前言、flink介绍:
Apache Flink 是一个分布式处理引擎,用于在无界和有界数据流上进行有状态的计算。通过对时间精确控制以及状态化控制,Flink能够运行在任何处理无界流的应用中,同时对有界流,则由一些专为固定数据集设计的算法和数据结构进行了内部处理,从而提升了性能。
1、flink特性
(1)Flink是一个开源的流处理框架,它具有以下特点:
- 分布式:Flink程序可以运行在多台机器上。
- 高性能:处理性能比较高。
- 高可用:由于Flink程序本身是稳定的,因此它支持高可用性。
- 准确:Flink可以保证数据处理的准确性。
Flink主要由Java代码实现,它同时支持实时流处理和批处理。对于Flink而言,作为一个流处理框架,批数据只是流数据的一个极限特例而已。此外,Flink还支持迭代计算、内存管理和程序优化,这是它的原生特性。
(2)优势:
- 流式优先:Flink可以连续处理流式数据。
- 容错:Flink提供有状态的计算,可以记录数据的处理状态,当数据处理失败的时候,能够无缝地从失败中恢复,并保持Exactly-once。
- 可伸缩:Flink中的一个集群支持上千个节点。
- 性能:Flink支持高吞吐(单位时间内可大量完成处理的数据操作)、低延迟(可快速支持海量数据)。
2、flink架构
Flink架构可以分为4层,包括Deploy层、Core层、API层和Library层

-
Deploy层:该层主要涉及Flink的部署模式,Flink支持多种部署模式——本地、集群(Standalone/YARN)和云服务器(GCE/EC2)。
-
Core层:该层提供了支持Flink计算的全部核心实现,为API层提供基础服务。
-
API层:该层主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中流处理对应DataStream API,批处理对应DataSet API。
-
Library层:该层也被称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持FlinkML(机器学习库)、Gelly(图处理)、Table 操作。
一、相关概念:
1、watermark
watermark是一种衡量Event Time进展的机制,它是数据本身的一个隐藏属性。通常基于Event Time的数据,自身都包含一个timestamp;
1)作用:
watermark是用于处理乱序事件的,通常用watermark机制结合window来实现。流处理从事件产生、到流经source、再到operator,中间是有一个过程和时间。大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络等原因,导致乱序的产生(out-of-order或late element)。对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个机制就是watermark。
2、 CheckPoint
(2.1)概述
为了保证State的容错性,Flink需要对State进行CheckPoint。CheckPoint是Flink实现容错机制的核心功能,它能够根据配置周期性地基于Stream中各个Operator/Task的状态来生成快照,从而将这些状态数据定期持久化存储下来。Flink程序一旦意外崩溃,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
(2.2)使用说明
1)Checkpoint 在默认的情况下仅用于恢复失败的作业,并不保留,当程序取消时 checkpoint 就会被删除。
2) 默认情况下,CheckPoint功能是Disabled(禁用)的,使用时需要先开启它。
env.enableCheckpointing(1000)
(2.3)目录结构
checkpoint 由元数据文件、数据文件(与 state backend 相关)组成。可通过配置文件中 “state.checkpoints.dir” 配置项来指定元数据文件和数据文件的存储路径,另外也可以在代码中针对单个作业特别指定该配置项。
当前的 checkpoint 目录结构如下所示:
/user-defined-checkpoint-dir /{job-id} | + --shared/ + --taskowned/ + --chk-1/ + --chk-2/ + --chk-3/ ...
在hdfs中的存储结构
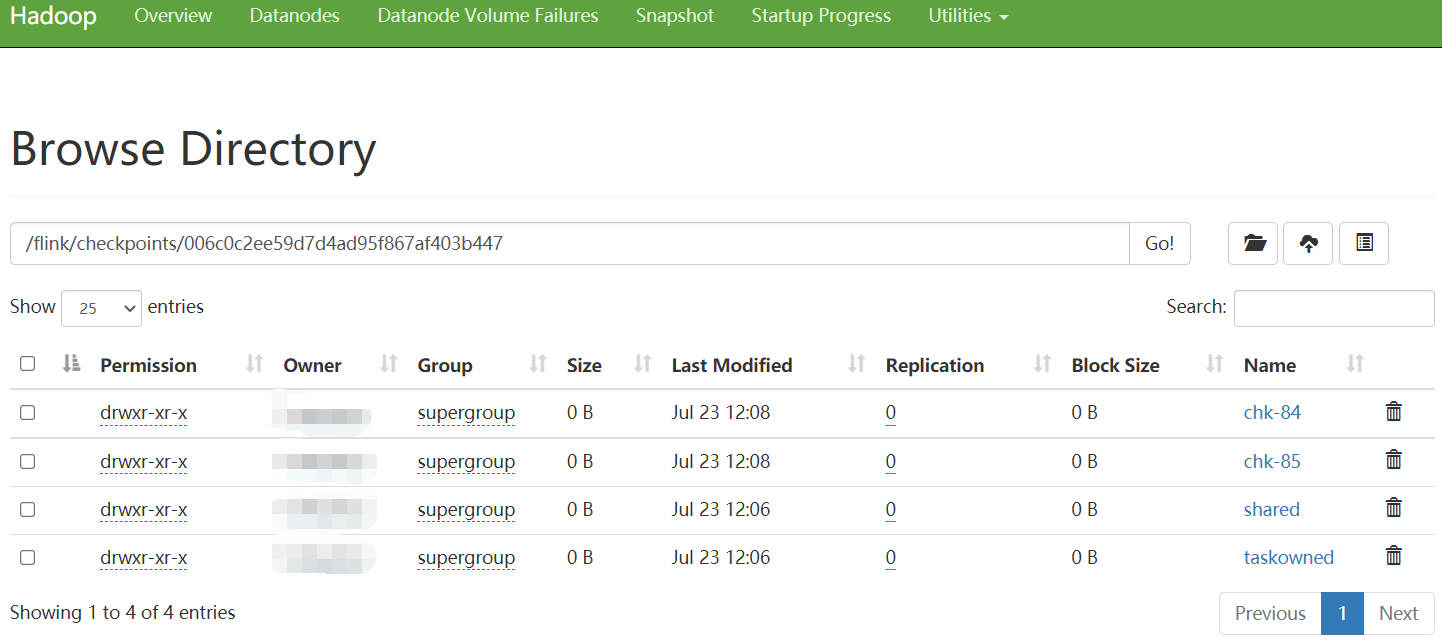
其中 SHARED 目录保存了可能被多个 checkpoint 引用的文件,TASKOWNED 保存了不会被 JobManager 删除的文件,EXCLUSIVE 则保存那些仅被单个 checkpoint 引用的文件。
3、Flink基本组件
Flink中提供了3个组件,包括DataSource、Transformation和DataSink。
-
DataSource:表示数据源组件,主要用来接收数据,目前官网提供了readTextFile、socketTextStream、fromCollection以及一些第三方的Source。
-
Transformation:表示算子,主要用来对数据进行处理,比如Map、FlatMap、Filter、Reduce、Aggregation等。
-
DataSink:表示输出组件,主要用来把计算的结果输出到其他存储介质中,比如writeAsText以及Kafka、Redis、Elasticsearch等第三方Sink组件。因此,想要组装一个Flink Job,至少需要这3个组件。
即Flink Job=DataSource+Transformation+DataSink
二、Flink DataStreams API
1、DataStreams操作
获得一个StreamExecutionEnvironment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile("file:///path/to/file");
使用转换函数在DataStream上调用方法转换(通过将原始集合中的每个String转换为Integer,将创建一个新的DataStream)
DataStream<String> input = ...;
DataStream<Integer> parsed = input.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
return Integer.parseInt(value);
}
});
writeAsText(String path)
print()
1)同步执行:一旦触发调用execute()上StreamExecutionEnvironment,根据ExecutionEnvironment执行类型的不同,在本地计算机上触发或将job提交到群集上执行。该execute()方法将等待作业完成,然后返回JobExecutionResult,其中包含执行时间和累加器结果。
2)异步执行:调用触发异步作业执行executeAysnc()的StreamExecutionEnvironment。它将返回一个JobClient与提交的作业进行通信的。
final JobClient jobClient = env.executeAsync();
final JobExecutionResult jobExecutionResult = jobClient.getJobExecutionResult().get();
eg:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(value -> value.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
dataStream.print();
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
2、dataSource
基于文件:
readTextFile(path)-TextInputFormat逐行读取文本文件,即符合规范的文件,并将其作为字符串返回。readFile(fileInputFormat, path)-根据指定的文件输入格式读取(一次)文件。readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)-这是前两个内部调用的方法。它path根据给定的读取文件fileInputFormat。根据提供的内容watchType,此源可以定期(每intervalms)监视路径中的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者对路径中当前的数据进行一次处理并退出(FileProcessingMode.PROCESS_ONCE)。使用pathFilter,用户可以进一步从文件中排除文件。
基于套接字:
socketTextStream-从套接字读取。元素可以由定界符分隔。
基于集合:
fromCollection(Collection)-从Java Java.util.Collection创建数据流。集合中的所有元素必须具有相同的类型。fromCollection(Iterator, Class)-从迭代器创建数据流。该类指定迭代器返回的元素的数据类型。fromElements(T ...)-从给定的对象序列创建数据流。所有对象必须具有相同的类型。fromParallelCollection(SplittableIterator, Class)-从迭代器并行创建数据流。该类指定迭代器返回的元素的数据类型。generateSequence(from, to)-在给定间隔内并行生成数字序列。
自定义:
addSource-附加新的源功能。例如,Apache Kafka,可以使用 addSource(new FlinkKafkaConsumer<>(...))。
eg:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// read text file from local files system
DataSet<String> localLines = env.readTextFile("file:///path/to/my/textfile");
// read text file from an HDFS running at nnHost:nnPort
DataSet<String> hdfsLines = env.readTextFile("hdfs://nnHost:nnPort/path/to/my/textfile");
// read a CSV file with three fields
DataSet<Tuple3<Integer, String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.types(Integer.class, String.class, Double.class);
// read a CSV file with five fields, taking only two of them
DataSet<Tuple2<String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.includeFields("10010") // take the first and the fourth field
.types(String.class, Double.class);
// read a CSV file with three fields into a POJO (Person.class) with corresponding fields
DataSet<Person>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.pojoType(Person.class, "name", "age", "zipcode");
// read a file from the specified path of type SequenceFileInputFormat
DataSet<Tuple2<IntWritable, Text>> tuples =
env.createInput(HadoopInputs.readSequenceFile(IntWritable.class, Text.class, "hdfs://nnHost:nnPort/path/to/file"));
// creates a set from some given elements
DataSet<String> value = env.fromElements("Foo", "bar", "foobar", "fubar");
// generate a number sequence
DataSet<Long> numbers = env.generateSequence(1, 10000000);
// Read data from a relational database using the JDBC input format
DataSet<Tuple2<String, Integer> dbData =
env.createInput(
JdbcInputFormat.buildJdbcInputFormat()
.setDrivername("org.apache.derby.jdbc.EmbeddedDriver")
.setDBUrl("jdbc:derby:memory:persons")
.setQuery("select name, age from persons")
.setRowTypeInfo(new RowTypeInfo(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.INT_TYPE_INFO))
.finish()
);
// Note: Flink's program compiler needs to infer the data types of the data items which are returned
// by an InputFormat. If this information cannot be automatically inferred, it is necessary to
// manually provide the type information as shown in the examples above.
对于基于文件的输入,当输入路径为目录时,默认情况下不枚举嵌套文件。而是只读取基本目录中的文件,而忽略嵌套文件。可以通过recursive.file.enumeration配置参数启用嵌套文件的递归枚举,如以下示例所示:
// enable recursive enumeration of nested input files
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// create a configuration object
Configuration parameters = new Configuration();
// set the recursive enumeration parameter
parameters.setBoolean("recursive.file.enumeration", true);
// pass the configuration to the data source
DataSet<String> logs = env.readTextFile("file:///path/with.nested/files")
.withParameters(parameters);
3、DataStream转换
(1)数据接收器
writeAsText()/TextOutputFormat-将元素按行写为字符串。通过调用每个元素的toString()方法获得字符串。writeAsCsv(...)/CsvOutputFormat-将元组写为逗号分隔的值文件。行和字段定界符是可配置的。每个字段的值来自对象的toString()方法。print()/printToErr()-在标准输出/标准错误流上打印每个元素的toString()值。可选地,可以提供前缀(msg),该前缀在输出之前。这可以帮助区分打印的不同调用。如果并行度大于1,则输出之前还将带有产生输出的任务的标识符。writeUsingOutputFormat()/FileOutputFormat-的方法和自定义文件输出基类。支持自定义对象到字节的转换。writeToSocket-根据SerializationSchemaaddSink-调用自定义接收器功能。Flink与其他系统(例如Apache Kafka)的连接器捆绑在一起,这些系统已实现为接收器功能。
请注意:
1)write*()方法DataStream主要用于调试目的。它们不参与Flink的检查点(这些功能通常具有至少一次语义)。
2)刷新到目标系统的数据取决于OutputFormat的实现,即并非所有发送到OutputFormat的元素都立即显示在目标系统中。同样,在失败的情况下,这些记录可能会丢失。
3)为了将流可靠、准确地一次传输到文件系统中,请使用StreamingFileSink。同样,通过该.addSink(...)方法的自定义实现可以参与Flink一次精确语义的检查点。
eg:
// text data
DataSet<String> textData = // [...]
// write DataSet to a file on the local file system
textData.writeAsText("file:///my/result/on/localFS");
// write DataSet to a file on an HDFS with a namenode running at nnHost:nnPort
textData.writeAsText("hdfs://nnHost:nnPort/my/result/on/localFS");
// write DataSet to a file and overwrite the file if it exists
textData.writeAsText("file:///my/result/on/localFS", WriteMode.OVERWRITE);
// tuples as lines with pipe as the separator "a|b|c"
DataSet<Tuple3<String, Integer, Double>> values = // [...]
values.writeAsCsv("file:///path/to/the/result/file", "
", "|");
// this writes tuples in the text formatting "(a, b, c)", rather than as CSV lines
values.writeAsText("file:///path/to/the/result/file");
// this writes values as strings using a user-defined TextFormatter object
values.writeAsFormattedText("file:///path/to/the/result/file",
new TextFormatter<Tuple2<Integer, Integer>>() {
public String format (Tuple2<Integer, Integer> value) {
return value.f1 + " - " + value.f0;
}
});
自定义输出格式
DataSet<Tuple3<String, Integer, Double>> myResult = [...]
// write Tuple DataSet to a relational database
myResult.output(
// build and configure OutputFormat
JdbcOutputFormat.buildJdbcOutputFormat()
.setDrivername("org.apache.derby.jdbc.EmbeddedDriver")
.setDBUrl("jdbc:derby:memory:persons")
.setQuery("insert into persons (name, age, height) values (?,?,?)")
.finish()
);
本地排序输出
可以使用元组字段位置或字段表达式按指定顺序在指定字段上对数据接收器的输出进行本地排序。这适用于每种输出格式。
eg:
DataSet<Tuple3<Integer, String, Double>> tData = // [...]
DataSet<Tuple2<BookPojo, Double>> pData = // [...]
DataSet<String> sData = // [...]
// sort output on String field in ascending order
tData.sortPartition(1, Order.ASCENDING).print();
// sort output on Double field in descending and Integer field in ascending order
tData.sortPartition(2, Order.DESCENDING).sortPartition(0, Order.ASCENDING).print();
// sort output on the "author" field of nested BookPojo in descending order
pData.sortPartition("f0.author", Order.DESCENDING).writeAsText(...);
// sort output on the full tuple in ascending order
tData.sortPartition("*", Order.ASCENDING).writeAsCsv(...);
// sort atomic type (String) output in descending order
sData.sortPartition("*", Order.DESCENDING).writeAsText(...);
注:目前尚不支持全局排序的输出。
(2)控制延迟(设置使用流处理、批处理)
默认情况下,元素不会在网络上一对一传输(产生不必要的网络通信开销),通常会进行缓冲。缓冲区的大小可以在Flink配置文件中设置。控制吞吐量和延迟,可以在执行环境(或各个运算符)上使用来设置缓冲区填充的最大等待时间env.setBufferTimeout(timeoutMillis)。超过设置时间,即使缓冲区未满,也会自动发送缓冲区。
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.setBufferTimeout(timeoutMillis);//默认是100ms
env.generateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);
为了最大程度地提高吞吐量,设置setBufferTimeout(-1)表示永不超时,仅在缓冲区已满时才刷新缓冲区。最大程度地减少延迟,可以将超时设置为接近0的值(例如5或10 ms)(避免将缓冲区超时设置为0,可能导致严重的性能下降)。
4、执行模式(批处理/流式传输)
DataStream API支持不同的运行时执行模式,可以根据用例的要求和工作特征从中选择运行模式。
DataStream API有“经典”执行行为,称之为 STREAMING执行模式。应用于需要连续增量处理且有望无限期保持在线状态的无限制作业。另外,有一个批处理式执行模式,我们称为BATCH 执行模式。这以一种类似于批处理框架(如MapReduce)的方式执行作业。应用于具有已知固定输入且不会连续运行的有边界作业。
Apache Flink的流和批处理的统一方法意味着,无论配置的执行模式如何,在有界输入上执行的DataStream应用程序都将产生相同的最终结果。重要的是要注意final在这里意味着什么:以STREAMING模式执行的作业可能会产生增量更新(请考虑数据库中的upsert),而BATCH作业最后只会产生一个最终结果。如果正确解释,最终结果将是相同的,但到达那里的方式可能会有所不同。
通过启用BATCH执行,我们允许Flink应用其他优化,只有当我们知道输入是有限的时,我们才能做这些优化。
(1)配置BATCH执行模式
可以通过execution.runtime-mode设置配置执行模式。有三个可能的值:
STREAMING:经典的DataStream执行模式(默认)BATCH:在DataStream API上以批处理方式执行AUTOMATIC:让系统根据源的有界性来决定
可以通过的命令行参数进行配置bin/flink run ...,也可以在创建/配置时以编程方式进行配置StreamExecutionEnvironment。
通过命令行配置执行模式的方法如下:
$ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
此示例说明如何在代码中配置执行模式:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
5、Keyed DataStream(键控数据流)
(1)概念:
在flink中数据集为DataStream,对其进行分区时,会产生一个KeyedDataStream,然后允许使用Keyed DataStream的operator以及特有的state(如mapstate、valuestate等),keyby可以通过列下标选择使用列,也可以选择使用列名进行分区。
eg:
// some ordinary POJO
public class WC {
public String word;
public int count;
public String getWord() { return word; }
}
DataStream<WC> words = // [...]
KeyedStream<WC> keyed = words
.keyBy(WC::getWord);
三、Flink DataSet API
Flink中的DataSet程序是常规程序,可对数据集进行转换(例如,过滤,映射,联接,分组)。最初从某些来源(例如,通过读取文件或从本地集合)创建数据集。结果通过接收器返回,接收器可以例如将数据写入(分布式)文件或标准输出(例如命令行终端)。Flink程序可以在各种上下文中运行,独立运行或嵌入其他程序中。执行可以在本地JVM或许多计算机的群集中进行。
public class WordCountExample {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
1、DataSet转换
(1)数据转换将一个或多个数据集转换为新的数据集。程序可以将多种转换组合成复杂的程序集。
| Transformation | Description |
|---|---|
| Map | 一个输入数据对应一个输出数据,eg:将string转换成integer类型返回data.map(new MapFunction<String, Integer>() { public Integer map(String value) { |
| FlatMap | 一个输入数据对应多个输出数据,eg:将string分割成字符,通过collector以流的形式源源不断输出data.flatMap(new FlatMapFunction<String, String>() { public void flatMap(String value, Collector<String> out) { for (String s : value.split(" ")) { out.collect(s); } } }); |
| Filter | 过滤数据,保留过滤结果为true的部分。data.filter(new FilterFunction<Integer>() { public boolean filter(Integer value) { |
| Reduce | 将一组数据合并为一个data.reduce(new ReduceFunction<Integer> { public Integer reduce(Integer a, Integer b) { |
| Aggregate | Aggregates a group of values into a single value. Aggregation functions can be thought of as built-in reduce functions. Aggregate may be applied on a full data set, or on a grouped data set.
|
| Distinct | Returns the distinct elements of a data set. It removes the duplicate entries from the input DataSet, with respect to all fields of the elements, or a subset of fields.
CombineHint to setCombineHint. The hash-based strategy should be faster in most cases, especially if the number of different keys is small compared to the number of input elements (eg. 1/10). |
| Join | Joins two data sets by creating all pairs of elements that are equal on their keys. Optionally uses a JoinFunction to turn the pair of elements into a single element, or a FlatJoinFunction to turn the pair of elements into arbitrarily many (including none) elements. See the keys section to learn how to define join keys.
If no hint is specified, the system will try to make an estimate of the input sizes and pick the best strategy according to those estimates. |
| OuterJoin | Performs a left, right, or full outer join on two data sets. Outer joins are similar to regular (inner) joins and create all pairs of elements that are equal on their keys. In addition, records of the "outer" side (left, right, or both in case of full) are preserved if no matching key is found in the other side. Matching pairs of elements (or one element and a null value for the other input) are given to a JoinFunction to turn the pair of elements into a single element, or to a FlatJoinFunction to turn the pair of elements into arbitrarily many (including none) elements. See the keys section to learn how to define join keys.
|
| Cross | Builds the Cartesian product (cross product) of two inputs, creating all pairs of elements. Optionally uses a CrossFunction to turn the pair of elements into a single element
|
| Union | Produces the union of two data sets.
|
| First-n | Returns the first n (arbitrary) elements of a data set. First-n can be applied on a regular data set, a grouped data set, or a grouped-sorted data set. Grouping keys can be specified as key-selector functions or field position keys.
|
(2)在元组的数据集上可以进行以下转换:
| Transformation | Description |
|---|---|
| Project | Selects a subset of fields from the tuples
|
| MinBy / MaxBy | Selects a tuple from a group of tuples whose values of one or more fields are minimum (maximum). The fields which are used for comparison must be valid key fields, i.e., comparable. If multiple tuples have minimum (maximum) field values, an arbitrary tuple of these tuples is returned. MinBy (MaxBy) may be applied on a full data set or a grouped data set.
|
(3)指定key
某些转换(join,coGroup,groupBy)要求在元素集合上定义键。其他转换(Reduce,GroupReduce,Aggregate)允许在应用数据之前对数据进行分组。
DataSet<...> input = // [...]
DataSet<...> reduced = input
.groupBy(/*define key here*/)
.reduceGroup(/*do something*/);
Flink的数据模型不是基于键值对。因此,无需将数据集类型实际打包到键和值中。key是“虚拟的”,定义为对实际数据的功能,用于分组操作。
(4)用户定义的功能
实现接口方式
class MyMapFunction implements MapFunction<String, Integer> {
public Integer map(String value) { return Integer.parseInt(value); }
};
data.map(new MyMapFunction());
匿名类方式
data.map(new MapFunction<String, Integer> () {
public Integer map(String value) { return Integer.parseInt(value); }
});
Java 8 Lambdas(Flink在Java API中还支持Java 8 Lambda)
data.filter(s -> s.startsWith("http://"));
data.reduce((i1,i2) -> i1 + i2);
所有需要用户定义函数的转换都可以将Rich()函数作为参数。
eg:
class MyMapFunction implements MapFunction<String, Integer> {
public Integer map(String value) { return Integer.parseInt(value); }
};
可以替换为以下写法
class MyMapFunction extends RichMapFunction<String, Integer> {
public Integer map(String value) { return Integer.parseInt(value); }
};
将函数照常传递给map转换:
data.map(new MyMapFunction());
也可以定义为匿名类:
data.map (new RichMapFunction<String, Integer>() {
public Integer map(String value) { return Integer.parseInt(value); }
});
accumulators
首先,在要使用它的用户定义的转换函数中创建一个累加器对象(此处是一个计数器)。
private IntCounter numLines = new IntCounter();
其次,在rich函数的open()方法中 注册累加器对象。您还可以在此处定义名称。
getRuntimeContext().addAccumulator("num-lines", this.numLines);
在运算符函数中的任何位置(包括open()和 close()方法中)使用累加器。
this.numLines.add(1);
结果将存储在JobExecutionResult从execute()执行环境的方法返回的对象中(仅在执行等待作业完成时才起作用)。
myJobExecutionResult.getAccumulatorResult("num-lines")
所有累加器为每个作业共享一个名称空间。因此,可以在作业的不同操作功能中使用同一累加器。Flink将在内部合并所有具有相同名称的累加器。
注:累加器的结果仅在整个作业结束后才可用。
自定义累加器:
要实现自己的累加器,只需要编写累加器接口的实现即可。
若自定义累加器应随Flink一起提供,则可以随意创建拉取请求,可以选择实现 Accumulator 或SimpleAccumulator。
1)Accumulator<V,R>最灵活:它定义V要添加的值的类型,并定义R最终结果的结果类型。例如,对于直方图,V是一个数字,并且R是一个直方图。
2)SimpleAccumulator适用于两种类型相同的情况,例如计数器。
三、Operators
将一个或多个DataStream转换为新的DataStream。程序可以将多种转换组合成复杂的数据流拓扑。
1、DataStream Transformations
| Transformation | Description |
|---|---|
MapDataStream → DataStream |
输入一个数据返回一个数据,eg:对输入数据*2返回DataStream<Integer> dataStream = //... dataStream.map(new MapFunction<Integer, Integer>() { @Override public Integer map(Integer value) throws Exception { return 2 * value; } }); |
FlatMapDataStream → DataStream |
数据一个数据以数据流的形式返回,eg:将字符串拆分为字符,通过collector以流的形式返回dataStream.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String value, Collector<String> out) throws Exception { for(String word: value.split(" ")){ out.collect(word); } } }); |
FilterDataStream → DataStream |
过滤数据,保留结果为true的数据dataStream.filter(new FilterFunction<Integer>() { @Override public boolean filter(Integer value) throws Exception { return value != 0; } }); |
KeyByDataStream → KeyedStream |
将dataStream转换为keyedStream,原理:在逻辑上将流划分为不相交的分区,具有相同key的记录都分配到同一个分区; 在内部,keyBy() 是通过哈希分区实现的。 dataStream.keyBy(value -> value.getSomeKey()) // Key by field "someKey" dataStream.keyBy(value -> value.f0) // Key by the first element of a Tuple
|
ReduceKeyedStream → DataStream |
减少keyedStream的滚动,将上一条reduced’的数据和当前数据合并,产生新的结果。keyedStream.reduce(new ReduceFunction<Integer>() { @Override public Integer reduce(Integer value1, Integer value2) throws Exception { return value1 + value2; } }); |
AggregationsKeyedStream → DataStream |
聚合函数keyedStream.sum(0); keyedStream.sum("key"); keyedStream.min(0); keyedStream.min("key"); keyedStream.max(0); keyedStream.max("key"); keyedStream.minBy(0); keyedStream.minBy("key"); keyedStream.maxBy(0); keyedStream.maxBy("key"); |
WindowKeyedStream → WindowedStream |
在已经分区的keyedStream上定义windows,windows根据某些特征对每个key中的数据进行分组。dataStream.keyBy(value -> value.f0).window(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data |
WindowAllDataStream → AllWindowedStream |
在普通数据流上定义windows,windows根据某些特征对所有流事件进行分组(非并行转换操作,所有记录合并成一个任务进行windowAll操作)dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data |
Window ApplyWindowedStream → DataStreamAllWindowedStream → DataStream |
将通用函数应用于整个窗口,eg:手动对窗口元素求和。windowedStream.apply (new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>() { public void apply (Tuple tuple, Window window, Iterable<Tuple2<String, Integer>> values, Collector<Integer> out) throws Exception { int sum = 0; for (value t: values) { sum += t.f1; } out.collect (new Integer(sum)); } }); // applying an AllWindowFunction on non-keyed window stream allWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>, Integer, Window>() { public void apply (Window window, Iterable<Tuple2<String, Integer>> values, Collector<Integer> out) throws Exception { int sum = 0; for (value t: values) { sum += t.f1; } out.collect (new Integer(sum)); } }); |
Window ReduceWindowedStream → DataStream |
window上执行reduce()函数windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() { public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception { return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1); } }); |
Aggregations on windowsWindowedStream → DataStream |
聚合函数windowedStream.sum(0); windowedStream.sum("key"); windowedStream.min(0); windowedStream.min("key"); windowedStream.max(0); windowedStream.max("key"); windowedStream.minBy(0); windowedStream.minBy("key"); windowedStream.maxBy(0); windowedStream.maxBy("key"); |
UnionDataStream* → DataStream |
合并 data streams(如果dataStream和自身合并,则在结果中会出现两次) |
Window JoinDataStream,DataStream → DataStream |
Join two data streams on a given key and a common window.
|
Interval JoinKeyedStream,KeyedStream → DataStream |
Join two elements e1 and e2 of two keyed streams with a common key over a given time interval, so that e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
|
Window CoGroupDataStream,DataStream → DataStream |
Cogroups two data streams on a given key and a common window.
|
ConnectDataStream,DataStream → ConnectedStreams |
"Connects" two data streams retaining their types. Connect allowing for shared state between the two streams.
|
CoMap, CoFlatMapConnectedStreams → DataStream |
Similar to map and flatMap on a connected data stream
|
IterateDataStream → IterativeStream → DataStream |
Creates a "feedback" loop in the flow, by redirecting the output of one operator to some previous operator. This is especially useful for defining algorithms that continuously update a model. The following code starts with a stream and applies the iteration body continuously. Elements that are greater than 0 are sent back to the feedback channel, and the rest of the elements are forwarded downstream.
|
以下转换用于tuples的dataStream上:
| Transformation | Description |
|---|---|
ProjectDataStream → DataStream |
Selects a subset of fields from the tuples
|
2、物理分区
Flink还通过以下功能对转换后的确切流分区进行了底层控制。
| Transformation | Description |
|---|---|
Custom partitioningDataStream → DataStream |
Uses a user-defined Partitioner to select the target task for each element.
|
Random partitioningDataStream → DataStream |
Partitions elements randomly according to a uniform distribution.
|
Rebalancing (Round-robin partitioning)DataStream → DataStream |
Partitions elements round-robin, creating equal load per partition. Useful for performance optimization in the presence of data skew.
|
BroadcastingDataStream → DataStream |
Broadcasts elements to every partition.
|
3、任务链和资源组
链接两个后续的转换意味着将它们共同定位在同一线程内以获得更好的性能。默认情况下Flink会链接运算符(例如,两个后续的映射转换),API可以对链接进行细粒度的控制。如果要在整个作业中禁用链接,使用StreamExecutionEnvironment.disableOperatorChaining()。
备注:这些函数只能在DataStream转换后使用,因为它们引用的是先前的转换。例如,可以使用someStream.map(...).startNewChain(),但不能使用someStream.startNewChain()。
资源组是Flink中的slot。
| Transformation | Description |
|---|---|
| Start new chain | Begin a new chain, starting with this operator. The two mappers will be chained, and filter will not be chained to the first mapper.
|
| Disable chaining | Do not chain the map operator
|
| Set slot sharing group | Set the slot sharing group of an operation. Flink will put operations with the same slot sharing group into the same slot while keeping operations that don't have the slot sharing group in other slots. This can be used to isolate slots. The slot sharing group is inherited from input operations if all input operations are in the same slot sharing group. The name of the default slot sharing group is "default", operations can explicitly be put into this group by calling slotSharingGroup("default").
|
4、Windows
Windows是处理无限流的核心。Windows将流分成有限大小的“存储桶”。
(0)窗口化Flink程序的一般结构如下所示:
Keyed Windows(键控流)
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows(非键控流)
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
在上面,方括号([…])中的命令是可选的。Flink允许以多种不同方式自定义窗口逻辑,使其最切合需求。
(1)Window Assigners(窗口分配器)
窗口分配器定义了如何将元素分配给窗口,WindowAssigner 在window(...)(键控流)或windowAll()(非键控流)函数中调用。WindowAssigner负责将每个传入元素分配给一个或多个窗口。Flink 为最常见的用例提供了预定义的窗口分配器,即滚动窗口、 滑动窗口、会话窗口和全局窗口,还可以通过扩展WindowAssigner类来实现自定义窗口分配器。所有内置窗口分配器(全局窗口除外)都根据时间将元素分配给窗口,时间可以是处理时间或事件时间。
基于时间的窗口通过开始时间戳(包括)和一个结束时间戳(不包括)表示窗口大小。在代码中,FlinkTimeWindow在处理基于时间窗口时使用,该窗口具有查询开始和结束时间戳的方法maxTimestamp(),以及返回给定窗口的最大允许时间戳。
下图可视化描述每个分配器的工作原理。紫色圆圈代表流的元素,它们由某个key(在本例中为user 1、user 2和user 3)分区。x 轴显示时间的进展。
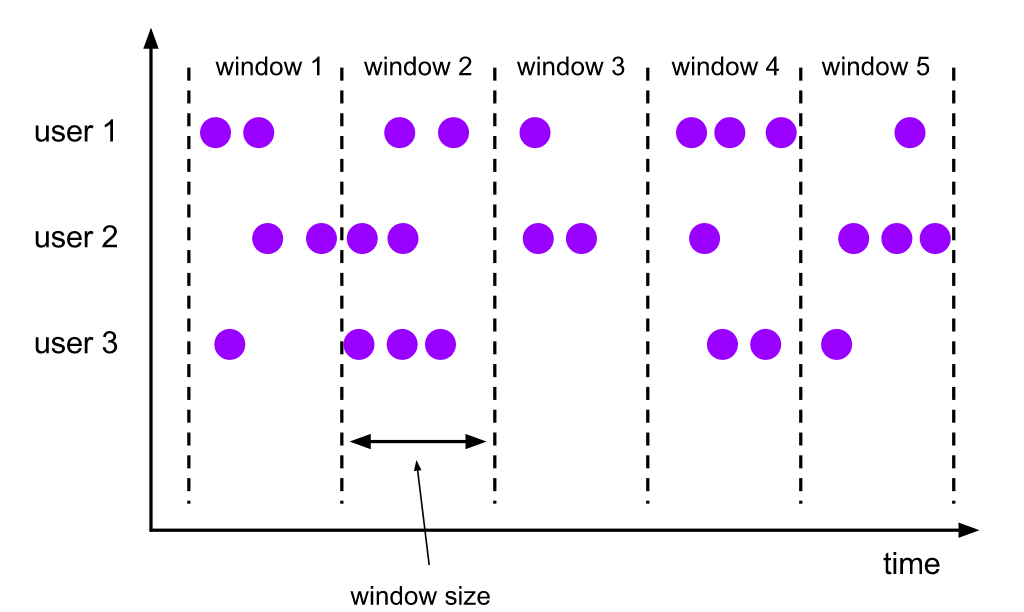
(1.1)翻滚视窗
翻滚视窗分配器分配每一个元素到固定大小的窗口(滚动窗口具有固定的大小且不重叠)。
eg:如果指定大小为5分钟的翻滚窗口,从当前窗口开始计算,每五分钟将启动一个新窗口,如下图所示
代码示例:
DataStream<T> input = ...;
// tumbling event-time windows
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// tumbling processing-time windows
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>);
时间间隔可以通过Time.milliseconds(x),Time.seconds(x), Time.minutes(x)等添加。如上面最后一个示例,滚动窗口分配器采用offset(可选) 参数,用于更改窗口的对齐方式。若没有offsets ,则时间滚动窗口与epoch对齐,即1:00:00.000 - 1:59:59.999,2:00:00.000 - 2:59:59.999等;如果offset设置为15分钟,则得到如 1:15:00.000 - 2:14:59.999,2:15:00.000 - 3:14:59.999等,即offset可以用来调整窗口时区为UTC-0以外的时区,如采用中国时区,必须指定的偏移量Time.hours(-8)。
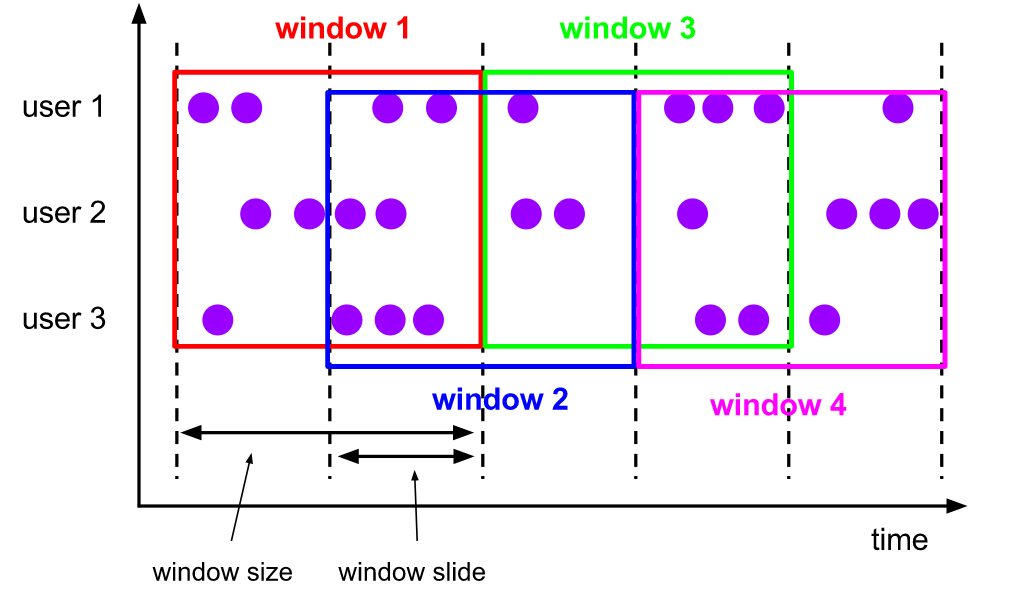
(1.2)滑动窗
类似于滚动窗口分配器,窗口的大小由窗口大小参数配置,同时窗口滑动参数控制滑动窗口启动的频率。因此,如果slide参数小于窗口大小,则滑动窗口可能会重叠。在这种情况下,元素被分配给多个窗口。
例如,可以将大小为10分钟的窗口滑动5分钟。这样,每隔5分钟就会得到一个窗口,其中包含最近10分钟内到达的事件,如下图所示:
DataStream<T> input = ...;
// sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// sliding processing-time windows
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// sliding processing-time windows offset by -8 hours
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>);
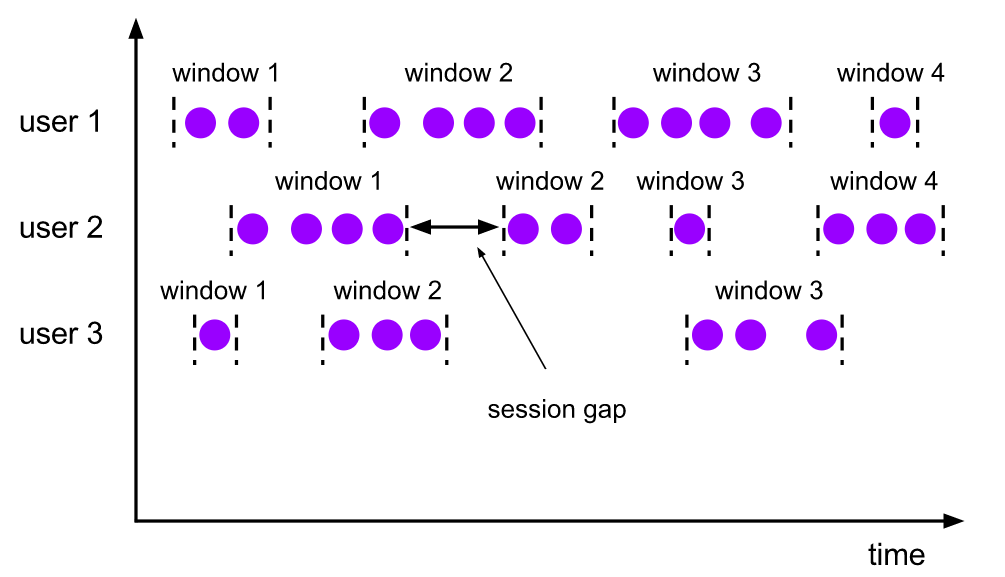
(1.3)会话窗口
与滚动窗口和滑动窗口相比,会话窗口不重叠且没有固定的开始和结束时间。相反,当会话窗口在一定时间段内未收到元素时(即不活动间隙),它将关闭。会话窗口分配器可与静态配置会话间隙或与会话间隙函数(指定不活动周期)使用。当此时间段到期时,当前会话将关闭,随后的元素将分配给新的会话窗口。
DataStream<T> input = ...;
// event-time session windows with static gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// event-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap((element) -> {
// determine and return session gap
}))
.<windowed transformation>(<window function>);
// processing-time session windows with static gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// processing-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// determine and return session gap
}))
.<windowed transformation>(<window function>);
静态间隙可以通过Time.milliseconds(x),Time.seconds(x), Time.minutes(x)等设置。动态间隙是通过实现SessionWindowTimeGapExtractor接口指定的。
注意由于会话窗口没有固定的开始和结束,在内部,会话窗口运算符会为每个到达的记录创建一个新窗口,如果窗口彼此之间比已定义的间隔小,则将它们进行merge操作。(merge操作,会话窗口操作需要一个merge触发器以及merge的window函数,如ReduceFunction,AggregateFunction或ProcessWindowFunction)
(1.4)全局窗口
全局窗口分配器对同单个窗口分配相同的key元素。当指定了自定义触发器时,此窗口schema才有用。否则,将不会执行任何计算,因为当执行聚合函数时,全局窗口不会自动结束。

DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>);
2、Window Functions
(2.1)Reduce功能
ReduceFunction指定如何将输入中的两个元素组合在一起以产生相同类型的输出元素。Flink使用aReduceFunction来逐步聚合窗口的元素。
eg:
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new ReduceFunction<Tuple2<String, Long>> {
public Tuple2<String, Long> reduce(Tuple2<String, Long> v1, Tuple2<String, Long> v2) {
return new Tuple2<>(v1.f0, v1.f1 + v2.f1);
}
});
(2.2)聚合函数
一个AggregateFunction是一个一般化版本ReduceFunction,其具有三种类型:输入类型(IN),蓄压式(ACC),和一个输出类型(OUT)。输入类型是输入流中元素的类型,并且AggregateFunction具有将一个输入元素添加到累加器的方法。该接口还具有创建初始累加器,将两个累加器合并为一个累加器以及OUT从累加器提取输出(类型)的方法。我们将在下面的示例中看到它的工作原理。
与ReduceFunction一样,Flink将在窗口输入元素到达时增量地聚合它们。
一个AggregateFunction可以被定义并这样使用:
/**
* The accumulator is used to keep a running sum and a count. The {@code getResult} method
* computes the average.
*/
private static class AverageAggregate
implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate());
(2.3)ProcessWindowFunction
ProcessWindowFunction获得一个Iterable,该Iterable包含窗口的所有元素,以及一个可以访问时间和状态信息的Context对象,这使其能够比其他窗口函数提供更大的灵活性。这是以性能和资源消耗为代价的,因为不能增量聚合元素,而是需要在内部对其进行缓冲,直到认为该窗口已准备好进行处理为止。
ProcessWindowFunction:
public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window> implements Function {
/**
* Evaluates the window and outputs none or several elements.
*
* @param key The key for which this window is evaluated.
* @param context The context in which the window is being evaluated.
* @param elements The elements in the window being evaluated.
* @param out A collector for emitting elements.
*
* @throws Exception The function may throw exceptions to fail the program and trigger recovery.
*/
public abstract void process(
KEY key,
Context context,
Iterable<IN> elements,
Collector<OUT> out) throws Exception;
/**
* The context holding window metadata.
*/
public abstract class Context implements java.io.Serializable {
/**
* Returns the window that is being evaluated.
*/
public abstract W window();
/** Returns the current processing time. */
public abstract long currentProcessingTime();
/** Returns the current event-time watermark. */
public abstract long currentWatermark();
/**
* State accessor for per-key and per-window state.
*
* <p><b>NOTE:</b>If you use per-window state you have to ensure that you clean it up
* by implementing {@link ProcessWindowFunction#clear(Context)}.
*/
public abstract KeyedStateStore windowState();
/**
* State accessor for per-key global state.
*/
public abstract KeyedStateStore globalState();
}
}
注意:Tuple必须手动将其强制转换为正确大小的元组以提取key字段。
ProcessWindowFunction可以定义成这样使用(ProcessWindowFunction计算窗口中元素的方法):
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction());
/* ... */
public class MyProcessWindowFunction
extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {
long count = 0;
for (Tuple2<String, Long> in: input) {
count++;
}
out.collect("Window: " + context.window() + "count: " + count);
}
}
注意将ProcessWindowFunction简单的聚合(例如count)效率很低。
(2.4)具有增量聚合的ProcessWindowFunction
ProcessWindowFunction可与一组合ReduceFunction,或AggregateFunction因为它们在窗口到达逐步聚合的元件。窗口关闭后,ProcessWindowFunction将提供汇总结果。这样一来,它便可以递增地计算窗口,同时可以访问的其他窗口元信息ProcessWindowFunction。
注意也可以使用旧版WindowFunction而不是 ProcessWindowFunction用于增量窗口聚合。
具有ReduceFunction的增量窗口聚合
eg:如何将增量ReduceFunction与ProcessWindowFunction组合以返回窗口中的最小事件以及该窗口的开始时间:
DataStream<SensorReading> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new MyReduceFunction(), new MyProcessWindowFunction());
// Function definitions
private static class MyReduceFunction implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r2 : r1;
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<SensorReading, Tuple2<Long, SensorReading>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<SensorReading> minReadings,
Collector<Tuple2<Long, SensorReading>> out) {
SensorReading min = minReadings.iterator().next();
out.collect(new Tuple2<Long, SensorReading>(context.window().getStart(), min));
}
}
具有AggregateFunction的增量窗口聚合
eg:如何将增量AggregateFunction与一个组合ProcessWindowFunction以计算平均值,并与平均值一起发出键和窗口:
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate(), new MyProcessWindowFunction());
// Function definitions
/**
* The accumulator is used to keep a running sum and a count. The {@code getResult} method
* computes the average.
*/
private static class AverageAggregate
implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<Double, Tuple2<String, Double>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<Double> averages,
Collector<Tuple2<String, Double>> out) {
Double average = averages.iterator().next();
out.collect(new Tuple2<>(key, average));
}
}
3、Triggers
Trigger确定窗口(由窗口分配器形成)何时准备好由窗口函数处理。每个WindowAssigner都有一个默认值Trigger。如果默认触发器不符合您的需求,则可以使用指定自定义触发器trigger(...)。
触发器接口具有五种方法,它们允许aTrigger对不同事件做出反应:
-
onElement()对于添加到窗口中的每个元素,都会调用该方法。 -
onEventTime()当注册的事件时间计时器触发时,将调用该方法。 -
onProcessingTime()当注册的处理时间计时器触发时,将调用该方法。 -
该
onMerge()方法与有状态触发器相关,并且在两个触发器的相应窗口合并时(例如,在使用会话窗口时)合并两个触发器的状态。 -
最后,该
clear()方法执行删除相应窗口后所需的任何操作。
关于上述方法,需要注意两件事:
1)前三个通过返回来决定如何对它们的调用事件采取行动TriggerResult。该动作可以是以下之一:
CONTINUE: 没做什么FIRE:触发计算PURGE:清除窗口中的元素FIRE_AND_PURGE:触发计算并随后清除窗口中的元素。
2)这些方法中的任何一种均可用于以后operator注册(处理或时间)事件计时器。
4、允许迟到
(1)定义
当使用事件时间窗口时,元素可能会延迟到达,即Flink 用来跟踪事件时间进度的水印已经超过了元素所属窗口的结束时间戳。默认情况下,当水印超过窗口末尾时,将删除后期元素。但是,Flink 允许为窗口操作符指定最大允许延迟。Allowed lateness 指定元素在被丢弃之前可以延迟多长时间,其默认值为 0。 在 watermark 已经通过窗口末尾之后但在它通过窗口末尾之前到达的元素加上允许的延迟,仍然添加到窗口中。根据使用的触发器,延迟但未丢弃的元素可能会导致窗口再次触发。对于EventTimeTrigger.为了完成这项工作,Flink 会保持窗口的状态,直到它们允许的延迟到期。一旦发生这种情况,Flink 将移除窗口并删除其状态。
默认情况下,允许的延迟设置为 0,即到达水印之后的元素将被丢弃。
允许的延迟代码示例:
DataStream<T> input = ...; input .keyBy(<key selector>) .window(<window assigner>) .allowedLateness(<time>) .<windowed transformation>(<window function>);
注意:当使用GlobalWindows窗口分配器时,没有数据被认为是延迟的,因为全局窗口的结束时间戳是Long.MAX_VALUE。
(2)获取延迟数据作为侧流输出
使用Flink的侧流输出功能,可以获取最近被丢弃的数据流。
final OutputTag<T> lateOutputTag = new OutputTag<T>("late-data"){};
DataStream<T> input = ...;
SingleOutputStreamOperator<T> result = input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(<time>)
.sideOutputLateData(lateOutputTag)
.<windowed transformation>(<window function>);
DataStream<T> lateStream = result.getSideOutput(lateOutputTag);
5、状态大小注意事项:
Windows可以定义很长时间(例如几天,几周或几个月),因此会累积很大的状态。在估算窗口计算的存储需求时,有以下规则:
-
Flink为每个窗口所属的每个元素创建一个副本。鉴于此,滚动窗口保留每个元素的一个副本(一个元素恰好属于一个窗口,除非被延迟放置)。相反,滑动窗口会为每个元素创建多个。因此,并不推荐大小为1天的滑动窗口和滑动1秒的滑动窗口。
-
ReduceFunction和AggregateFunction极大地减少了存储需求,因为它们聚合了元素,且每个窗口仅存储一个值。相反,使用ProcessWindowFunction需要累积所有元素。 -
使用
Evictor防止了任何预聚合,作为窗口的所有元件必须通过evictor()施加的计算。
6、WindowAssigners 的默认触发器
默认Trigger的WindowAssigner是适用于很多情况。例如,所有事件时间窗口分配器都有一个EventTimeTrigger作为默认触发器。一旦水印通过窗口的末尾,这个触发器就会触发。
注意:
(1)GlobalWindow默认触发器是NeverTrigger(从不触发),使用全局窗口时需要自定义一个触发器。
(2)使用指定触发器trigger(),将覆盖WindowAssigner的默认触发器。
四、Side Outputs(侧面输出流)
除了DataStream操作产生的主流之外,还可以附加产生任意数量的侧面输出流。侧流中的数据类型不必与主流中的数据类型匹配,并且不同侧输出的类型也可以不同。拆分数据流时,通常必须复制该流,然后从每个流中过滤掉不需要的数据。
定义一个OutputTag用于标识侧面输出流的:
// 这需要是一个匿名的内部类,以便我们分析类型
OutputTag<String> outputTag = new OutputTag<String>("side-output") {};可以通过以下功能将数据发送到侧面输出:
-
过程功能
-
KeyedProcessFunction
-
协同处理功能
-
KeyedCoProcessFunction
-
ProcessWindowFunction
-
ProcessAllWindowFunction
使用上述方法中向用户暴露Context 参数,将数据发送到由 OutputTag 标识的侧流中。
eg:从 ProcessFunction 发送数据到侧流输出
DataStream<Integer> input = ...;
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
SingleOutputStreamOperator<Integer> mainDataStream = input
.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(
Integer value,
Context ctx,
Collector<Integer> out) throws Exception {
// emit data to regular output
out.collect(value);
// emit data to side output
ctx.output(outputTag, "sideout-" + String.valueOf(value));
}
});
在 DataStream 运算结果上使用 getSideOutput(OutputTag) 方法获取旁路输出流,会产生一个与侧面输出流结果类型一致的 DataStream。
eg:
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
SingleOutputStreamOperator<Integer> mainDataStream = ...;
DataStream<String> sideOutputStream = mainDataStream.getSideOutput(outputTag);
flink官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/concepts/index.html
借鉴了不少文章,感谢各路大神分享,如需转载请注明出处,谢谢:https://www.cnblogs.com/huyangshu-fs/p/14489114.html