一 简介
wxpy基于itchat,使用了 Web 微信的通讯协议,,通过大量接口优化提升了模块的易用性,并进行丰富的功能扩展。实现了微信登录、收发消息、搜索好友、数据统计等功能。
总而言之,可用来实现各种微信个人号的自动化操作。
安装:wxpy 支持 Python 3.4-3.6,以及 2.7 版本
pip3 install -U wxpy
二 登录微信
1、扫码登录微信
from wxpy import * bot = Bot()
2、cache_path=True
运行上面的程序,会弹出二维码,用手机微信扫一扫即可实现登录。
但上面的程序有一个缺点,每次运行都要扫二维码。不过wxpy非常贴心地提供了缓存的选项,用于将登录信息保存下来,就不用每次都扫二维码,如下
bot = Bot(cache_path=True) # 必须先登录过一次以后才可以使用缓存
三 微信好友男女比例

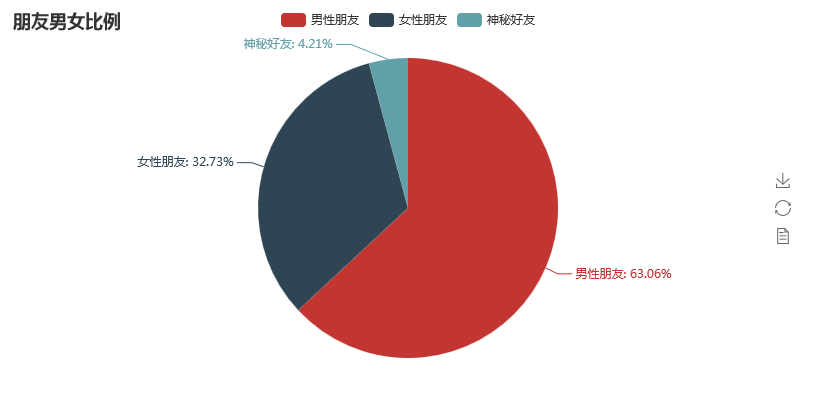
from wxpy import * from pyecharts import Pie import webbrowser bot = Bot(cache_path=True) # 添加缓存,避免每次都重复繁琐的步骤 friends = bot.friends() # 拿到所有的好友数据 attr = ['男性朋友', '女性朋友', '神秘好友'] # 事先按性别对好友数据进行分类 value = [0, 0, 0] # 对应上面的好友分别计数 for friend in friends: # for循环取出一个个好友信息判断性别进行统计分类 if friend.sex == 1: # 男性朋友默认为1 value[0] += 1 elif friend.sex == 2: # 女性朋友默认为2 value[1] += 1 else: value[2] += 1 # 为填写性别信息的全部记为神秘好友 pie = Pie('朋友男女比例') # 初始化饼状图对象 pie.add('纪伯元的微信好友性别比例', attr, value, is_label_show=True) # 填充数据,is_label_show悬浮显示比例 pie.render('data.html') # 生成名为data的html文件 webbrowser.open('data.html') # 自动调用浏览器打开生成的html文件展示
四 微信好友地域分布
显示中国地图,需要装中国地图模块:
全球国家地图: echarts-countries-pypkg (1.9MB): 世界地图和 213 个国家,包括中国地图
中国省级地图: echarts-china-provinces-pypkg (730KB):23 个省,5 个自治区
中国市级地图: echarts-china-cities-pypkg (3.8MB):370 个中国城市
中国县区级地图: echarts-china-counties-pypkg (4.1MB):2882 个中国县·区
中国区域地图: echarts-china-misc-pypkg (148KB):11 个中国区域地图,比如华南、华北。
特别注明,中国地图在 echarts-countries-pypkg 里。需要这些地图的朋友,可以装 pip 命令行:
$ pip3 install echarts-countries-pypkg
$ pip3 install echarts-china-provinces-pypkg
$ pip3 install echarts-china-cities-pypkg
$ pip3 install echarts-china-counties-pypkg
$ pip3 install echarts-china-misc-pypkg
from wxpy import * from pyecharts import Map import webbrowser bot = Bot(cache_path=True) friends = bot.friends() area_dic = {} # 由于需要地域以及地域对应的计数,所以字典符合该要求 for friend in friends: if friend.province not in area_dic: area_dic[friend.province] = 1 else: area_dic[friend.province] += 1 attr = area_dic.keys() value = area_dic.values() map = Map('微信好友们的地域分布', width=600, height=400) map.add( '好友地域分布', attr, value, maptype='china', is_visualmap=True # 色彩对比鲜明 ) map.render('area.html') webbrowser.open('area.html')
五 微信好友数据分析之词云

#安装软件 pip3 install jieba pip3 install pandas pip3 install numpy pip3 install scipy pip3 install wordcloud
from wxpy import * import re import jieba import pandas as pd import numpy bot=Bot(cache_path=True) friends=bot.friends() # 统计签名 with open('signatures.txt','w',encoding='utf-8') as f: for friend in friends: # 对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除 pattern=re.compile(r'[一-龥]+') filterdata=re.findall(pattern,friend.signature) f.write(''.join(filterdata)) #过滤停止词 with open('signatures.txt','r',encoding='utf-8') as f: data=f.read() segment=jieba.lcut(data) words_df=pd.DataFrame({'segment':segment}) stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep=" ", names=['stopword'], encoding='utf-8') words_df = words_df[~words_df.segment.isin(stopwords.stopword)] #使用numpy进行词频统计 words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size}) words_stat = words_stat.reset_index().sort_values(by=["计数"],ascending=False) # print(words_stat) #词频可视化:词云,基于wordcloud库,当然pyecharts也可以实现 from scipy.misc import imread from wordcloud import WordCloud, ImageColorGenerator import matplotlib.pyplot as plt # 设置词云属性 # color_mask = imread('background.jfif') # color_mask = imread('bg.jpg') color_mask = imread('bg1.jpeg') wordcloud = WordCloud( # font_path="simhei.ttf", # mac上没有该字体 font_path="/System/Library/Assets/com_apple_MobileAsset_Font3/6d903871680879cf5606a3d2bcbef058e56b20d4.asset/AssetData/华文仿宋.ttf", # 设置字体可以显示中文 background_color="white", # 背景颜色 max_words=100, # 词云显示的最大词数 mask=color_mask, # 设置背景图片 max_font_size=100, # 字体最大值 random_state=42, width=1000, height=860, margin=2,# 设置图片默认的大小,但是如果使用背景图片的话, # 那么保存的图片大小将会按照其大小保存,margin为词语边缘距离 ) # 生成词云, 可以用generate输入全部文本,也可以我们计算好词频后使用generate_from_frequencies函数 word_frequence = {x[0]:x[1]for x in words_stat.head(100).values} print(word_frequence) word_frequence_dict = {} for key in word_frequence: word_frequence_dict[key] = word_frequence[key] print(word_frequence_dict) wordcloud.generate_from_frequencies(word_frequence_dict) # 从背景图片生成颜色值 image_colors = ImageColorGenerator(color_mask) # 重新上色 wordcloud.recolor(color_func=image_colors) # 保存图片 wordcloud.to_file('output.png') plt.imshow(wordcloud) plt.axis("off") plt.show()
from wxpy import * import re import jieba import pandas as pd import numpy bot=Bot(cache_path=True) friends=bot.friends() # 统计签名 with open('signatures.txt','w',encoding='utf-8') as f: for friend in friends: # 对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除 pattern=re.compile(r'[一-龥]+') filterdata=re.findall(pattern,friend.signature) f.write(''.join(filterdata)) #过滤停止词 with open('signatures.txt','r',encoding='utf-8') as f: data=f.read() segment=jieba.lcut(data) words_df=pd.DataFrame({'segment':segment}) stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep=" ", names=['stopword'], encoding='utf-8') words_df = words_df[~words_df.segment.isin(stopwords.stopword)] #使用numpy进行词频统计 words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size}) words_stat = words_stat.reset_index().sort_values(by=["计数"],ascending=False) print(words_stat) #可是化词云 from pyecharts import WordCloud word_frequence = {x[0]:x[1]for x in words_stat.head(100).values} name = word_frequence.keys() value = word_frequence.values() wordcloud = WordCloud(width=1300, height=620) wordcloud.add("", name, value, word_size_range=[20, 100]) wordcloud.render('cy.html')

 补充:stopword
补充:stopword
六 聊天机器人
1、为微信传输助手传送消息
这里的file_helper就是微信的文件传输助手,我们给文件传输助手发送一条消息,可以在手机端的文件传输助手中收到括号内的消息
from wxpy import * bot = Bot(cache_path=True) bot.file_helper.send('元少说你好啊')
2、收发消息@bot.register()
from wxpy import * bot=Bot(cache_path=True) @bot.register() def recv_send_msg(recv_msg): print('收到的消息:',recv_msg.text) # recv_msg.text取得文本 return '自动回复:%s' %recv_msg.text # 进入Python命令行,让程序保持运行 embed()
3、自动给老婆回复信息
当你在网吧吃着鸡,操作骚出天际时,你老婆打电话让你回家吃饭,此时你怎么办。。。
from wxpy import * bot = Bot(cache_path=True) girl_friend = bot.search('你想要针对回复的好友备注名')[0] print(girl_friend) @bot.register() # 括号内可以针对单独某个用户进行下列操作如:chats=girl_friend def recv_send_msg(recv_msg): print('收到消息:', recv_msg.text) # 不是针对的用户,显示消息内容不做回复 if recv_msg.sender == girl_friend: # 如果是目标用户则走下面的逻辑 recv_msg.forward(bot.file_helper, prefix='老婆留言:') # 在文件助手里面留一份,方便吃完鸡查看 return '大宝贝儿,么么哒哦' # 给老婆回复的内容 embed()
4、从微信群中定位好友
老板的信息一定要及时回复
bot=Bot(cache_path=True) company_group=bot.groups().search('群名称')[0] boss=company_group.search('老板的微信名称')[0] @bot.register(chats=company_group) #接收从指定群发来的消息,发送者即recv_msg.sender为组 def recv_send_msg(recv_msg): print('收到的消息:',recv_msg.text) if recv_msg.member == boss: recv_msg.forward(bot.file_helper,prefix='老板发言: ') return '老板说的好有道理,深受启发' embed()
5、聊天机器人
给所有人自动回复
import json import requests from wxpy import * bot = Bot() def auto_reply(text): url = "http://www.tuling123.com/openapi/api" api_key = "9df516a74fc443769b233b01e8536a42" payload = { "key": api_key, "info": text, } r = requests.post(url, data=json.dumps(payload)) result = json.loads(r.content) return "[元少微信测试,请忽略] " + result["text"] @bot.register() def forward_message(msg): return auto_reply(msg.text) embed()
给指定的群回复
import json import requests from wxpy import * bot = Bot(cache_path=True) group = bot.groups().search('二十六班-奥斯卡 篮球队')[0] def auto_reply(text): url = "http://www.tuling123.com/openapi/api" api_key = "9df516a74fc443769b233b01e8536a42" payload = { "key": api_key, "info": text } r = requests.post(url, data=json.dumps(payload)) result = json.loads(r.content) return "[元少微信测试,请忽略]" + result["text"] @bot.register(group) def forward_message(msg): return auto_reply(msg.text) embed()
给指定的人回复
import json import requests from wxpy import * bot = Bot(cache_path=True) girl_friend = bot.search('XBB')[0] def auto_reply(text): url = "http://www.tuling123.com/openapi/api" api_key = "9df516a74fc443769b233b01e8536a42" payload = { "key": api_key, "info": text } r = requests.post(url, data=json.dumps(payload)) result = json.loads(r.content) return "[元少微信测试,请忽略]" + result["text"] @bot.register() def forward_message(msg): if msg.sender == girl_friend: return auto_reply(msg.text) embed()