摘要:物联网设备产生的数据是典型的时序数据,而时序数据库是存储时序数据的专业数据库系统,因此数据压缩对时序数据库来说是一项必不可少的能力。
本文分享自华为云社区《华为云数据库GaussDB(for Influx)揭秘第二期:解密GaussDB(for Influx)的数据压缩》,作者: 高斯Influx官方博客。
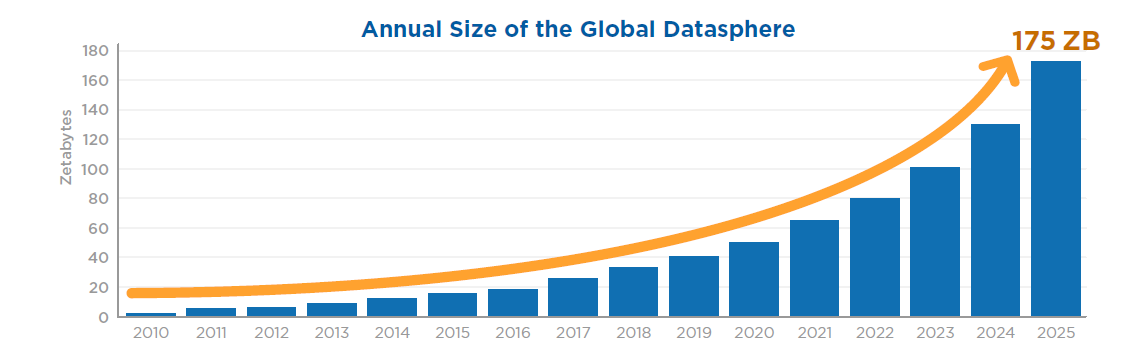
根据IDC的一份白皮书预测,到2025年全球数据总量将达到175ZB,其中物联网设备将生成90ZB数据,占比50%以上。以往物联网数据基本上都是先存储起来再处理,如今这一处理模式开始向“实时处理”模式转型。即便如此,数据的总量依然巨大,为降低数据存储成本,迫切地要求减少数据存储空间,这对数据压缩技术提出了更高的要求。物联网设备产生的数据是典型的时序数据,而时序数据库是存储时序数据的专业数据库系统,因此数据压缩对时序数据库来说是一项必不可少的能力。
什么是数据压缩?
众所周知,数据在计算机内部是以二进制方式表示和存储,因此,数据压缩,通俗地讲,就是以最少的比特数表示数据对象。数据压缩的本质是用计算时间换取存储空间,不同数据类型对应不同的数据压缩算法,不存在某个压缩算法能够压缩任意数据。数据压缩说到底是对数据趋势性、规律性的总结,这个数据规律性可分为基于内容(比如视频的帧与帧之间,图像的像素与像素之间的相似)、基于表示(比如变换编码,熵编码)和基于码流(比如差量压缩,深度压缩)等多种级别。
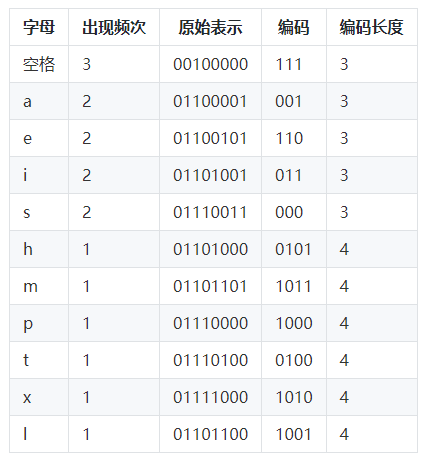
举一个数据压缩的简单例子:给定一个字符串"this is a example",正常情况下,每个字符占用8个比特位,该字符串含有17个字符(包含空格),每一个字符出现的频率分别是a(2),e(2),h(1),i(2),m(1),p(1), t(1),s(2),x(1),l(1),空格(3). 现在我们按照字母出现的频率进行编码,用111表示’ ‘(空格),001表示’a’,110表示’e’,011表示’i’,000表示’s’,0101表示’h’,1011表示’m’,1000表示’p’,0100表示’t’,1010表示’x’,1001表示’l’。最后"this is a example"被编码成 010001010110001110110001110011101010001101110001001110,共54个比特。相比未压缩前的136比特,存储空间缩小了2.5倍。
时序数据是如何被压缩的?
数据通过编码、重组或以其他方式修改数据以减少其大小来实现压缩的目的。前面例子中提到的方法叫Huffman编码,它是发明最早的一种数据压缩算法,它在文本压缩方面具有很优秀的表现。目前,数据压缩领域发展迅速,新的技术和方法不断涌现,层出不穷。一般我们将数据压缩技术分为有损压缩和无损压缩两大类。有损压缩,顾名思义,数据压缩导致数据原本携带的信息减少,有信息丢失,且丢失的信息无法恢复。无损压缩则相反,数据压缩时没有信息丢失。在时序数据库中,几乎都支持无损压缩,只有极少数支持有损压缩。时序数据库中常见的数据编码和压缩算法有如下几种:
游程编码(英语:run-length encoding,缩写RLE)
一种与数据性质无关的无损数据压缩技术,基于“使用变动长度的码来取代连续重复出现的原始数据”来实现压缩。举例来说,一组字符串“AAAABBBCCDEEEE” ,由4个A、3个B、2个C、1个D、4个E组成,经过RLE可将字符串压缩为4A3B2C1D4E。其优点是简单、速度快,能将连续重复性高的数据压缩成小单位。缺点也是明显的,重复性低的数据压缩效果不好。
XOR
该算法是结合遵循IEEE754标准的浮点数存储格式的数据特征设计的特定算法,第一个值不压缩, 后面的值是跟第一个值计算XOR(异或)的结果,如果结果相同,仅存储一个0,如果结果不同,存储XOR后的结果。该算法受数据波动影响,越剧烈压缩效果越差。
Delta
差分编码又称增量编码,编码时,第一个数据不变,其他数据转换为与上一个数据的delta。其原理与XOR类似,都是计算相邻两个数据的差异。该算法应用广泛,如需要查看文件的历史更改记录(版本控制、Git等)。在时序数据库中,很少单独使用,一般搭配RLE,Simple8b或者Zig-zag一起使用,压缩效果更好。
Delta-of-Delta
又名二阶差分编码,是在Delta编码的基础上再一次使用Delta编码,比较适合编码单调递增或者递减的序列数据。例如 2,4,4,6,8 , Delta编码后为2,2,0,2,2 ,再Delta编码后为2,0,-2,0,0。通常也会搭配RLE,Simple8b或者Zig-zag一起使用。
Zig-zag
Zig-zag的出现是为了解决varint算法对负数编码效率低的问题,它的原理非常简单,是将标志位后移至末尾,并去掉编码中多余的0,从而达到压缩的效果。对于比较小的数值压缩效率很高,但是对于大的数据效率不但没有提升可能还会有所下降。因此,Zig-zag通常和Delta编码搭配,Delta可以很好的将大数值数据变为较小的数值。
Snappy
Snappy压缩算法借鉴了LZ77算法的思路,由于LZ77算法中模式匹配过程有较高的时间复杂度,Google对其做了许多优化,并于2011年对外开源。其原理是假设我们有一个序列S=[9,1,2,3,4,5,1,2,3,4],匹配发现子序列S~2,5~=[1,2,3,4]与S~7,10~=[1,2,3,4]是相同的,于是将该序列编码为S=[9,1,2,3,4,5,6,(2,4)],2表示开始位置,4表示位数。Snappy的优点是速度快,压缩率合理,在众多开源项目中使用,比如Cassandra,Hadoop,MongoDB,RocksDB,Spark,InfluxDB等。
LZ4
LZ4数据压缩算法,它属于面向字节的LZ77压缩方案家族,压缩比并不高,它的特点是解码速度极快。据官方测试基准lzbench的测试结果,默认配置下,解压速度高达4970MB/s.
Simple8b
Simple8b是64位算法,实现将多个整形数据(在0和1<<60 -1之间)压缩到一个64位的存储结构中。其中前4位表示选择器,后面60位用于存储数据。优点是简单高效,定长编码保证了解压效率。但对于大整数或者浮动较大的值,压缩率较低,适用于范围较小的无符号整数。
LZO
LZO是块压缩算法,同样属于LZ77压缩方案家族,该算法的目标是快速压缩和解压缩,并非压缩比。相比之下,LZ4的解压速度更快。由于块中存放的数据类型可能多种多样,整体的压缩效果远没有针对某一种数据类型进行压缩的算法好。
DEFLATE
DEFLATE是同时使用了LZ77算法与哈夫曼编码(Huffman Coding)的一个经典无损数据压缩算法。实际上deflate只是一种压缩数据流的算法。该算法是zip文件压缩的默认算法,在gzip,zlib等算法中都有封装。
Zstandard
Zstandard(Zstd)的设计目的是提供一个类似于DEFLATE算法的压缩比,但更快,特别是解压缩。它的压缩级别从负5级(最快)到22级(压缩速度最慢,但是压缩比最高)可以调节。在文本日志压缩场景中,压缩性能与LZ4、Snappy相当甚至更好。Linux内核,HTTP协议,Hadoop,HBase等都已经加入对Zstd的支持,可以预见,Zstd将是未来几年里被广泛关注的压缩算法。
Bit-packing
Bit-packing(位压缩)压缩算法基于不是所有的整型都需要32位或者64位来存储这一前提,从我们要压缩的数据中删除不必要的位。比如一个32位的整型数据,其值的范围在【0,100】之间,则可以用7位就可以表示。
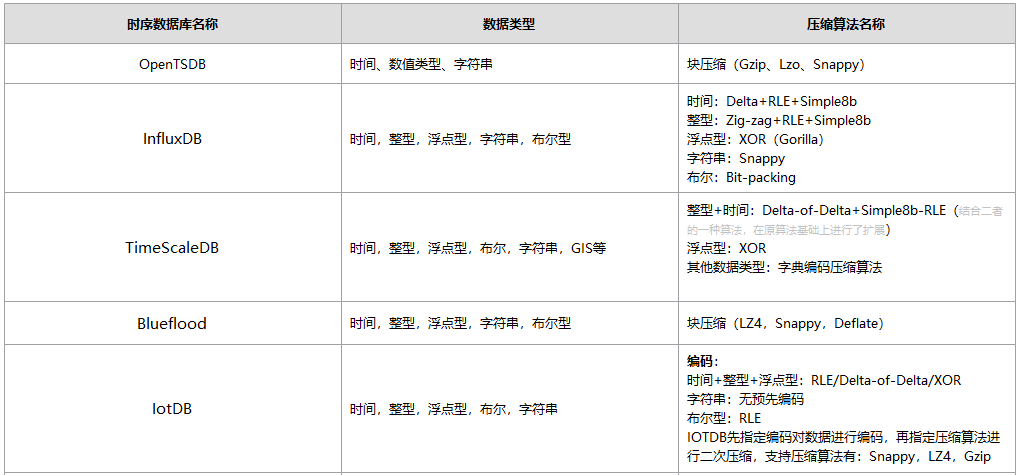
下表列举了一些常见的开源时序数据库和对应采用的数据压缩算法。
GaussDB(for Influx)的数据压缩
时序数据的业务特征决定了时序数据适合做压缩,时序数据的数据特征决定了时序数据可以被很好的压缩。数据压缩算法的压缩率和压缩速度是一对矛盾,压缩率高,必定压缩速度就会慢,反之亦然,压缩算法需要根据业务情况在二者之间找到合适的平衡点。数据压缩率与数据的存储方式密切相关,实验表明,行存的压缩率相比列存的压缩率差。为了达到更好的压缩率,华为云GaussDB(for Influx)时序数据库采用列式数据存储,相同数据类型的数据被存放在一起。在压缩算法层面,自研自适应压缩算法,针对不同数据类型和数据分布自动适配合适的数据压缩算法;在算法设计目标层面,数据的压缩率、压缩速度、解压速度需要满足每天万亿点写入和海量数据下绝大部分运维监控与IoT场景典型业务的并发查询性能要求。
时序数据的业务特征
不变性:时序数据在写入后,一般不会被修改。这个特征非常适用于压缩,不因修改某个数据对整个数据块进行修改。
时效性:时间越近的数据被访问的概率大,时间越是久远,数据被访问的概率越低。因此,对于时序的热数据,可以采用压缩和解压速度比较好,压缩率合理的压缩算法,而对于冷数据,非常适合使用更高压缩比的算法。
数据量庞大:时序数据的采集类型丰富, 随着采集硬件的普及和采集频率增加,使得数据量出现暴增,比如自动驾驶中每辆车每天就会采集将近 8T 的数据,带宽、实时写入、快速查询、存储、耗电以及维护成本都是挑战。
数据使用冷热:用户可能对某些数据源或者时间段的关注远远超过其他,因此在海量数据中偏向某些特殊时间段或某些数据源的数据查询。
时序数据的数据特征
Timestamp:稳定递增。某些时序数据是固定频率采样,例如城市空气质量检测仪每分钟采样一次pm2.5含量。还有部分时序数据是按照行为变化采样的,比如股市里的股价、交易数据、用户使用行为。
Filed的时间属性:同一数据源产生的时序数据都因有时间属性而有了先后顺序性和时间间隔属性。
Filed的取值特性:不同数据源的不同指标值往往归属某个区间范围,比如方向、速度、电压、温度等。
Filed的连续性:现实世界的事物是连续变化的,除非突发事件,或者接收数据的传感器设备故障,否则同一数据源的数据相邻时间段内产生的数据比较接近,比如服务器内存指标值的采集。
Filed的周期性:监控数据往往具有周期性或者规律性。
Filed的异常性:设备故障或突发事件引起的异常性。例如某个新闻事件引起网站流量的激增。
GaussDB(for Influx)自适应压缩算法
”大道至简“不仅是生活哲学,也是GaussDB(for Influx)自适应数据压缩算法的设计理念,化繁为简,合适的才是最好的。
每一种压缩方法都有其适合的数据类型和场景,比如Simple8b适合压缩整型数据,但是不适合大整数或者浮动较大的值,如果固定一种压缩算法对应一种数据类型,遇到不适合的场景,数据压缩算法便会失效。
GaussDB(for Influx)自适应压缩算法是一套框架,为每一种数据类型注册有若干具体数据压缩算法,比如Int(整型)有Simple8b、Delta、Delta-Of-Delta、Zigzag,ZSTD等。与传统的数据压缩算法相比,本质区别在于一种数据类型并非固定一种数据压缩算法,而是根据数据类型和数据分布选择最合适的数据压缩算法,比如当检测到大整型数据时,则放弃直接使用Simple8b,先使用Delta或者Delta-Of-Delta编码后,再使用Simple8b亦或者Zigzag算法。再比如Float(浮点)型数据,在大多时序数据库中直接采用XOR算法,但其实在实际的应用中,一些Float类型的数据可以转为整型来处理效果更好。
GaussDB(for Influx)自适应压缩算法的优势是扩展方便、灵活选择,能充分发挥每个数据压缩算法的最优性能。已经集成的算法有:RLE,Simple8b,Delta,Delta-Of-Delta,Zigzag,XOR,Zstd,Snappy,Bit-packing,LZ4等,未来还会继续加入更多高效压缩算法。目前还不支持有损压缩,后续根据需要还会加入有损压缩算法。
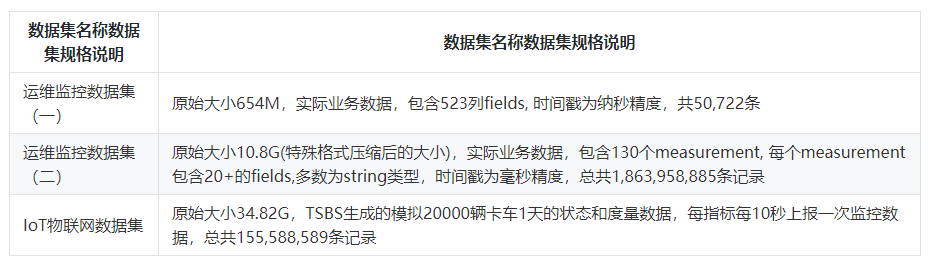
GaussDB(for Influx)与InfluxDB的压缩率结果对比和数据集说明如下表所示:
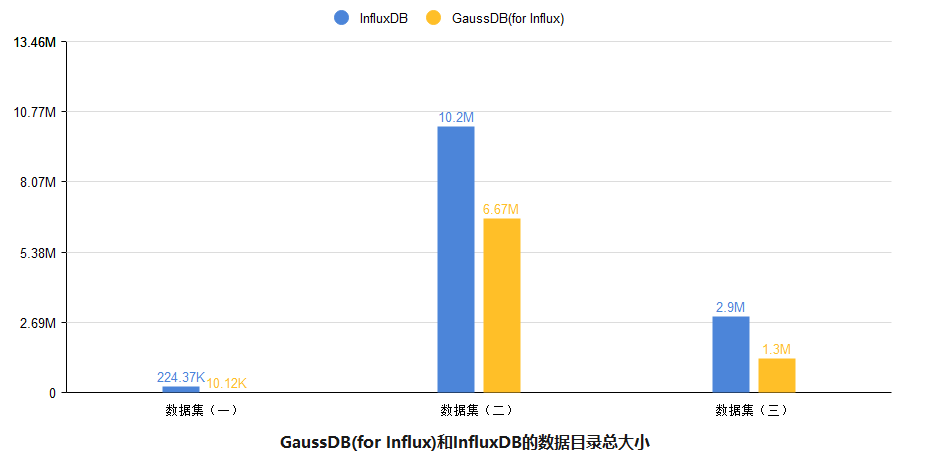
从对比图可以看出,自适应压缩算法相对于开源算法在压缩率有显著提升,同时数据压缩速度并未受损
总结
如今我们正处在云计算、5G和物联网的快速发展期,时序数据被视为越来越重要的同时,随着数据量的暴增,企业的存储成本也随之提高,数据压缩势在必行。庆幸的是,时序业务的特点决定了时序数据非常适合被压缩存储,时序数据的特征决定了时序数据可以被高效压缩。时序数据库作为时序数据存储的基础系统,数据压缩能力显得尤为重要。华为云时序数据库GaussDB (for Influx) 通过对典型场景深入分析后,提出了一个更高效的时序数据压缩算法-自适应数据压缩算法,在风力发电物联网场景下,250万时间线和150亿指标数据,整体数据压缩比达到6.8,是开源InfluxDB的1.3倍,OpenTSDB的2.8倍,其他的2-3倍。在运维监控场景下,华为云某服务存储空间从每天1035GB降低到82GB,缩减了12.6倍。