synchronized和lock的区别:
| 类别 | synchronized | lock |
| 存在层次 | java的关键字,在jvm层面上 | 是一个类 |
| 锁的释放 |
1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程释放锁 |
在finally中必须释放锁,不然容易造成线程死锁 |
| 锁的获取 |
假设A线程获得锁,B线程等待, 如果A线程阻塞,B线程会一直等待 |
分情况而定,lock有多个锁获取的方法,可以尝试获得锁, 线程可以不用功一直等待 |
| 锁状态 | 无法判断 | 可以判断 |
| 锁类型 | 可以重入,不可以中断,非公平 | 可重入 可以判断 可公平 |
| 性能 | 少量同步 | 大量同步 |
synchronized使用方式及原理:
作用在方法上:
public synchronized void test(){}//作用在方法上JVM采用ACC_SYNCHRONIZED标记符来实现同步的;
作用在代码块上:
synchronized (SynchronizedTest.class){}//作用在同步代码块上JVM是采用monitorenter和monitorexit两个指令来实现同步的;
java对象头:
synchronized用的锁是存在java对象头里的,java对象头一般占有两个机器码(在32位虚拟机中,1个机器码等于4字节,也就是32bit),那么什么是java对象头呢?HotSpot虚拟机的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)。
- Klass Pointer是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例;
- Mark Word 用于存储对象自身的运行时数据,它是实现轻量级锁和偏向锁的关键(例如hashCode、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等)
Mark Word会随着程序的运行发生变化,变化状态如下:
| 锁状态 | 25bit | 4bit | 1bit | 2bit | |
| 23bit | 2bit | 是否是偏向锁 | 锁标志位 | ||
| 无锁状态 | 对象hashCode、对象分代年龄 | 01 | |||
| 轻量级锁 | 指向锁记录的指针 | 00 | |||
| 重量级锁 | 指向重量级锁的指针 | 10 | |||
| GC标记 | 空,不需要记录信息 | 11 | |||
| 偏向锁 | 线程ID | Epoch | 对象分代年龄 | 1 | 01 |
Monitor:
什么是monitor?我们可以把它理解为一个同步工具,也可以描述为一种同步机制,它通常被描述为一个对象。与一切皆对象一样,所有的java对象是天生的monitor,每一个java对象都有称为monitor的潜质,
因为在java的设计中,每一个java对象自打娘胎里出来就带了一把看不见的锁,它叫做内部锁或者monitor锁。
monitor是线程私有的数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。每一个被锁住的对象都会和一个monitor关联(对象头的Mark Word中的LockWord指向monitor的起始地址),
同时monitor中有一个Owner字段存放拥有该锁的线程的唯一标识,标识该锁被这个线程占用,其结构如下:
| Owner |
| EntryQ |
| RcThis |
| Nest |
| HashCode |
| Candidate |
- Owner:初始值为null表示当前没有任何线程拥有该monitor record,当线程成功拥有该锁后保存线程唯一标识,当锁被释放时又设置为null;
- EntryQ:关联一个系统互斥锁,阻塞所有试图锁住monitor record 失败的线程;
- RcThis:表示blocked或waiting在该monitor record上的所有线程的个数;
- Nest:用来实现重入锁的计数;
- HashCode:保存从对象头拷贝过来的HashCode值(可能还包含GC age);
- Candidate:用来避免不必要的阻塞或等待线程唤醒,因为每一次只有一个线程能够成功拥有锁,如果每次前一个释放锁的线程唤醒所有正在阻塞或等待的线程,会引起不必要的上下文切换(从阻塞到就绪然后因为竞争锁失败又被阻塞)从而导致性能严重下降。Candidate只有两种可能的值:0表示没有需要唤醒的线程;1表示要唤醒一个继任线程来竞争锁。
我们都知道synchronized是重量级锁,效率不怎么好,同时这个观念也一直存在我们脑海里,不过在jdk1.6中对synchronized的实现进行了各种优化,使得它显得不是那么重了,那么JVM采用了哪些优化手段呢?
锁优化:
jdk1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。(注意!锁只可以升级不可以降级,这种策略是为了提高获得锁和释放锁的效率)
自旋锁
线程的阻塞和唤醒需要CPU从用户态转为核心态,频繁的阻塞和唤醒对CPU来说是一件负担很重的工作,势必会给系统的并发性能带来很大的压力。同时我们发现在许多应用上面,对象锁的锁状态只会持续很短一段时间,为了这一段很短的时间频繁的阻塞和唤醒线程是非常不值得的。所以引入自旋锁。何谓自旋锁?
所谓自旋锁,就是让该线程等待一段时间,不会被立即挂起,看持有锁的线程是否会很快释放。怎么等待呢?执行一段无意义的循环即可(自选)。自旋等待不能替代阻塞,虽然它可以避免线程切换带来的开销,但是它占用了处理器的时间。如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好了,反之,自旋的线程就会白白消耗掉处理的资源,它不会做任何有意义的工作,典型的占着茅坑不拉屎,这样反而会带来性能上的而浪费。所以说,自旋等待的时间(自旋次数)必须要有一个限制,如果自旋超过了定义的时间仍然没有获取到锁,则应该被挂起。
自旋锁在jdk 1.4.2中引入,默认关闭,但是可以使用-XX:+UseSpinning开启,在jdk1.6中默认开启。同时默认的次数为10次,可以通过参数-XX:PreBlockSpin来调整;如果通过参数-XX:preBlockSpin来调整自旋锁的自旋次数,会带来诸多不便。假如我将参数调整为10,但是系统很多线程都是等你刚刚退出的时候就释放了锁(假如你多自旋一两次就可以获取锁),你是不是很尴尬,于是jdk1.6引入自适应的自旋锁,让虚拟机会变得越来越聪明。
适应自旋锁:
jdk1.6引入了更加聪明的自旋锁,即自适应的自旋锁。所谓自适应就意味着自旋的次数不再是固定的,他是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的。它怎么做的呢?线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么这次自旋也很有可能会再次成功,那么他就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋成功的,那么在以后要获取这个锁的时候自旋的次数会减少甚至省略掉自旋的过程,以免浪费处理器资源。
有了自适应自旋锁,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测会越来越准确,虚拟机会变得越来越聪明。
锁消除:
为了保证数据的完整性,我们在进行操作时需要对这部分操作进行同步控制,但是在有些情况下,JVM检测到不可能存在共享数据竞争,这是JVM会对这些同步锁进行所消除,锁消除的依据是逃逸分析的数据支持。
如果不存在竞争,为什么还需要加锁呢?所以锁消除可以节省毫无意义的请求锁的时间。变量是否逃逸,对于虚拟机来说需要使用功能数据流分析来确定,但是对于开发者来说这还不清楚么?有时候我们虽然没有显示使用锁,但是我们在使用一些jdk的内置api时,如StringBuffer、Vector、HashTable等,这个时候回存在隐形的加锁操作。比如StringBuffer的append()方法,Vector的add()方法:
public void vectorTest(){ Vector<String> vector = new Vector<String>(); for(int i = 0 ; i < 10 ; i++){ vector.add(i + ""); } System.out.println(vector); }
在运行这段代码时,JVM可以明显检测到变量vector没有逃逸出方法vectorTest方法之外,所以JVM可以大胆地将vector内部的加锁操作消除。
锁粗化:
我们知道在使用同步锁的时候,需要让同步块的作用范围尽可能小,仅在共享数据的实际作用于中才进行同步,这样做的目的是为了使需要同步的操作数量尽可能缩小,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。但是如果一系列的连续加锁解锁操作,可能导致不必要的性能损耗,索引引入锁粗化的概念。
锁粗化:就是将多个连续的加锁、解锁的操作连接在一起,扩展成一个范围更大的锁。
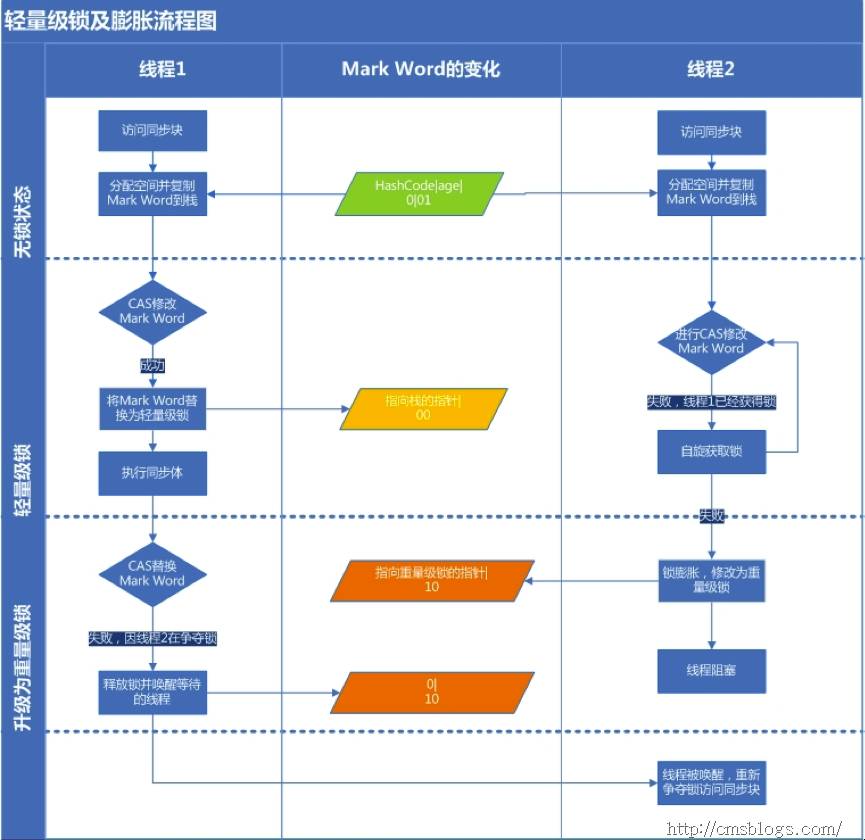
轻量级锁:
引入轻量级锁的主要目的是在多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。当关闭偏向锁功能或者多个线程竞争偏向锁导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁,
下图是轻量级锁的获取和释放过程:
偏向锁:
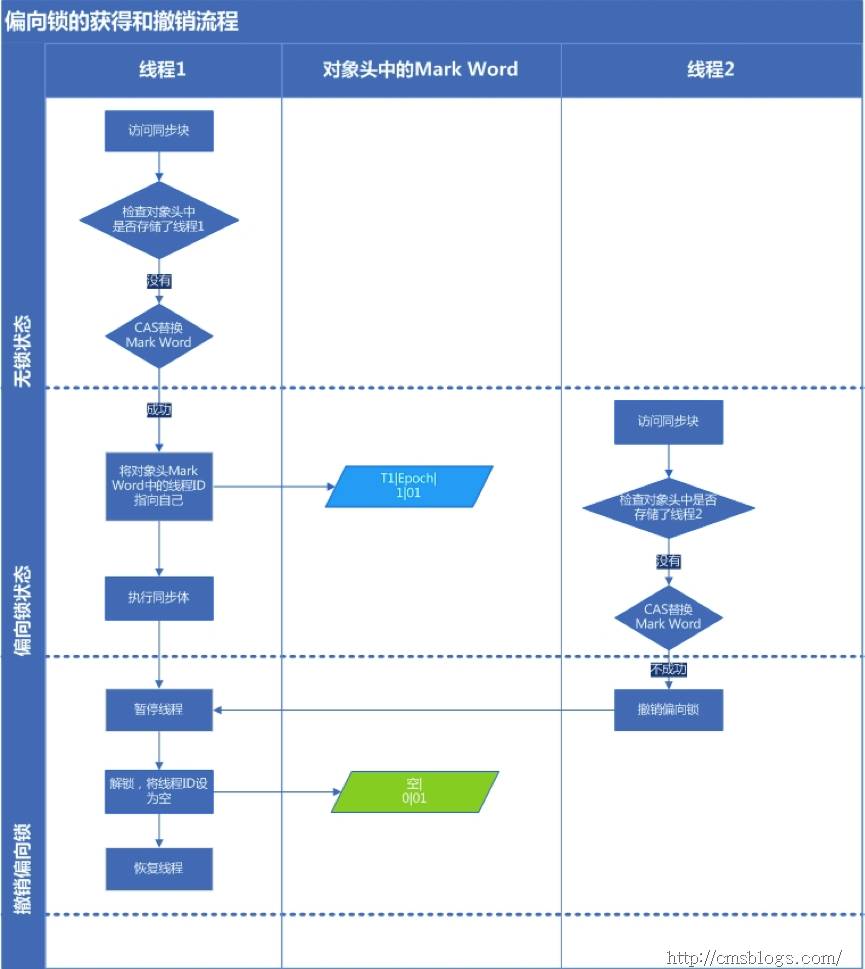
引入偏向锁主要目的是:为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径。
下图是偏向锁的获取和释放流程:
重量级锁:
重量级锁通过对象内部的监视器(monitor)实现的,其中monitor的本质是依赖于底层操作系统的Mutex Lock实现,操作系统实现线程之间的切换需要从用户态到内核态的切换,切换成本非常高。