摘要:本文带大家从另一个角度来理解和认识图卷积网络的概念。
本文分享自华为云社区《技术综述十二:图网络的基本概念》,原文作者:一笑倾城。
基础概念
笔者认为,图的核心思想是学习一个函数映射f(.)f(.),借助该映射,图中的节点可以聚合自己的特征与邻居节点的特征,从而生成该节点的新特征表示。
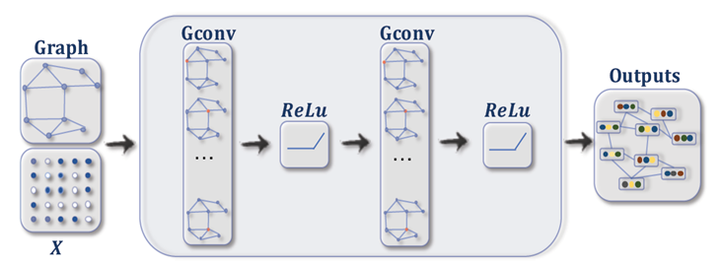
Figure 1. 图的一般推理过程[1]
图神经网络 Vs. 卷积神经网络
如图2所示,卷积神经网络的输入数据一般是规则的矩阵类型数据,例如图片。每个节点和其它节点的空间关系是固定的。而图神经网络的输入数据一般表现为不规则的拓扑结构,节点与节点的关系非常复杂,节点间的空间关系一般不做约束,节点间是否存在连接以及连接的数量不做约束。复杂的网络还涉及到连接的方向和子图等概念。
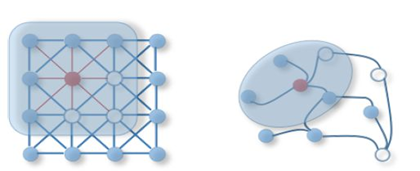
Figure 2. 图网络和卷积网络[1]
如图3所示,如果将图的每个节点等价视为图像中的每个像素,其实,图的工作过程可以类比CV中的经典问题:semantic segmentation。
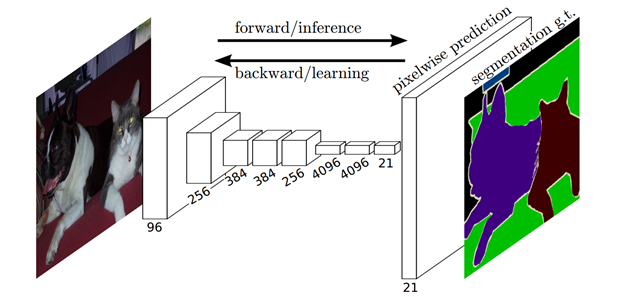
Figure 3. semantic segmentation[2]
图的基础组件及其实现
图在工作过程中,主要需要处理的问题有两个,一个是节点信息的提炼方式;另一个是邻近节点的搜索方式。整理如下:
邻近节点的搜索方式:
- 每个节点考虑全部其它节点
- 基于欧氏距离,只搜索近邻N个节点
节点信息的提炼方式:
- MLP+Max Pooling直接进行特征融合
- 基于attention,对周边节点进行加权平均
- 普通attention
- Self-attention (Bert/Transformer)
其中,邻近节点的搜索方式有两种,基于Bert作为图卷积网络的方案,一般是全部节点统一输入,每个节点在进行self-attention时,统一考虑其它节点,因此,可以视为全局搜索,典型的样例是LayoutLM。而基于某种距离度量搜索邻近的节点的方式, 一般来说更加注重局部信息。可以依据特定任务进行一些定制化的距离设计。缺点是过于注重局部信息,不能让图网络充分发挥能力。
另一方面是节点信息的提炼方式,简单的方法就是直接对相邻节点做1 imes11×1卷积,再进行max pooling。目前更流行的方法是基于attention,普通attention,如图4所示,输入特征一般由中心节点特征t_iti和相邻节点t_jtj,以及彼此的距离等信息拼接而成,考虑周围32个节点,则生成32个特征,并在此基础上计算权重向量alpha_iαi,得到这32个特征向量的权重,再进行加权和,得到节点ii的新特征表达t'_iti′。基于self-attention的方法工作机制类似。
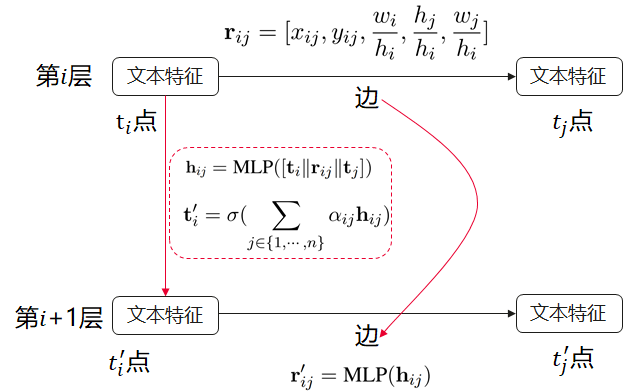
Figure 4. 图节点信息的提炼过程
总结
最后,图卷积和卷积之间的一些对比整理在图5中。我们可以观察到一些有趣的现象,其实在卷积网络中,也有邻近节点搜索方式的一些工作,例如空洞卷积和可变形卷积。

Figure 5. 图网络和卷积网络工作方式比较
参考文献:
[1] Wu, Zonghan, et al. “A comprehensive survey on graph neural networks.” IEEE transactions on neural networks and learning systems (2020).
[2] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.