首先我点开了作业博文
哦~~,任务是计算两篇的文章相似度
一如往常,我打开浏览器
先放上github的链接[https://github.com/haha123763/031804108]
百度方法
doc2vec,simhash,余弦都有尝试
一点开百度就看到了: TF-IDF这种方法没有考虑到文字背后的语义关联,但两个文档是相似的情况下,就需要考虑到文档的语义。而doc2vec考虑到文本的语义…………
我一看还能考虑到语义那自然是一百个精准加两百个有逼格了,好就是它了
一:首先尝试一下可以情感分析的doc2vec
doc2vec简介:
Doc2Vec 也可叫做 paragraph2vec, sentence embeddings,是一种非监督式算法,可以获得 sentences/paragraphs/documents 的向量表达,是 word2vec 的拓展。学出来的向量可以通过计算距离来找 sentences/paragraphs/documents 之间的相似性,可以用于文本聚类,对于有标签的数据,还可以用监督学习的方法进行文本分类,例如经典的情感分析问题。
先处理文本,从网上下载停用词表,读取样本文件内容
def seg_depart(sentence):
# 对文档中的每一行进行中文分词
sentence_depart = jieba.cut(sentence.strip())
# 创建一个停用词列表
stopwords = stopwordslist()
# 输出结果为outstr
outstr = ''
# 去停用词
for word in sentence_depart:
if word not in stopwords:
if word != ' ':
outstr += word
outstr += " "
return outstr
#获取文档内容
def get_dataset(path):
inputs=open(path,'r',encoding='UTF-8')
docs=""
for line in inputs:
line_seg = seg_depart(line)
docs=docs+line_seg
print(type(docs))
return docs
然后就是训练模型和测试了,写在一个方法中,用Dictionary将样本文档生成语料库,再用doc2vec将要对比的文档转化为稀疏向量,再来计算相似度
def ceshi1():
docs_test = get_dataset(path_sample) #训练样本的字符串形式
raw_documents =[docs_test]
# corpora_documents列表长度就是训练样本的文章个数,可以选择多篇文章一起比较
corpora_documents = []
for item_text in raw_documents:
item_str = list(jieba.cut(item_text))
corpora_documents.append(item_str)
# 生成字典和向量语料,用dictionary方法获取词袋(bag-of-words)
dictionary = corpora.Dictionary(corpora_documents)
corpus = [dictionary.doc2bow(text) for text in corpora_documents]
similarity = Similarity('-Similarity-index', corpus, num_features=2000)
test_data_1 = get_dataset(path_test)
test_cut_raw_1 = list(jieba.cut(test_data_1))
test_corpus_1 = dictionary.doc2bow(test_cut_raw_1)
similarity.num_best = 5
print(similarity[test_corpus_1]) # 返回最相似的样本材料,(index_of_document, similarity) tuples
return str(similarity[test_corpus_1][0][1])
开始运行,为了方便多比较几篇,得到的结果竟然是。。。
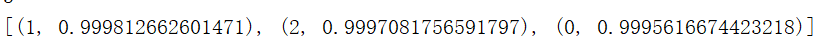
可能大概也许是不太准确的吧。。。。。。
二:又听说simhash更好,准确度和余弦差不多,但是耗时短,还适合比较长文本,试一下
simhash是google用来处理海量文本去重的算法。 google出品,你懂的。 simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
原理:
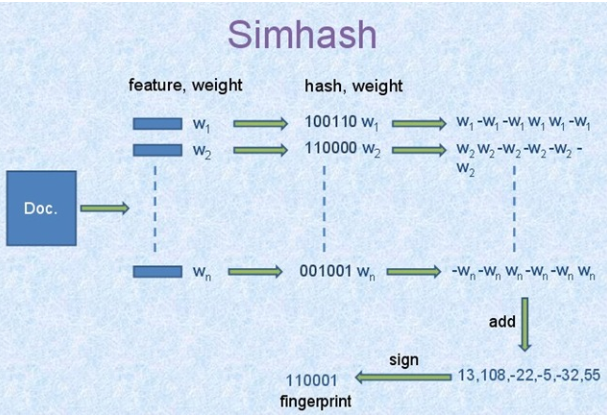
算法过程大概如下:
1,将Doc进行关键词抽取(其中包括分词和计算权重),抽取出n个(关键词,权重)对, 即图中的(feature, weight)们。 记为 feature_weight_pairs = [fw1, fw2 … fwn],其中 fwn = (feature_n,weight_n`)。
2,hash_weight_pairs = [ (hash(feature), weight) for feature, weight in feature_weight_pairs ] 生成图中的(hash,weight)们, 此时假设hash生成的位数bits_count = 6(如图);
3,然后对 hash_weight_pairs 进行位的纵向累加,如果该位是1,则+weight,如果是0,则-weight,最后生成bits_count个数字,如图所示是[13, 108, -22, -5, -32, 55], 这里产生的值和hash函数所用的算法相关。
4,[13,108,-22,-5,-32,55] -> 110001这个就很简单啦,正1负0。
然后重点就是 simhash值的海明距离计算,
二进制串A 和 二进制串B 的海明距离 就是 A xor B 后二进制中1的个数。
当我们算出所有doc的simhash值之后,需要计算doc A和doc B之间是否相似的条件是:A和B的海明距离是否小于等于n,这个n值根据经验一般取值为3,
simhash本质上是局部敏感性的hash,和md5之类的不一样。 正因为它的局部敏感性,所以我们可以使用海明距离来衡量simhash值的相似度。
# 求两篇文章相似度
def simhash_similarity(text1, text2):
"""
:param tex1: 文本1
:param text2: 文本2
:return: 返回两篇文章的相似度
"""
aa_simhash = Simhash(text1)
bb_simhash = Simhash(text2)
max_hashbit = max(len(bin(aa_simhash.value)), (len(bin(bb_simhash.value))))
print("33333333333",max_hashbit)
# 汉明距离
distince = aa_simhash.distance(bb_simhash)
# 相似度的计算
similar = 1 - distince / max_hashbit
return similar
得到的结果是
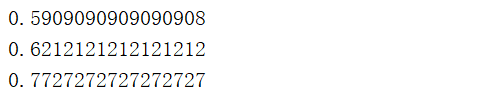
结果竟然这么不靠谱,难道这么长的文章还算是短文本吗
三:既然余弦和simhash准确度差不多,那我就用余弦吧
原理:
余弦相似性:两个向量的夹角越接近于0,其余弦值越接近于1,表明两个向量越相似。
文本相似度计算大致流程:分词 合并 计算特征值(选取词频作为特征值) 向量化 计算向量夹角余弦值
首先初始化类,向类中传入要比较的两个文本的字符串形式(已经经过停用词的过滤),并且设置topK=5000,topK表示返回关键词的数量,由于文本比较长,经过试验5000比较合适
class Similarity():
def __init__(self, target1, target2, topK=5000):
self.target1 = target1
self.target2 = target2
self.topK = topK
分词
def vector(self):
self.vdict1 = {}
self.vdict2 = {}
# 分别对文档1,2进行分词,返回 关键词和相应的权重的列表
# self.target1:待提取关键词的文本 topK:返回关键词的数量,重要性从高到低排序 withWeight:是否同时返回每个关键词的权重 allowPOS=():词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词
top_keywords1 = jieba.analyse.extract_tags(self.target1, topK=self.topK, withWeight=True)
top_keywords2 = jieba.analyse.extract_tags(self.target2, topK=self.topK, withWeight=True)
# 把关键词存储在相应字典,以键值对形式 关键词:权重
for k, v in top_keywords1:
self.vdict1[k] = v
for k, v in top_keywords2:
self.vdict2[k] = v
合并
def mix(self):
# 若key值存在于vdict1.keys()时,返回vdict1[key];若不存在于vdict1.keys()中时,返回0
# 保证两个字典的key相同
for key in self.vdict1:
self.vdict2[key] = self.vdict2.get(key, 0)
for key in self.vdict2:
self.vdict1[key] = self.vdict1.get(key, 0)
生成词频向量
# 计算相对词频
def mapminmax(vdict):
# 字典中的最小,最大权重,以及权重差值
_min = min(vdict.values())
_max = max(vdict.values())
_mid = _max - _min
# print _min, _max, _mid
# 对权重大小进行处理,标准化
for key in vdict:
vdict[key] = (vdict[key] - _min) / _mid
return vdict
# 得到标准化的权重大小
self.vdict1 = mapminmax(self.vdict1)
self.vdict2 = mapminmax(self.vdict2)
最后计算相似度
def similar(self):
self.vector()
self.mix()
sum = 0
# sum是两个字典相同键的值相乘的和
for key in self.vdict1:
sum += self.vdict1[key] * self.vdict2[key]
A = sqrt(reduce(lambda x, y: x + y, map(lambda x: x * x, self.vdict1.values())))
B = sqrt(reduce(lambda x, y: x + y, map(lambda x: x * x, self.vdict2.values())))
# 返回两个文档的相似度
return sum / (A * B)
测试一下,得到的结果是

看上去还挺靠谱的,那这就是我最终的代码了
性能分析
我是用pycharm自带的性能分析工具profile,结果如下
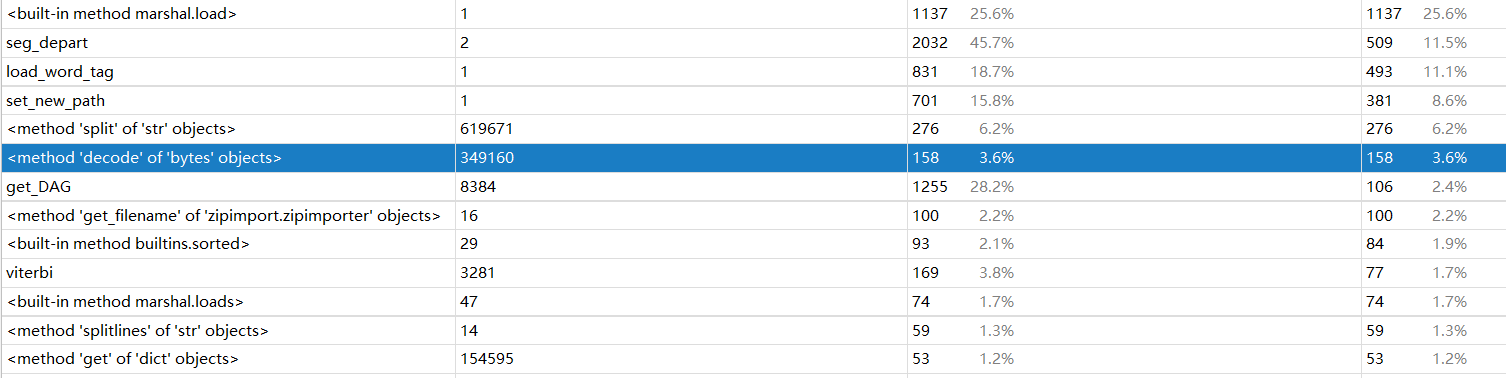
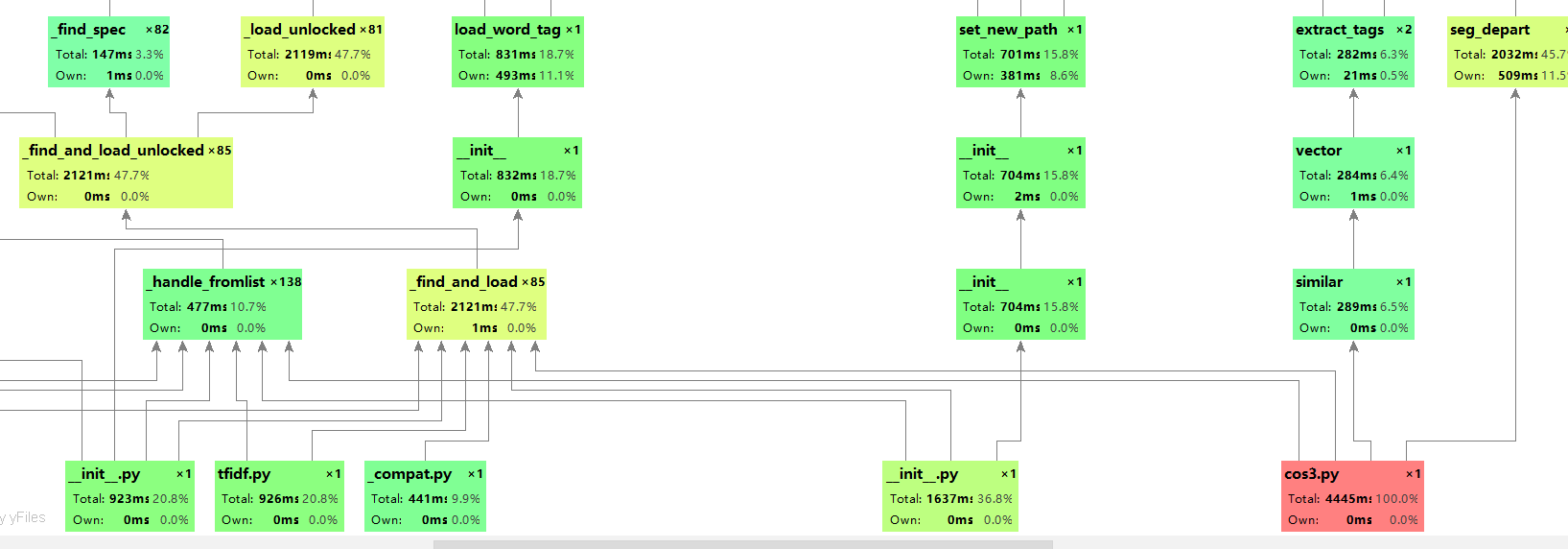
看来去掉停用词占用了不少时间
代码改进
这些代码是用余弦方法的基本步骤,我还真不知道怎么改,不过可以改改停用词的过滤,毕竟占了那么多时间,修改了停用词的内容,只剩下标点符号后
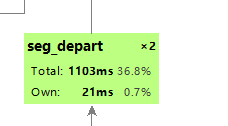
占用时间的确变小了,但是结果相较于之前也增加了1%,对准确度还是有一定影响的
你以为这就是我关于代码改进的所有修改吗,那你认真看以下上面关于doc2vec和simhash的介绍以及测试,我改的是方法啊!!!!!(改的可谓尽心尽力,屡败不爽)
单元测试
测试代码
import unittest
import cos3
path_sample = 'H:sim_0.8orig.txt'
path_test1 = 'H:sim_0.8orig_0.8_add.txt'
path_test2 = 'H:sim_0.8orig_0.8_del.txt'
path_test3 = 'H:sim_0.8orig_0.8_dis_1.txt'
path_test4="H:sim_0.8orig_0.8_dis_3.txt"
path_test5="H:sim_0.8orig_0.8_dis_7.txt"
class MyTest(unittest.TestCase): # 继承unittest.TestCase
def tearDown(self):
# 每个测试用例执行之后做操作
print('111_.....begin')
def setUp(self):
# 每个测试用例执行之前做操作
print('22222.....jieshu')
def test_1(self):
print(cos3.ceshi(path_sample,path_test1))
def test_2(self):
print(cos3.ceshi(path_sample, path_test2))
def test_3(self):
print(cos3.ceshi(path_sample, path_test3))
def test_4(self):
print(cos3.ceshi(path_sample, path_test4))
def test_5(self):
print(cos3.ceshi(path_sample, path_test5))
if __name__ == '__main__':
unittest.main() # 运行所有的测试用例
测试结果
至于覆盖率,用的coverage,虽然不是很美观,但是我只会这一个
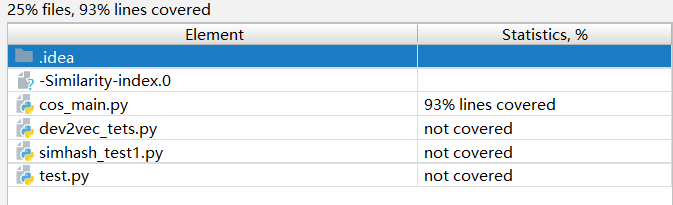
93%的覆盖率我也知足了
异常处理
异常主要有:相同文本相似度不是1 不同文本相似度是1 空文本的比较
创建异常类
class SameNot1(Exception):
def __init__(self):
print("一样的文件,相似度怎么会不一样呢,去改!")
class NotSAmeBut1(Exception):
def __init__(self):
print("不一样的文件,相似度竟然是1,去改!")
class Empty(Exception):
def __init__(self):
print("文档是空的,不用比了,让cpu歇会儿吧")
异常类的测试
if(t1==""):
raise Empty
if (result > 0.9999999):
raise SameNot1


PSP表格分析
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 90 | 90 |
| 估计这个任务需要多少时间 | 80 | 80 |
| 开发 | 660 | 1600 |
| 需求分析 (包括学习新技术) | 80 | 450 |
| 生成设计文档 | 70 | 80 |
| 设计复审 | 30 | 40 |
| 代码规范 (为目前的开发制定合适的规范) | 40 | 40 |
| 具体设计 | 50 | 70 |
| 具体编码 | 360 | 560 |
| 代码复审 | 20 | 30 |
| 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| 报告 | 120 | 150 |
| 测试报告 | 50 | 50 |
| 计算工作量 | 10 | 10 |
| 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1200 | 1660 |
总结
这次编程作业我更加坚信了自己的无知,我之前对python的了解仅限于基本语法,对他的各种库一无所知。这次作业查看了大量博客,从寻找方法,到参考代码还有github的使用,pycharm的功能,我学到了很多。以后做作业一定先找好可靠的方法再精心去优化它,而不是始乱终弃,优化结果全靠换方法。