HTTP 应用程序有时在发送之前需要对内容进行编码。例如,在把很大的 HTML 文档发送给通过慢速连接上来的客户端之前,服务器可能就会对它进行压缩,这样有助于减少传输实体的时间。
内容编码过程
内容编码的过程如下所述。
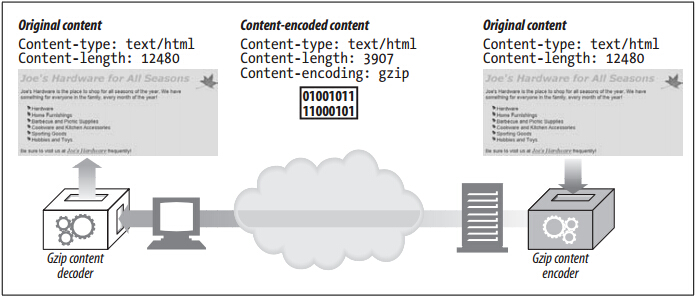
- 网站服务器生成原始响应报文,其中有原始的 Content-Type 和 Content-Length 首部。
- 内容编码服务器(也可能就是原始的服务器或下行的代理)创建编码后的报文,编码后的报文有同样的 Content-Type 但 Content-Length 可能不同(比如主体被压缩了)。内容编码服务器在编码后的报文中增加 Content-Encoding 首部,这样接收的应用程序就可以进行解码了。
- 接收程序得到编码的报文,进行解码,获得原始报文。
内容编码类型
HTTP 定义了一些标准的内容编码类型,并允许用扩展编码的形式增添更多的编码。由互联网号码分配机构(IANA)对各种编码进行标准化,它给每个内容编码算法分配了唯一的代号。Content-Encoding 首部就用这些标准化的代号来说明编码时使用的算法。
下表列出了一些常用的内容编码代号:
| 描述 | |
| gzip | 表明实体采用 GNU zip 编码 |
| compress | 表明实体采用 Unix 的文件压缩程序 |
| deflate | 表明实体采用 zlib 的格式压缩 |
| identity | 表明没有对实体进行编码。当没有 Content-Encoding 首部是,就默认为这种情况 |
gzip、compress 以及 deflate 编码都是无损压缩算法,用于减少传输报文的大小,不会导致信息损失。这些算法中,gzip 通常是效率最高的,使用最为广泛。
Accept-Encoding 首部
我们不希望服务器用客户端无法解码的方式来对内容进行编码。为了编码服务器使用客户端不支持的编码方式,客户端就把自己支持的内容编码方式列表放在请求的 Accept-Encoding 首部,服务器就可以假设客户端能够接受任何编码方式(等价于发送 Accept-Encoding: *)。
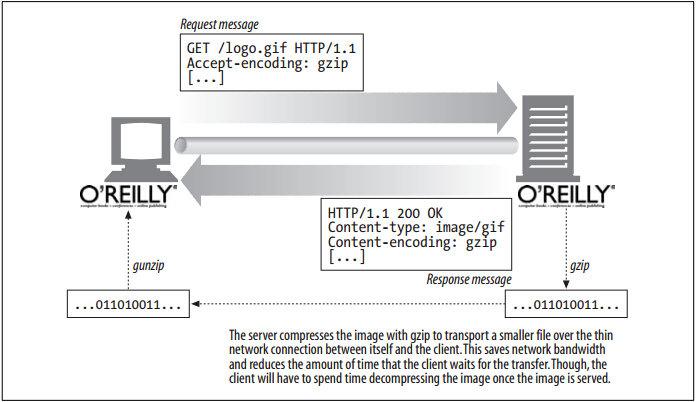
内容编码与 Content-Length
如果主体进行了内容编码,Content-Length 首部说明的就是编码后(encoded)的主体的字节长度,而不是未编码的原始主体长度。下面的示例说明了这个问题。
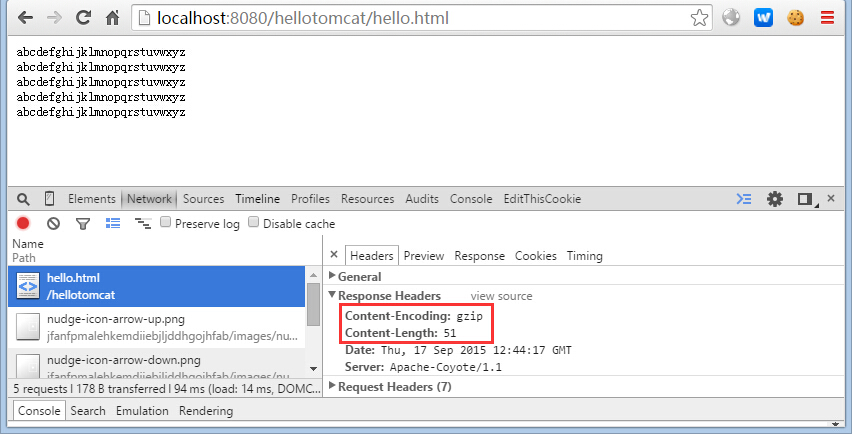
1. 在 Servert 中,使用 gizp 对响应内容进行压缩。
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { try { String data = "abcdefghijklmnopqrstuvwxyz " + "abcdefghijklmnopqrstuvwxyz " + "abcdefghijklmnopqrstuvwxyz " + "abcdefghijklmnopqrstuvwxyz " + "abcdefghijklmnopqrstuvwxyz "; ByteArrayOutputStream bout = new ByteArrayOutputStream(); GZIPOutputStream gout = new GZIPOutputStream(bout); gout.write(data.getBytes()); gout.close(); byte compressedData[] = bout.toByteArray(); resp.setHeader("Content-Encoding", "gzip"); resp.getOutputStream().write(compressedData); } catch (Exception e) { e.printStackTrace(); } }
2. 发送请求,查看响应报文。从下面的请求结果可以看出,浏览器对编码过的内容进行解码再显示出来,而 Content-Length 的值也不是原来内容的长度 140,而是编码后内容的长度 51。