在之前学习了Master-Slave、Sentinel模式,但是在某些情况下还是无法满足系统对QPS等要求,这时候就需要Cluster,Redis3.0支持了cluster
一、为什么使用Cluster
1、并发量
官方说明Redis支持10W条命令/秒,这已经很牛逼了,但是有些业务场景需要100W条命令/秒,当然这可能是一线互联网公司的场景
2、数据量
Master-Slave模式下内存、网络流量(网卡)无法满足要求
二、数据分区
我们使用cluster,有一个很重要的原因就是数据量过大,这种时候就要考虑数据分区了
1、顺序分布:数据倾斜
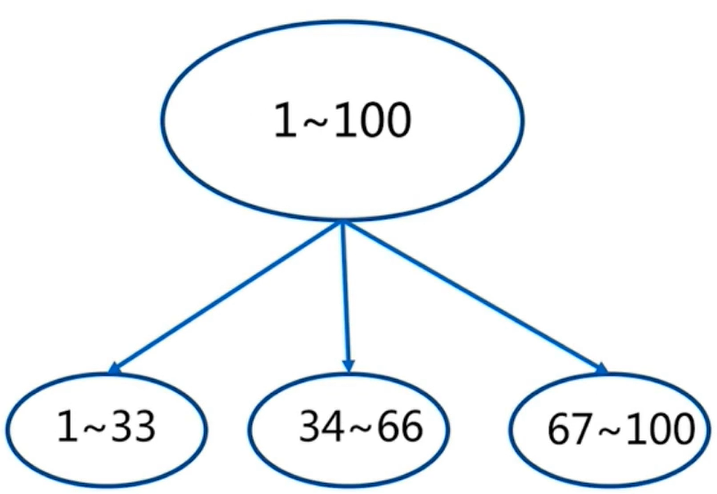
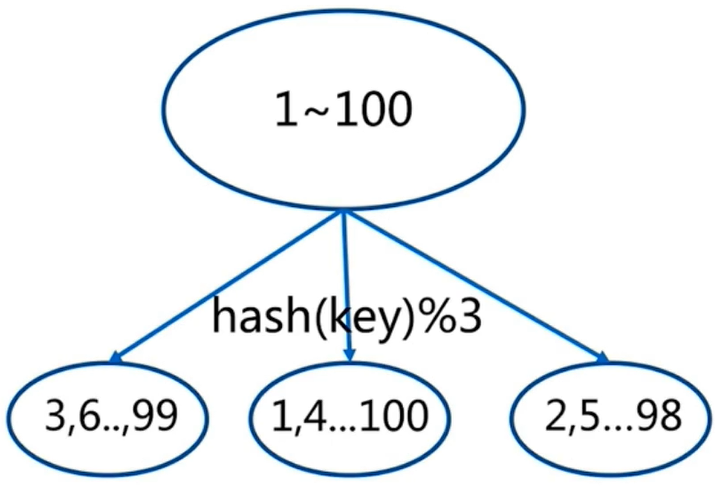
2、hash分布:通过hash函数进行分区,hash分布有很多实现方式,常见的有一下两种
1).节点取余:通过hash和取余,比较简单,当进行节点扩容/伸缩的时候,数据迁移率80%,最好是进行翻倍扩容,数据迁移率50%

2).一致性hash
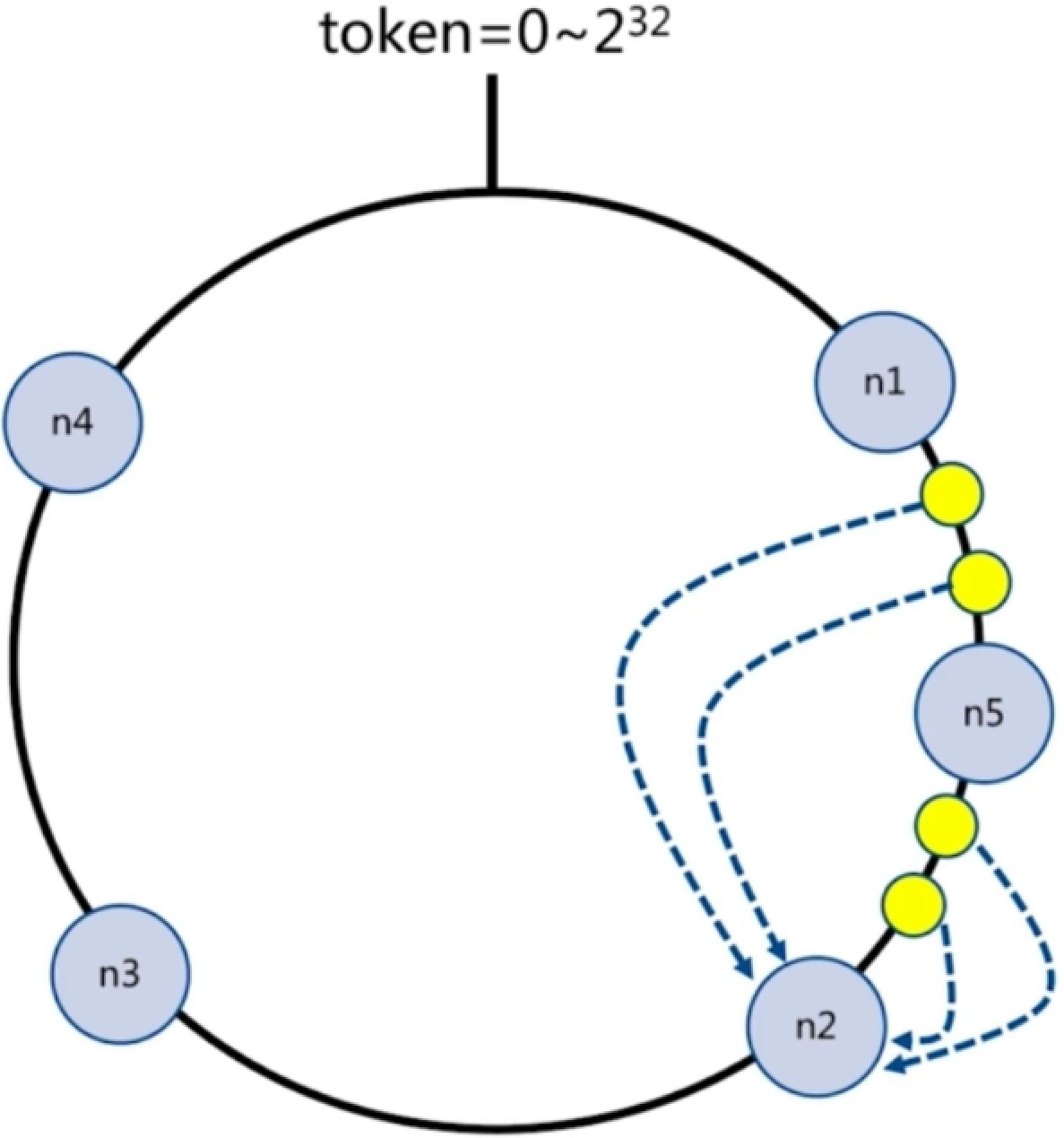
将数据看做一个token环,范围0~2^32,对key进行hash计算,例如落到n1-n2之间,就会顺时针找离自己最近的节点,最终落到n2节点
2.1).扩容:
新增节点n5,只会影响hash落到n1-n5之间的数据,之前这些数据最终落到n2节点,但是现在找到n5节点,是无法找到的,还是存在数据迁移,
如果现在有1000个节点,新增节点时,影响的范围很小1/1000,所以一致性hash适合节点比较多的情况
2.2).翻倍扩容:
保证最小数据迁移和负载均衡(新增n5节点,如果数据分布不均衡,主要在n1--n2之间,还是有很大问题)
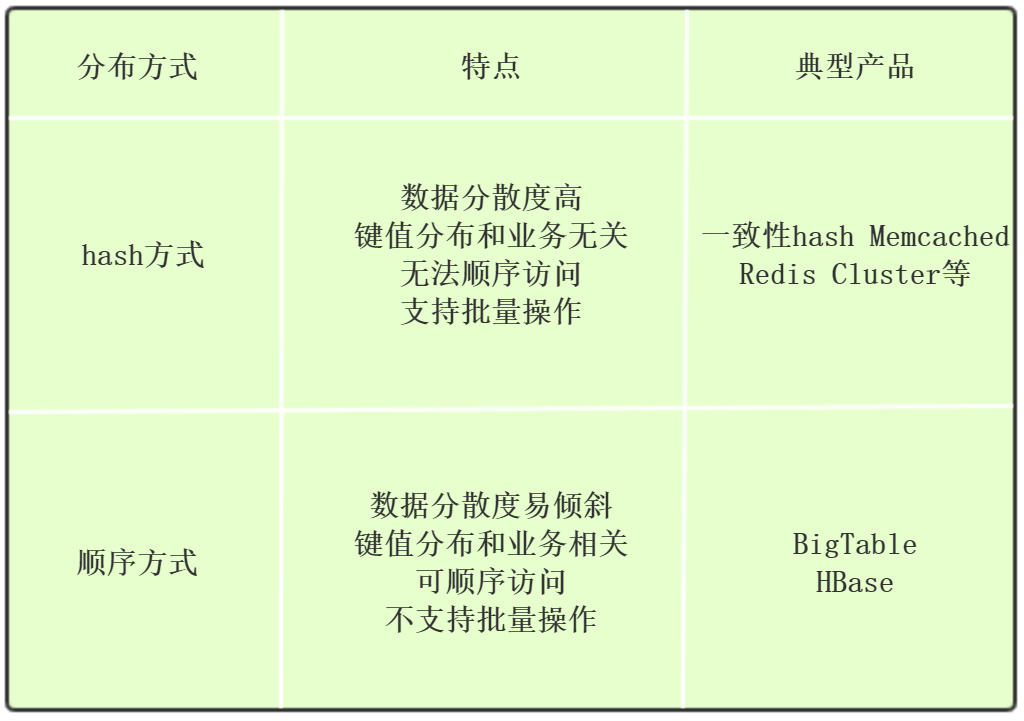
顺序分步和hash分布对比:
3、虚拟槽分区:Redis采用的分区方式
1、预设虚拟槽:每个槽映射一个数据子集,一般比节点数大
2、hash函数:例如CRC16
3、Server管理节点、槽和数据之间的关系:例如Redis Cluster
虚拟槽分配:一共有16383个槽
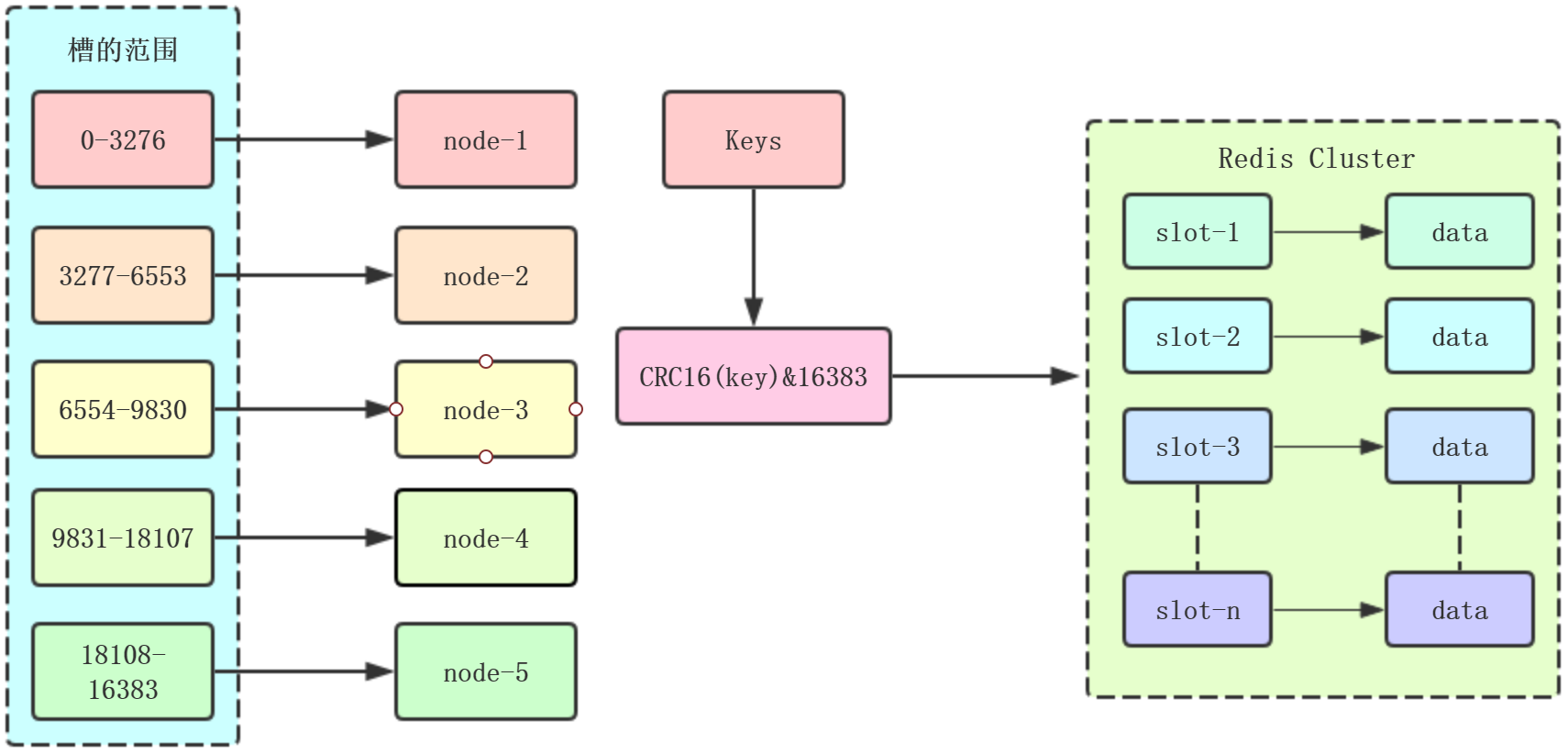
流程:
首先将key进行hash,然后和16383取余,发送给Redis Cluster任意一个node,每个node都会记录自己负责的slot,如果命中,保存在自己的
slot里面,如果没有命中,会返回应该是哪个node,直接去找就行了,因为node之间通过meet操作,自动进行感知,然后相互之间交换数据信息
三、Redis Cluster安装架构
两种安装方式:
1、原生命令安装
2、官方工具安装
为了理解结构,可以尝试原生命令安装
1、原生命令安装
启动六个node,默认三主三从,6379/6380/6381/6382/6383/6384
1、设置:
cluster-enabled:yes 就是使用集群模式启动
cluster-node-timeout 15000 节点超时时间15s
cluster-config-file nodes-${port}.conf 开启每个节点的配置
cluster-require-full-coverage no 要求所有节点都可用才对外提供Redis服务
启动:
redis-server redis-6379.conf
redis-server redis-6380.conf
redis-server redis-6381.conf
redis-server redis-6382.conf
redis-server redis-6383.conf
redis-server redis-6384.conf
2、meet操作:
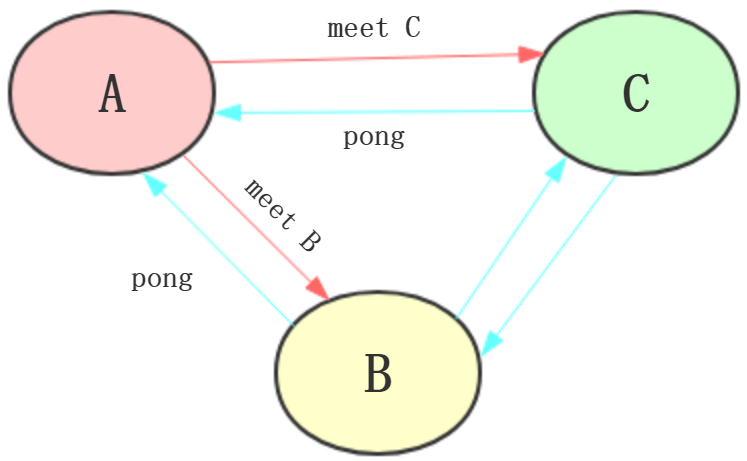
流程:
1、A对B进行meet操作,B返回pong
2、B对C进行meet操作,C返回pong
3、节点通过内部协议,自动进行节点的感知(),C也能了解到B,他们也是通的,都可以交换消息
命令:cluster meet ip port
例如:
redis-cli -h 127.0.0.1 -p 6379 meet 127.0.0.1 6380
redis-cli -h 127.0.0.1 -p 6379 meet 127.0.0.1 6381
redis-cli -h 127.0.0.1 -p 6379 meet 127.0.0.1 6382
redis-cli -h 127.0.0.1 -p 6379 meet 127.0.0.1 6383
redis-cli -h 127.0.0.1 -p 6379 meet 127.0.0.1 6384
3、指派槽
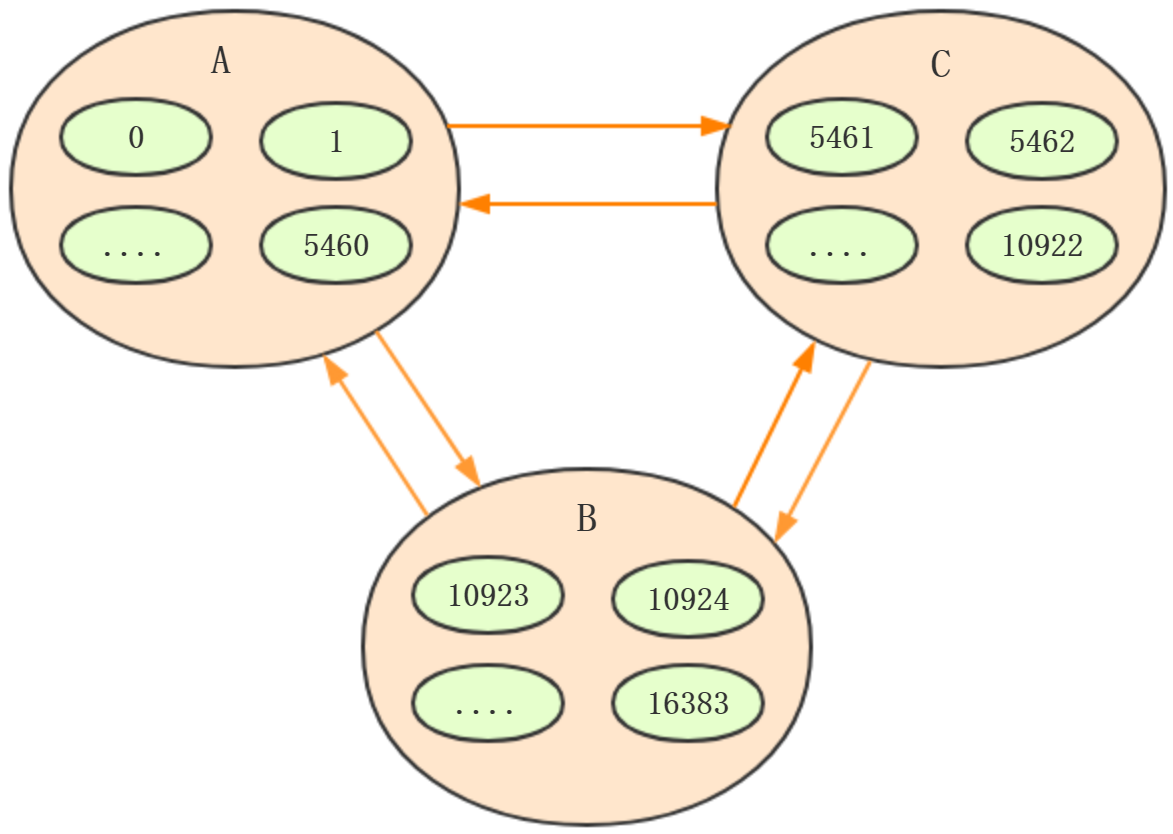
命令:cluster addslots slot[slot...]
例如:
redis-cli -h 127.0.0.1 -p 6379 cluster addslots {0...5461}
redis-cli -h 127.0.0.1 -p 6380 cluster addslots {5461...10922}
redis-cli -h 127.0.0.1 -p 6381 cluster addslots {10922...16383}
4、设置主从
命令:cluster replicate node-id
例如:
redis-cli -h 127.0.0.1 -p 6382 cluster replicate ${node-id-6379}
redis-cli -h 127.0.0.1 -p 6383 cluster replicate ${node-id-6380}
redis-cli -h 127.0.0.1 -p 6384 cluster replicate ${node-id-6381}
到此,集群已经建立完毕
5、特性
1).主从复制
2).高可用
3).分片:多个主节点进行读写
未完待续。。。