL,并返回受影响行数
#effect_row = cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)])
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
2、获取新创建数据自增ID
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
cursor = conn.cursor()
cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)])
conn.commit()
cursor.close()
conn.close()
# 获取最新自增ID
new_id = cursor.lastrowid
3、获取查询数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
cursor = conn.cursor()
cursor.execute("select * from hosts")
# 获取第一行数据
row_1 = cursor.fetchone()
# 获取前n行数据
# row_2 = cursor.fetchmany(3)
# 获取所有数据
# row_3 = cursor.fetchall()
conn.commit()
cursor.close()
conn.close()
注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如:
- cursor.scroll(1,mode='relative') # 相对当前位置移动
- cursor.scroll(2,mode='absolute') # 相对绝对位置移动
4、fetch数据类型
关于默认获取的数据是元组类型,如果想要或者字典类型的数据,即:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
# 游标设置为字典类型
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
r = cursor.execute("call p1()")
result = cursor.fetchone()
conn.commit()
cursor.close()
conn.close()
ORM && sqlalchemy
ORM介绍
ORM英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过ORM将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用SQL语言。
ORM的优点:
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
- ORM使我们构造固化数据结构变得简单易行。
ORM的缺点:
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
sqlalchemy
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。点击这里了解主要用户列表
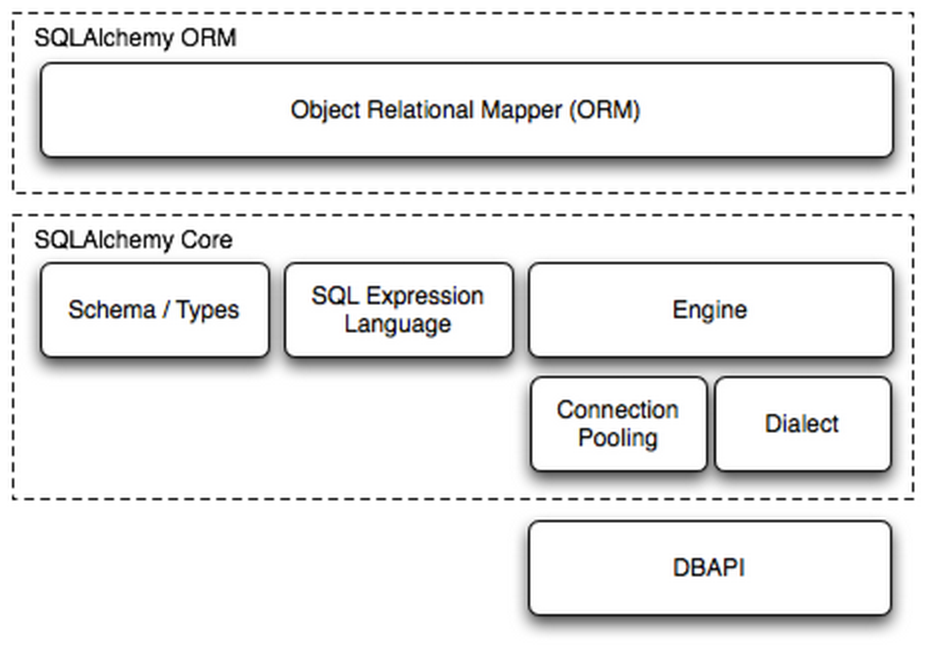
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
# MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
# pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
# MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
# cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
sqlalchemy 安装
pip3 install SQLAlchemy
sqlalchemy 操作数据
使用 ORM/Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 所有组件对数据进行操作。根据类创建对象,对象转换成SQL,执行SQL。
#!/usr/bin/env python
#-*-coding:utf-8-*-
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String
engine = create_engine("mysql+pymysql://root:123456@192.168.92.201/test?charset=utf8",encoding='utf-8',echo=True)
Base = declarative_base() # 生成ORM基类
class User(Base):
__tablename__='users' # 表名
id = Column(Integer,primary_key=True)
name = Column(String(32))
password = Column(String(64))
def __repr__(self): # 让返回的数据不直接是对象,变得可读
return "<User(name='%s',password='%s')>" % (self.name,self.password)
# 创建表结构:寻找Base的所有子类,按照子类的结构在数据库中生成对应的数据表信息
# Base.metadata.create_all(engine)
Session_class = sessionmaker(bind=engine)
session = Session_class()
################### 插入一条数据 ###################
data1 = User(name="Jack",password="123")
session.add(data1)
session.commit()
################### 插入多条数据 ###################
session.add_all([
User(ame="David",password="333")
User(ame="Lily",password="666")
])
session.commit()
##################### 查询数据 #####################
my_user = session.query(User).filter_by(name="David").first()
print (my_user)
# 你可以看到输出结果是 <User(name='David',password='123')> ,如果不加__repr__,返回的数据直接是对象。
### 其他查询姿势:
my_user = session.query(User).filter(User.id>0).filter(User.id<7).all() # 多条件查询,相当于 user.id >1 AND user.id <7
my_user = session.query(User).filter(User.name.in_(['David','SB'])).all() # select tables in ...
my_user = session.query(User.name.label('name_label')).all() # ???
my_user = session.query(User).order_by(User.id).all() # 排序
my_user = session.query(User).order_by(User.id)[1:3] # 结果从1~3顺序显示
my_user = session.query(User).filter(User.name.like("Da%")).count() # like匹配 && 统计
### 分组查询:
from sqlalchemy import func
my_user = session.query(func.count(User.name),User.name).group_by(User.name).all()
# 相当于SQL为:
SELECT count(user.name) AS count_1, user.name AS user_name FROM user GROUP BY user.name;
# 输出结果为:
[(1, 'Jack'), (2, 'Rain')]
print (my_user)
session.commit()
##################### 修改数据 #####################
session.query(User).filter(User.name=="David").update({'password':4848})
session.commit()
# 上述方法可以修改数据,还有一种方法,当你查询出来数据的时候,也可以直接修改,看下面步骤:
my_user = session.query(User).filter_by(name="David").first()
my_user.name = "SB"
session.commit()
##################### 删除数据 #####################
session.query(User).filter(User.name=="David").delete
####################### 回滚 #######################
session.rollback()
# sqlalchemy操作默认就是事务,增删改balabala..只要没commit,随时可以rollback...
注:SQLAlchemy无法修改表结构,如果需要可以使用SQLAlchemy开发者开源的另外一个软件Alembic来完成。
外键关联
我们创建一个addresses表,跟上面创建的users表关联
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship
class Address(Base):
__tablename__ = 'addresses'
id = Column(Integer, primary_key=True)
email_address = Column(String(32), nullable=False)
user_id = Column(Integer, ForeignKey('users.id'))
user = relationship("User", backref="addresses") # 允许你在user表里通过backref字段反向查出所有它在addresses表里的关联项
def __repr__(self):
return "<Address(email_address='%s')>" % self.email_address
表创建好后,我们这样来反查试试
obj = Session.query(User).first()
for i in obj.addresses: #通过user对象反查关联的addresses记录
print(i)
addr_obj = Session.query(Address).first()
print(addr_obj.users.name) #在addr_obj里直接查关联的users表
创建关联对象
obj = Session.query(User).filter(User.name=='David').all()[0]
print(obj.addresses)
obj.addresses = [Address(email_address="xx@jd.com"), #添加关联对象
Address(email_address="oo@jd.com")]
session.commit()
多外键关联
下表中,Customer表有2个字段都关联了Address表
#!/usr/bin/env python
#-*-coding:utf-8-*-
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,ForeignKey
from sqlalchemy.orm import relationship,sessionmaker
from sqlalchemy import ForeignKey
engine = create_engine("mysql+pymysql://root:123456@192.168.92.201/test?charset=utf8",
encoding='utf-8',echo=True)
Base = declarative_base() # 生成ORM基类
class Customer(Base):
__tablename__ = 'customer'
id = Column(Integer, primary_key=True)
name = Column(String(64))
billing_address_id = Column(Integer, ForeignKey("new_address.id"))
shipping_address_id = Column(Integer, ForeignKey("new_address.id"))
billing_address = relationship("Address",foreign_keys=[billing_address_id]) # 此处添加foreign_keys来执行外键和哪个字段对应
shipping_address = relationship("Address",foreign_keys=[shipping_address_id])
class Address(Base):
__tablename__ = 'new_address'
id = Column(Integer, primary_key=True)
street = Column(String(64))
city = Column(String(64))
state = Column(String(64))
# Base.metadata.create_all(engine)
Session_class = sessionmaker(bind=engine)
session = Session_class()
# 添加几个数据试试!!
addr1 = Address(street="fengtai",city="beijing",state="china")
addr2 = Address(street="haidian",city="beijing",state="china")
addr3 = Address(street="fangshan",city="beijing",state="china")
c1 = Customer(name="user1",billing_address_id="2",shipping_address_id="3")
c2 = Customer(name="user2",billing_address_id="1",shipping_address_id="3")
c3 = Customer(name="user3",billing_address_id="3",shipping_address_id="3")
session.add_all([addr1,addr2,addr3,c1,c2,c3])
session.commit()
多对多关系
现在来设计一个能描述“图书”与“作者”的关系的表结构,需求是:
- 一本书可以有好几个作者一起出版
- 一个作者可以写好几本书
此时,我们可以再搞出一张中间表,来关联书名和作者。
下面我们通过book_m2m_author表完成了book表和author表之前的多对多关联
#!/usr/bin/env python
#-*-coding:utf-8-*-
from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey,engine
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine("mysql+pymysql://root:123456@192.168.92.201/test?charset=utf8",
encoding='utf-8',echo=True)
Base = declarative_base()
# 创建一个表来让sqlalchemy关联authors表和books表
book_m2m_author = Table('book_m2m_author', Base.metadata,
Column('book_id',Integer,ForeignKey('books.id')),
Column('author_id',Integer,ForeignKey('authors.id')),
)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer,primary_key=True)
name = Column(String(64))
pub_date = Column(DATE)
authors = relationship('Author',secondary=book_m2m_author,backref='books')
def __repr__(self):
return self.name
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
name = Column(String(32))
def __repr__(self):
return self.name
# Base.metadata.create_all(engine)
Session_class = sessionmaker(bind=engine) #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
s = Session_class() #生成session实例
# 插入数据
b1 = Book(name="book1",pub_date="2016-05-08")
b2 = Book(name="book2",pub_date="2017-06-08")
b3 = Book(name="book3",pub_date="2018-07-08")
b4 = Book(name="book4",pub_date="2019-08-08")
b5 = Book(name="book5",pub_date="2020-08-08")
a1 = Author(name="Alex")
a2 = Author(name="Jack")
a3 = Author(name="Rain")
a4 = Author(name="David")
b1.authors = [a1,a2]
b2.authors = [a1,a2,a3]
b5.authors = [a4]
s.add_all([b1,b2,b3,b4,b5,a1,a2,a3,a4])
s.commit()
此时,我们去用orm查一下数据
print('--------通过书表查关联的作者---------')
book_obj = s.query(Book).filter_by(name="book1").first()
print(book_obj.name, book_obj.authors)
print('--------通过作者表查关联的书---------')
author_obj =s.query(Author).filter_by(name="David").first()
print(author_obj.name , author_obj.books)
s.commit()
输出如下
--------通过书表查关联的作者---------
book1 [David, Jack]
--------通过作者表查关联的书---------
Alex [book3, book4]
这就实现了多对多关系啦!
多对多删除
删除数据时不用管boo_m2m_authors , sqlalchemy会自动帮你把对应的数据删除
通过书删除作者
author_obj =s.query(Author).filter_by(name="Jack").first()
book_obj = s.query(Book).filter_by(name="book2").first()
book_obj.authors.remove(author_obj) #从一本书里删除一个作者
s.commit()
直接删除作者
删除作者时,会把这个作者跟所有书的关联关系数据也自动删除
author_obj =s.query(Author).filter_by(name="David").first()
# print(author_obj.name , author_obj.books)
s.delete(author_obj)
s.commit()