基础环境准备:
系统:(VirtualBox) ubuntu-12.04.2-desktop-i386.iso
hadoop版本:hadoop-0.20.203.0rc1.tar.gz
jdk版本:jdk-6u26-linux-i586.bin
安装ssh服务
sudo apt-get install openssh-server
在Ubuntu下创建hadoop用户组和用户
$ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop hadoop
编辑/etc/sudoers文件,为hadoop用户添加权限
$ sudo vim /etc/sudoers
给hadoop用户赋予root相同的权限
hadoop ALL=(ALL:ALL) ALL
================================================================================
hadoop实战之安装与单机模式
--------------------------------------------------------------------------------
1. 下载最新的hadoop安装包,这里我使用的是hadoop-0.20.203.0rc1.tar.gz版本。
下载地址:http://archive.apache.org/dist/hadoop/core/hadoop-0.20.203.0/hadoop-0.20.203.0rc1.tar.gz
2. 解压压缩包到自己的目录,比如解压到/home/hadoop/data目录下(tar –zxvf hadoop-0.20.203.orc1.tar.gz),为了后面说明方便,这里把/home/hadoop/data/hadoop-0.20.203.0定义为$HADOOP_HOME;
3. 修改$HADOOP_HOME/conf/hadoop-env.sh文件,将JAVA_HOME指定到正确的jdk路径上(echo $JAVA_HOME查看);
4. 进入$HADOOP_HOME目录下执行以下命令,将会得到hadoop命令的帮助;
$ bin/hadoop
5. 进入$HADOOP_HOME目录下执行以下命令来测试安装是否成功
$ mkdir input
$ cp conf/*.xml input
$ bin/hadoop jar hadoop-examples-*.jar grep input output 'dfs[a-z.]+'
$ cat output/*
输出:
hadoop@ubuntu-V01:~/data/hadoop-0.20.203.0$ cat output/*
1 dfsadmin
经过上面的步骤,如果没有出现错误就算安装成功了。
================================================================================
hadoop实战之伪分布式模式
--------------------------------------------------------------------------------
Hadoop可以在单节点上以所谓的伪分布式模式运行,此时每一个Hadoop守护进程都作为一个独立的Java进程运行,这种运行方式的配置和操作如下:
关于hadoop的安装和测试可以参考...
这里仍假定${HADOOP_HOME}为位置是/home/hadoop/data/hadoop-0.20.203.0
1. 修改hadoop配置
1.1 编辑${HADOOP_HOME}/conf/core-site.xml文件,内容修改如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
1.2 编辑${HADOOP_HOME}/conf/hdfs-site.xml文件,内如修改如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
1.3 编辑${HADOOP_HOME}/conf/mapred-site.xml文件,内如修改如下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
2. 设置linux上ssh是用户可以自动登录
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3. 格式化一个新的分布式文件系统:
$ bin/hadoop namenode -format
4. 执行hadoop
4.1 启动hadoop后台daemon
$ bin/start-all.sh
启动后可以通过网页方式查看NameNode和JobTracker状态
NameNode - http://localhost:50070/
JobTracker - http://localhost:50030/
4.2 复制文件到分布式文件系统上
$ bin/hadoop fs -put conf input
4.3 运行测试
$ bin/hadoop jar hadoop-examples-*.jar grep input output 'dfs[a-z.]+'
4.4 获取测试程序的执行结果
$ bin/hadoop fs -cat output/*
输出:
hadoop@ubuntu-V01:~/data/hadoop-0.20.203.0$ bin/hadoop fs -cat output/*
2 dfs.replication
1 dfs.server.namenode.
1 dfsadmin
4.5 停止hadoop后台daemon
$ bin/stop-all.sh
================================================================================
hadoop实战之分布式模式
--------------------------------------------------------------------------------
1. 首先为hadoop的集群准备几台机器,这里机器名如下:
ubuntu-V01(master)
ubuntu-V02(slave1)
ubuntu-V03(slave2)
2. 修改每个机器的/etc/hosts文件,确保每个机器都可以通过机器名互相访问;
3. 在上面每个机器上的相同位置分别安装hadoop,这里安装的都是hadoop-0.20.203.0rc1.tar.gz包,并且假定安装路径都是/home/hadoop/data/hadoop-0.20.203.0;
4. 修改所有机器上的${HADOOP_HOME}/conf/hadoop-env.sh文件,将JAVA_HOME指定到正确的jdk路径上;
5. 修改master机器上的${HADOOP_HOME}/conf/slaves文件,修改后文件内容如下:
ubuntu-V02
ubuntu-V03
6. 修改和部署配置文件
6.1 编辑${HADOOP_HOME}/conf/core-site.xml文件,内容修改如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://ubuntu-V01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoop-0.20.203.0/hadoop-${user.name}</value>
</property>
</configuration>
6.2 编辑${HADOOP_HOME}/conf/hdfs-site.xml文件,内如修改如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
6.3 编辑${HADOOP_HOME}/conf/mapred-site.xml文件,内如修改如下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>ubuntu-V01:9001</value>
</property>
</configuration>
6.4 将以上三个配置文件分别部署在每个节点上;
7. 格式化一个新的分布式文件系统:
$ bin/hadoop namenode -format
8. 执行hadoop
8.1 启动hadoop后台daemon
$ bin/start-all.sh
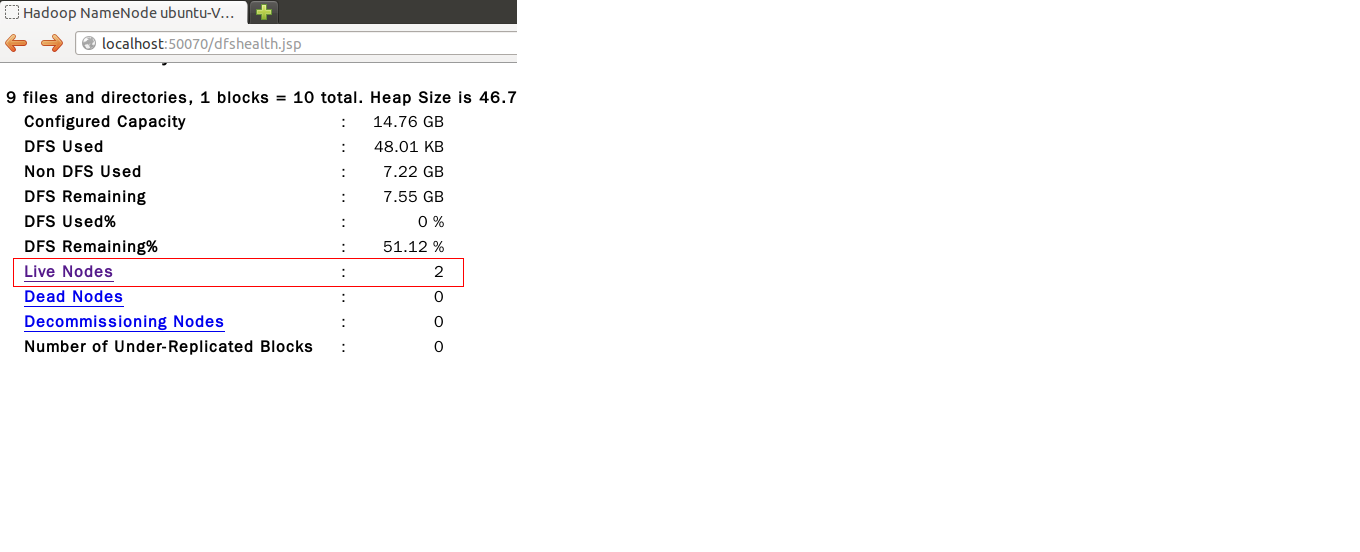
启动后可以通过以下网页方式查看NameNode和JobTracker状态,此时可以从NameNode状态网页上看到"Live Nodes"的数量变成了两个,此时表示已经部署成功
NameNode - http://localhost:50070/
JobTracker - http://localhost:50030/

8.2 运行测试
在hadoop默认提供了一些可以运行的测试工具在安装包目录下,下面就用这些测试程序来验证分布式模式是否成功
8.2.1 测试一
运行下面的命令将从本地复制一个文件到hdfs文件系统的/test/目录下
$ bin/hadoop fs -copyFromLocal /home/hadoop/data/hadoop-0.20.203.0/hadoop-examples-0.20.203.0.jar /test/hadoop-examples-0.20.203.0.jar
运行下面的命令将显示hdfs文件系统上/test/目录下的文件
$ bin/hadoop fs -ls /test/
输出结果如下:
Found 1 items
-rw-r--r-- 1 hadoop supergroup 142469 2014-01-25 16:22 /test/hadoop-examples-0.20.203.0.jar
运行完上面的命令以后,可以通过http://localhost:50070/来查看hdfs上的文件,此时可以看到slave节点上已经有刚才命令上传的文件存在了。
8.2.2 测试二
运行下面的命令
$ bin/hadoop jar hadoop-examples-0.20.203.0.jar sleep 300
然后访问http://localhost:50030/,可以看到会有job在cluster里运行
8.2.3 测试三
首先准备数据,下面两个命令是在hdfs上创建一个/test/input目录,然后从本地复制一下文件到此目录下
$ bin/hadoop fs -mkdir /test/input
$ bin/hadoop fs -copyFromLocal /home/hadoop/data/hadoop-0.20.203.0/conf/*.xml /test/input
运行测试来查找一些字符串
$ bin/hadoop jar hadoop-examples-*.jar grep /test/input /test/output 'dfs[a-z.]+'
查看测试结果
$ bin/hadoop fs -ls /test/output/
$ bin/hadoop fs -cat /test/output/part-00000
8.3 停止hadoop后台daemon
$ bin/stop-all.sh
================================================================================
hadoop实战之动态添加节点
--------------------------------------------------------------------------------
假定已经有了一个hadoop cluster环境,并且已经有了两个slave节点ubuntu-V02和ubuntu-V03,这里需要动态添加一个新的节点ubuntu-V04.
1. 修改${HADOOP_HOME}/conf/slaves文件,在其中添加一个新的slave节点,比如
ubuntu-V02
ubuntu-V03
ubuntu-V04(新节点)
2. 登录到新添加的slave节点上,进入${HADOOP_HOME}目录并运行以下命令:
$ bin/hadoop-daemon.sh start datanode
$ bin/hadoop-daemon.sh start tasktracker
3. 验证添加是否成功
3.1 访问http://localhost:50070/可以看到"Live Nodes"的数量就从2变成了3;
3.2 也可以通过以下命令行来验证是否成功
$ bin/hadoop dfsadmin -report
================================================================================
备注:
进行分布式环境配置时,注意 /etc/hosts中ip与主机名的映射
如ubuntu-01机器上:
hadoop@ubuntu-V01:~$ cat /etc/hosts
127.0.0.1 localhost
192.168.1.109 ubuntu-V01
192.168.1.110 ubuntu-V02
192.168.1.111 ubuntu-V03
192.168.1.112 ubuntu-V04
参考:
http://hadoop.apache.org/docs/r0.19.1/cn/index.html
http://hadoop.apache.org/docs/r1.0.4/cn/index.html
http://blog.csdn.net/greatelite/article/details/17690239 Hadoop 2.2.0 分布式集群搭建
http://www.infoq.com/cn/articles/hadoop-intro 分布式计算开源框架Hadoop入门实践(一)分布式计算开源框架Hadoop介绍
http://www.infoq.com/cn/articles/hadoop-config-tip 分布式计算开源框架Hadoop入门实践(二)Hadoop中的集群配置和使用技巧
http://www.infoq.com/cn/articles/hadoop-process-develop 分布式计算开源框架Hadoop入门实践(三)Hadoop基本流程与应用开发