在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数。假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地训练迭代,使得a越来越接近y,即 a - y →0,而训练的本质就是寻找损失函数最小值的过程。
常见的损失函数为两种,一种是均方差函数,另一种是交叉熵函数。对于深度学习而言,交叉熵函数要优于均方差函数,原因在于交叉熵函数配合输出层的激活函数如sigmoid或softmax函数能更快地加速深度学习的训练速度。这是为什么呢?让我们来详细了解下。
一、函数定义
1. 第一种损失函数:均方差函数,其定义为:
L(a, y) = ½ (a - y)2
令y=0,则L(a, y) = ½ a2 ,当a处于(-1, 1)区间范围时,其图形特征为:
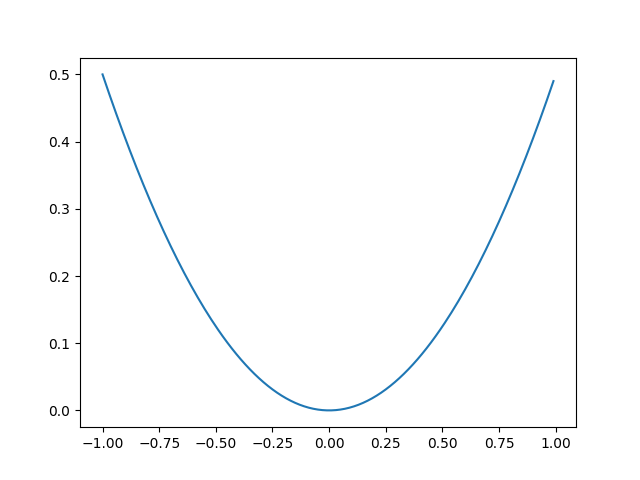
可以看出当y = 0, a =0时,L(a, y) →0,其值是最小的。
其求导公式为:dL(a, y) / da = a - y, 从函数本身来看当a = y时,L' (a, y) = 0,也即求得最小值。
2. 第二种损失函数:交叉熵函数,其定义为:
L(a, y) = - [y * ln a + (1 - y) ln (1 - a)]
为什么该函数能帮我们找到最小值呢?假设a和y都是在(0, 1)这个区间内取值。
令 y=0, 则 L(a, y) = - ln (1 - a), 当a →0时, L(a, y) ≈ - ln 1 = 0
当a →1时, L(a, y) ≈ - ln 0 = +∞
故y=0, a=0时,L(a, y) →0,符合找到最小值的目标。图形解释如下:
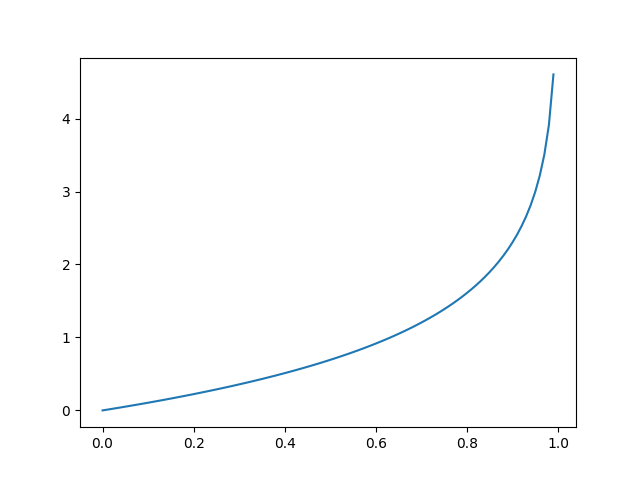
反之,令 y=1, 则 L(a, y) = - ln a, 当a →0时, L(a, y) ≈ - ln 0 = +∞
当a →1时, L(a, y) ≈ - ln 1 = 0
故y=1, a=1时,L(a, y) →0,也符合找到最小值的目标。图形解释如下:
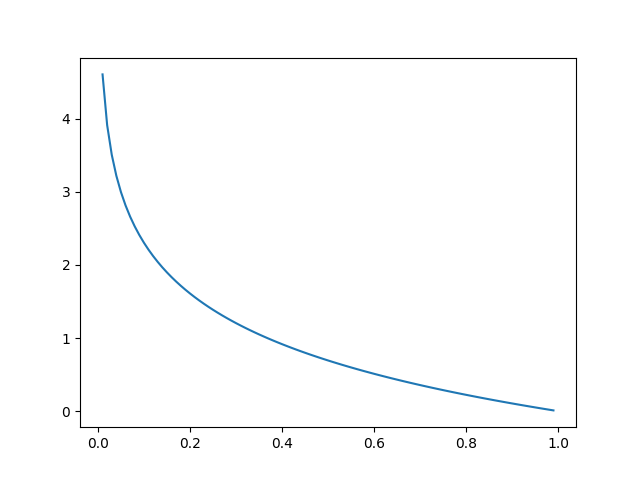
当然,我们也可以令y=0.5,则 L(a, y) = -[0.5 * ln a + 0.5 * ln (1 - a)]。
同样可以绘制出其图形:
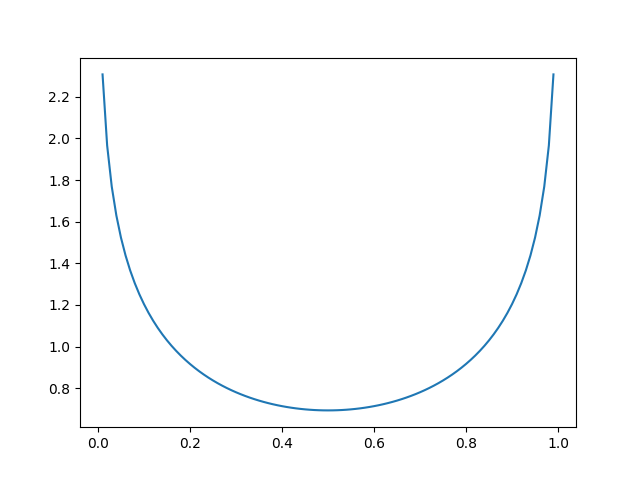
可以发现,当y=0.5, a=0.5时, L(a, y) →0,也符合找到最小值的目标。
以上描述简单地证明交叉熵函数是一个有效寻找最小值目标的损失函数。
以下代码可以简单地绘制出上述交叉熵函数的图形特征:
import numpy as np import matplotlib.pyplot as plt def loss_5(x): return -0.5 * np.log(x) - 0.5 * np.log(1 - x) def loss_0(x): return -1 * np.log(1 - x) def loss_1(x): return -1 * np.log(x) x = np.arange(0, 1, 0.01) y = loss_5(x) plt.plot(x, y) plt.show()
最后,我们来求导下交叉熵函数,以为后续证明用:
dL(a, y)/da = (- [y * ln a + (1 - y) ln (1 - a)])'
= -(y / a + (-1) * (1 -y) / (1 - a))
= - y / a + (1- y) / (1 - a )
= (a - y) / [a * (1 - a)]
二、为什么交叉熵函数优于均方差函数?
前面的内容已让我们了解两种函数的特点,现在让我们看看为什么交叉熵函数要优于均方差函数。我们知道深度学习的训练过程是通过梯度下降法反向传播更新参数值,具体来说,每一次前向传播结束后,通过对损失函数+激活函数反向在每一层对每个w和b参数进行求导,得到dL/dw和dL/db的值,最后更新w和b,即 w → w - λ * dL/dw,b → b - λ * dL/db,其中λ为学习率。
我们假设激活函数定义为sigmoid函数,并有如下前向传播路径:
z1 = w1 x + b1
a1= sigmoid(z1)
z2 = w2 a1 + b2
a2= sigmoid(z2)
在此条件下,我们看看均方差函数和交叉熵函数在反向传播上的求导结果:
1. 均方差函数+sigmoid函数的反向求导:
令L(a, y) = ½ (a - y)2 ,由前述可知,其求导为:L'(a, y) = a - y
而激活函数sigmoid的求导为:a' (z) = a (1 - a)
我们对w2进行求导,由链式法则可知:
dL/dw2 = dL/da2 * da2/dz2 * dz2/dw2
= (a2 - y) * a2(1 - a2) * a1
2. 交叉熵函数+sigmoid函数的反向求导:
令L(a, y) = - [y * ln a + (1 - y) ln (1 - a)],其求导为:L'(a, y) = (a - y) / [a * (1 - a)]
同样激活函数sigmoid的求导为:a' (z) = a (1 - a)
我们依旧对w2进行求导,由链式法则可知:
dL/dw2 = dL/dσ2 * dσ2/dz2 * dz2/dw2
= (a2 - y) / [a2 * (1 - a2)] * a2(1 - a2) * a1
= (a2 - y) * a1
比较上述两个反向求导w2的结果,有没有发现交叉熵函数的求导结果要更简洁,因为它没有 a2(1 - a2) 这一项,即输出层激活函数a2的自身求导。没有它非常重要,通过前文深度学习基础系列(三)| sigmoid、tanh和relu激活函数的直观解释, 我们可知激活函数的自身斜率在趋近两端时变得很平滑,这也意味着反向求导时迭代值dL/dw会比较小,从而使得训练速度变慢,这即是交叉熵函数优于均方差函数的原因。
也许大家会问,在sigmoid函数上交叉熵函数占优,那在softmax函数上又表现如何呢?我们继续验证,前向传播图作如下改造:
z1 = w1 x + b1
a1= sigmoid(z1)
z2 = w2 a1 + b2
a2= softmax(z2)
假设softmax最后的输出结果a2是由三个分类值组成,即y1 + y2 + y3 = 1,三种分类的概率和为1,其中y1 概率为0.9,y2 概率为0.05,y3 的概率为0.05。自然,我们希望某个分类的概率最接近1,以说明这个分类就是我们的预测值,因此可认为y = 1。 而激活函数softmax,参考前文深度学习基础系列(四)| 理解softmax函数,
令y1 = ex1 / (ex1 + ex2 + ex3 )
y2 = ex2 / (ex1 + ex2 + ex3 )
y3 = ex3 / (ex1 + ex2 + ex3 )
可知其求导为:
dy1/dx1 = y1 (1 - y1)
dy2/dx1 = - y1 * y2
dy3/dx1 = - y1 * y3
在此条件下,我们看看均方差函数和交叉熵函数在反向传播上的求导结果:
3. 均方差函数+softmax函数的反向求导:
若在y1进行反向求导,令L(y1, y) = ½ (y1 - y)2 ,其求导为:L'(y1, y) = y1 - y = y1 - 1
我们对w2进行求导,由链式法则可知:
dL/dw2 = dL/dy1 * dy1/dz2 * dz2/dw2
= (y1 - 1) * y1(1 - y1) * a1
另一方面,若在y2进行反向求导,令L(y2, y) = ½ (y2 - y)2 ,其求导为:L'(y2, y) = y2 - y = y2 - 1
我们对w2进行求导,由链式法则可知:
dL/dw2 = dL/dy2 * dy2/dz2 * dz2/dw2
= (y2 - 1) * (- y1 * y2) * a1
4. 交叉熵函数+softmax函数的反向求导:
若在y1进行反向求导,令 - [y * ln y1 + (1 - y) ln (1 - y1)],其求导为:L'(y1, y) = (y1 - y) / [y1 * (1 - y1)] = (y1 - 1) / [y1 * (1 - y1)] = -1/y1
我们对w2进行求导,由链式法则可知:
dL/dw2 = dL/dy1 * dy1/dz2 * dz2/dw2
= -1/y1 * y1(1 - y1) * a1
= - (1 - y1) * a1
另一方面,若在y2进行反向求导,令 - [y * ln y2 + (1 - y) ln (1 - y2)],其求导为:L'(y2, y) = (y2 - y) / [y2 * (1 - y2)] = (y2 - 1) / [y2 * (1 - y2)] = -1/y2
我们对w2进行求导,由链式法则可知:
dL/dw2 = dL/dy2 * dy2/dz2 * dz2/dw2
= -1/y2 * (- y1 * y2) * a1
= y1 * a1
综上比较,交叉熵函数在反向求导中,依旧完美地避开了softmax函数自身导数的影响,还是优于均方差函数。
还需补充的是,在反向传播过程中,每一层对w和b求导,通过链式法则可知,依旧会受到该层的激活函数影响,若为sigmoid函数,依然不可避免地降低学习速度。因此深层网络中隐藏层的激活函数目前大都为relu函数,可以确保其导数要么为0,要么为1。
三、交叉熵函数在tensorflow和keras的实现说明
1. sigmoid + 交叉熵函数
在tensorflow上体现为sigmoid_cross_entropy_with_logits,对应的官网地址为:https://www.tensorflow.org/api_docs/python/tf/nn/sigmoid_cross_entropy_with_logits
说明:可应用于二元分类,如判断一张图片是否为猫;但如果图片里有多个分类,也并不互斥,比如一张图片里既包含狗,也包含猫,但如果我们给了猫和狗两个标签,那判断这张图片,既可以认为是狗,也可以认为是猫。
官网已给出数学推导后的公式:
L = max(x, 0) - x * z + log(1 + exp(-abs(x))),其中x可认为是logits,z可认为是labels
举一个简单的例子:
import keras.backend as K from tensorflow.python.ops import nn y_target = K.constant(value=[1]) y_output = K.constant(value=[1]) print("y_target: ", K.eval(y_target)) print("y_output: ", K.eval(y_output)) print("the loss is: ", K.eval(nn.sigmoid_cross_entropy_with_logits(labels=y_target, logits=y_output)))
结果为:
y_target: [1.] y_output: [1.] the loss is: [0.3132617]
可以把参数带入公式验证:max(1, 0) - 1 * 1 + log(1 + exp(-abs(1))) = ln(1 + e-1) = 0.3132617
而在keras上体现为binary_crossentropy,用途与上面的sigmoid_cross_entropy_with_logits是一样的,但两者有差别:
sigmoid_cross_entropy_with_logits还原了预计值和输出值在数学公式中的差值,但不是一种概率差。上述例子中,输出值和预计值明明一样,概率差应该为0,但结果却为0.3132617
而binary_crossentropy则先把输出值进行概率包装后,再带入sigmoid_cross_entropy_with_logits数学公式中。
举一个例子:
import keras.backend as K from tensorflow.python.ops import math_ops from tensorflow.python.ops import clip_ops from tensorflow.python.framework import ops y_target = K.constant(value=[1]) y_output = K.constant(value=[1]) print("y_target: ", K.eval(y_target)) print("y_output: ", K.eval(y_output)) epsilon_ = ops.convert_to_tensor(K.epsilon(), y_output.dtype.base_dtype) print("epsilon: ", K.eval(epsilon_)) output = clip_ops.clip_by_value(y_output, epsilon_, 1 - epsilon_) print("output: ", K.eval(output)) output = math_ops.log(output / (1 - output)) print("output: ", K.eval(output))
print("the loss is: ", K.eval(nn.sigmoid_cross_entropy_with_logits(labels=y_target, logits=output)))
结果为:
y_target: [1.] y_output: [1.] epsilon: 1e-07 output: [0.9999999] output: [15.942385] the loss is: [1.1920933e-07]
最后的结果1.1920933e-07相当于0.00000012,符合我们对预测值和输出值差别不大的认知。因此可以理解keras的损失函数输出值更加人性化。
2. softmax + 交叉熵函数
在tensorflow上体现为softmax_cross_entropy_with_logits_v2,对应的官网地址为:https://www.tensorflow.org/api_docs/python/tf/nn/softmax_cross_entropy_with_logits_v2
说明:可用于多元分类,如判断一张图片是否为猫;但如果图片里多个类别则是互斥的,比如一张图片里既包含狗,也包含猫,那我们也只能给唯一的标签,要么是狗,要么是猫。
其数学公式为:L = ∑ -(y * lna)
举个例子说明:
import keras.backend as K from tensorflow.python.ops import nn y_target = K.constant(value=[1, 2]) y_output = K.constant(value=[1, 2]) print("y_target: ", K.eval(y_target)) print("y_output: ", K.eval(y_output)) print("the loss is: ", K.eval(nn.softmax_cross_entropy_with_logits_v2(labels=y_target, logits=y_output)))
结果为:
y_target: [1. 2.] y_output: [1. 2.] the loss is: 1.939785
说明:y_output有两个输出值1和2,通过softmax函数转化后,我们可知1的对应softmax值为0.268941422,而2的对应softmax值为0.731058581;同时1对应的预测值为1,2对应的预测值为2。将上述值带入公式验证:
L = ∑ -(y * lna)
= -(1 * ln (e / (e + e2)) ) + -(2 * ln (e2 / (e + e2)))
= -(1* ln0.268941422) + -(2 * ln0.731058581)
= 1.939785
而在keras中,与此对应的是categorical_crossentropy,采用的算法和上述基本一致,只是需要把y_output按分类值做概率转换。
我们来举例说明:
import keras.backend as K from tensorflow.python.ops import nn from tensorflow.python.ops import math_ops from tensorflow.python.ops import clip_ops from tensorflow.python.framework import ops y_target = K.constant(value=[1, 2]) y_output = K.constant(value=[1, 2]) print("y_target: ", K.eval(y_target)) print("y_output: ", K.eval(y_output)) output = y_output / math_ops.reduce_sum(y_output, -1, True) print("output: ", K.eval(output)) epsilon_ = ops.convert_to_tensor(K.epsilon(), output.dtype.base_dtype) output = clip_ops.clip_by_value(output, epsilon_, 1. - epsilon_) print("output: ", K.eval(output)) print("the loss is: ", K.eval(-math_ops.reduce_sum(y_target * math_ops.log(output), -1)))
结果为:
y_target: [1. 2.] y_output: [1. 2.] output: [0.33333334 0.6666667 ] output: [0.33333334 0.6666667 ] the loss is: 1.9095424
其计算公式为:
L = ∑ -(y * lna)
= -(1 * ln 0.33333334 ) + -(2 * ln 0.66666667)
= 1.9095424
3. sparse + softmax + 交叉熵函数:
在tensorflows中体现为sparse_softmax_cross_entropy_with_logits,对应的官网地址为:https://www.tensorflow.org/api_docs/python/tf/nn/sparse_softmax_cross_entropy_with_logits
说明:可用于多元分类,如判断一张图片是否为猫;但如果图片里多个类别则是互斥的,比如一张图片里既包含狗,也包含猫,那我们也只能给唯一的标签,要么是狗,要么是猫。
加上sparse的区别在于:不加sparse给定的labels是允许有概率分布的,如[0.3, 0.4, 0.2, 0.05, 0.05],而加sparse,则如其名sparse稀疏矩阵,概率只允许要么存在,要么不存在,如[0, 0, 0, 1, 0]
我们常见的mnist数据集、cifar-10数据集等都是这种类型。
其数学公式为:L = -y * ln a,其中a为概率为1的输出值
依旧举例说明:
import keras.backend as K from tensorflow.python.ops import nn y_target = K.constant(value=1, dtype='int32') y_output = K.constant(value=[1, 2]) print("y_target: ", K.eval(y_target)) print("y_output: ", K.eval(y_output)) print("the loss is: ", K.eval(nn.sparse_softmax_cross_entropy_with_logits(labels=y_target, logits=y_output)))
结果为:
y_target: 1 y_output: [1. 2.] the loss is: 0.31326166
说明:本例中,输出值y_output为1和2,表示两种分类,而y_target的值为1,表示为分类的index,也就是对应了输出值2;更直白地说,输出值1的概率为0,输出值2的概率为1。
具体计算方式为:a = e2 / (e + e2) = 0.731058581
L = - ln a = 0.313261684
而在keras中,与此对应的为sparse_categorical_crossentropy,该函数会调用上述函数,最大的不同在于:1. 其参数y_output被设定为经过softmax之后的值;2. y_output还会被log处理下
举个例子:
import keras.backend as K y_target = K.constant(value=1, dtype='int32') y_output = K.constant(value=[0.2, 0.2, 0.6]) print("y_target: ", K.eval(y_target)) print("y_output: ", K.eval(y_output)) print("the loss is: ", K.eval(K.sparse_categorical_crossentropy(y_target, y_output)))
结果为:
y_target: 1 y_output: [0.2 0.2 0.6] the loss is: [1.609438]
说明:本例中y_output的值已经假设按照softmax处理后的值:0.2,0.2和0.6
其计算方式为:
a = eln0.2/(eln0.2 + eln0.2 + eln0,6) = 0.2/(0.2 + 0.2 +0.6) = 0.2
L = - ln 0.2 = 1.609438
以上即是交叉熵函数作为损失函数的使用理由,及其在tensorflow和keras中的实现说明。