1.作业一
要求:用requests和BeautifulSoup库方法定向爬取给定网址的数据,屏幕打印爬取的大学排名信息。
代码实现和结果:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
def daxue():
# 要爬取的网站
url="http://www.shanghairanking.cn/rankings/bcur/2020"
req=urllib.request.Request(url)
data=urllib.request.urlopen(req)
# 读取网站信息
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
# beautifulsoup解析网页内容
soup=BeautifulSoup(data,"html.parser")
# 使用css语法查找元素,查找<tbody>下的<tr>标签,返回一个列表,列表中存储每个大学的信息
list=soup.select("tbody tr")
# tplt = "{0:{3}^10} {1:{3}^10} {2:^10} {3:^10} {4:^10}"
# 规定每列所占的长度,使列表输出整齐
tplt = "{0:^13} {1:^13} {2:^13} {3:^10} {4:^10}"
# 输出列表的表头 chr(12288)中文
print(tplt.format("排名","学校","省市","类型","总分",chr(12288)))
for item in list[0:10]:
ls=item.select("td")
length=len(ls)
count=0
inf=[]
for i in ls[0:5]:
count+=1
text = i.text.replace(" ", "").replace("
", "")
inf.append(text)
# 依次输出大学信息
print(tplt.format(inf[0],inf[1],inf[2],inf[3],inf[4],chr(12288)))
daxue()
代码结果
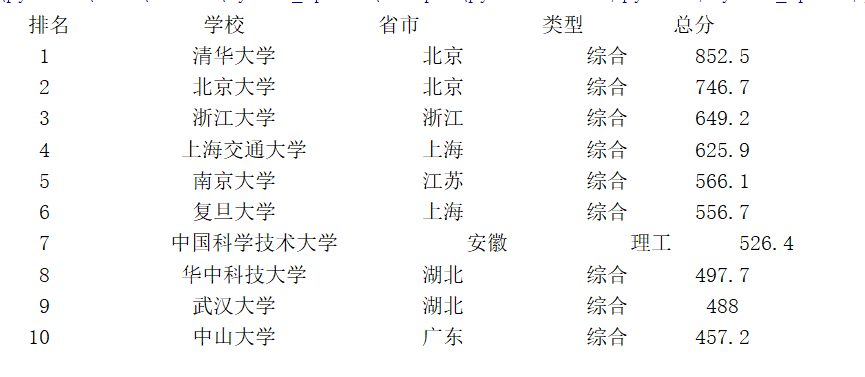
心得体会:第一次打印的时候输出的不齐,在网上找了一些方法,使用tplt = "{0:13} {1:13} {2:13} {3:10} {4:^10}"规定每列所占的长度
结果有所改善,但仍有瑕疵,下次试试dataframe
2.作业二
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码实现和结果:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import pandas as pd
import re
goods="铅笔"
keyword=urllib.parse.urlencode({"keyword":goods})
url="https://search.jd.com/Search?keyword="+keyword
#模拟浏览器头部信息,伪装成浏览器,而不是会报错的网络爬虫
head={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36 Edg/85.0.564.44"
}
# 获取网页内容
def getSoup(url):
req = urllib.request.Request(url,headers=head)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
# 调用BeautifulSoup解析网页内容
soup = BeautifulSoup(data, "html.parser")
return soup
def Spider(soup):
price_li=[]
goods_li=[]
# 选取网页中的价格等信息
# price = soup.select("div[class='p-price'] strong i")
#**价格的正则表达式**
reg = r'<em>¥</em><i>..*</i>'
price=re.findall(reg,str(soup))
goods = soup.select("div[class='p-name p-name-type-2'] a em")
for i in range(0,10):
if(i>len(price)):
break
# 获取价格的字符串并去掉空格换行
# price_li.append(price[i].text.replace("
","").replace(" ","").replace(" ",""))
price_li.append((price[0][13:]).replace("</i>",""))
goods_li.append(goods[i].text.replace("
","").replace(" ","").replace(" ",""))
dict={"商品":goods_li,"价格":price_li}
return dict
# 打印出商品
def printGoods(dict):
data=pd.DataFrame(dict)
# 设置列表的属性
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 200)
pd.set_option("expand_frame_repr",False)
pd.set_option('display.max_colwidth', 50)
pd.set_option('display.colheader_justify','center')
# 列表显示中文
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
print(data)
soup=getSoup(url)
dict=Spider(soup)
printGoods(dict)
结果:
 ###心得体会:
我特别超级无敌想用正则表达式,但是京东网页商品描述太乱了,没有统一的表达式,我被迫选择了css选择器
但价格可以用正则表达式
这次用dataframe打印表格,只是没想到它似乎没有设置单元格内容居左的函数,为了整齐我只能限制列宽让他不完全显示了
写代码之前就知道了淘宝反爬虫的厉害,没想到唯品会也这么强(还是我技艺不精),于是选了比较友好的京东
###心得体会:
我特别超级无敌想用正则表达式,但是京东网页商品描述太乱了,没有统一的表达式,我被迫选择了css选择器
但价格可以用正则表达式
这次用dataframe打印表格,只是没想到它似乎没有设置单元格内容居左的函数,为了整齐我只能限制列宽让他不完全显示了
写代码之前就知道了淘宝反爬虫的厉害,没想到唯品会也这么强(还是我技艺不精),于是选了比较友好的京东
3.作业三
要求:爬取一个给定网页或者自选网页的所有JPG格式文件
代码实现和结果:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import re
Wurl="http://xcb.fzu.edu.cn/"
head={ #模拟浏览器头部信息,伪装成浏览器,而不是会报错的网络爬虫
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36 Edg/85.0.564.44"
}
# 获取网页内容
def getSoup(url):
req = urllib.request.Request(url,headers=head)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "html.parser")
print(str(soup))
return str(soup)
def Spider(soup):
reg=r'img.*src="(.+?.jpg)"'
# listurl=re.findall(r'http:.[^"]+.jpg',soup)
listurl=re.findall(reg,soup)
# print(listurl)
x=1
#直接爬取的图片链接不是标准的url,要加http:
for xurl in listurl:
if(xurl.startswith("http:")):
url=xurl
else:
url=Wurl+xurl
# print(url)
pathName = "D://images//" + str(x) + ".jpg" # 设置保存路径和文件
urllib.request.urlretrieve(url,pathName)
x+=1
Spider(getSoup(Wurl))
结果:

心得体会
直接爬取的图片链接不是标准的url,要加http:,转化为标准url