摘要:本文就目标检测算法的基础知识进行简要综述,方便大家学习查看。
图片分类任务我们已经熟悉了,就是算法对其中的对象进行分类。而今天我们要了解构建神经网络的另一个问题,即目标检测问题。这意味着,我们不仅要用算法判断图片中是不是一辆汽车,还要在图片中标记出它的位置,用边框或红色方框把汽车圈起来,这就是目标检测问题。本文就目标检测算法的基础知识进行简要综述,方便大家学习查看。
目标检测基础知识
网络的阶段之分
- 双阶段(two-stage):第一级网络用于候选区域提取;第二级网络对提取的候选区域进行分类和精确坐标回归,例如RCNN系列。
- 单阶段(one-stage):掘弃了候选区域提取这一步骤,只用一级网络就完成了分类和回归两个任务,例如YOLO和SSD等。
单阶段网络为何不如双阶段的原因
因为训练中的正负例不均衡。
- 负例过多,正例过少,负例产生的损失完全淹没了正例;
- 大多数负例十分容易区分,网络无法学习到有用信息。如果训练数据中存在大量这样的样本,将导致网络难以收敛。
双阶段网络如何解决训练中的不均衡
- 在RPN网络中,根据前景置信度选择最有可能的候选区域,从而避免大量容易区分的负例。
- 训练过程中根据交并比进行采样,将正负样本比例设为1:3,防止过多负例出现。
常见数据集
Pascal VOC数据集
分为2007和2012两个版本,其提供的数据集里包含了20类的物体。
PASCALVOC的主要5个任务:
- ①分类:对于每一个分类,判断该分类是否在测试照片上存在(共20类);
- ②检测:检测目标对象在待测试图片中的位置并给出矩形框坐标(boundingbox);
- ③分割:对于待测照片中的任何一个像素,判断哪一个分类包含该像素(如果20个分类没有一个包含该像素,那么该像素属于背景);
- ④人体动作识别(在给定矩形框位置的情况下)
- ⑤LargeScaleRecognition(由ImageNet主办)
导入图像对应的.xml文件,在标注文件中的每一幅图像的每一个目标,对应一个体dict
- 属性'boxes'
- 属性'gt_classes'
- 属性'gt_overlaps'
- 属性'flipped'
- 属性'seg_areas'
CoCo 数据集
分为2014、2015、2017 三个版本

在annotations文件夹中对数据标注信息进行统一管理。例如,train2014的检测与分割标注文件为instances_train2014.json
objectinstances(目标实例)、objectkeypoints(目标关键点)、imagecaptions(看图说话)三种类型的标注
常见评价指标
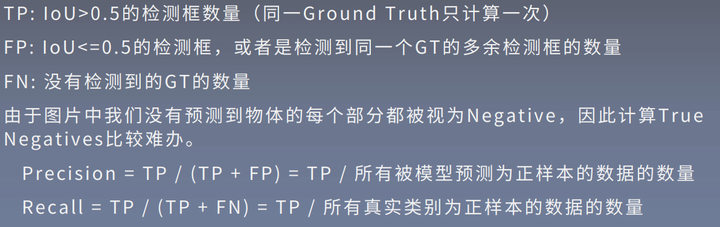
- True positives(TP):被正确的划分到正例的个数,即实际为正例且被划分为正例的实例数。
- False positives(FP):被错误地划分为正例的个数,即实际为负例但被划分为正例的实例数。
- False negatives(FN):被错误的划分为负例的个数,即实际为正例但被划分为负例的实例数。
- True negatives(TN):被正确的划分为负例的个数,实际为负例且被划分为负例的实例数。
Precision = TP/(TP+FP) = TP/所有被模型预测为正例的数据
Recall = TP/(TP+FN) = TP/所有真实类别为正例的数据
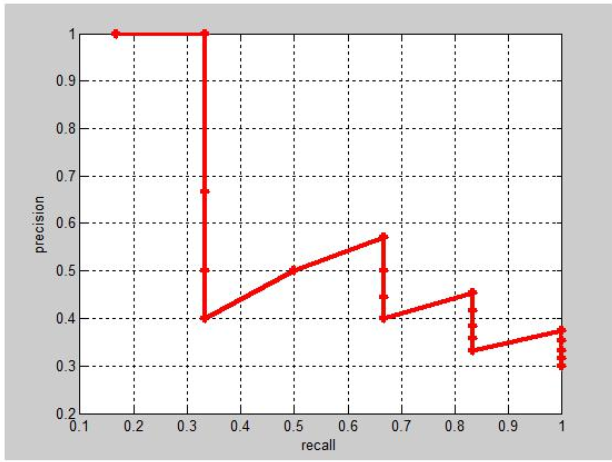
PR曲线
我们希望检测的结果P越高越好,R也越高越好,但事实上这两者在某些情况下是矛盾的。
所以我们需要做的是找到一种精确率与召回率之间的平衡。其中一个方法就是画出PR曲线,然后用PR曲线下方的面积AUC(AreaunderCurve)去判断模型的好坏。
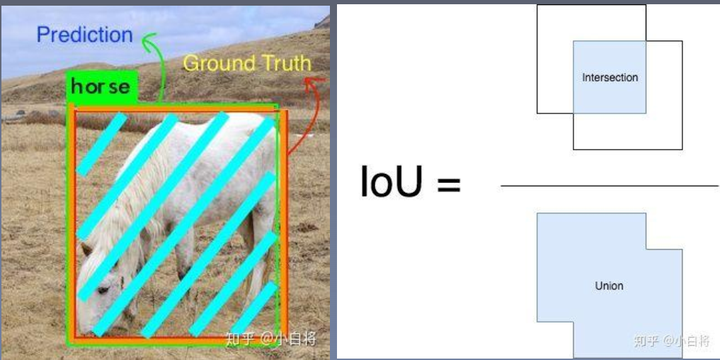
IOU指标
IoU是预测框与ground truth的交集和并集的比值。
对于每个类,预测框和ground truth重叠的区域是交集,而横跨的总区域就是并集。
目标检测中的PR
VOC中mAP的计算方法
通过PR曲线,我们可以得到对应的AP值:
在2010年以前,PASCALVOC竞赛中AP是这么定义的:
- 首先要对模型预测结果进行排序(即照各个预测值置信度降序排列)。
- 我们把recall的值从0到1划分为11份:0、1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0。
- 在每个recall区间(0-0.1,0.1-0.2,2-0.3,…,0.9-1.0)上我们计算精确率的最大值,然后再计算这些精确率最大值的总和并平均,就是AP值。
从2010年之后,PASCALVOC竞赛把这11份recall点换成了PR曲线中的所有recall数据点。
对于某个recall值r,precision值取所有recall>=r中的最大值(这样保证了p-r曲线是单调递减的,避免曲线出现摇摆)这种方法叫做all-points-interpolation。这个AP值也就是PR曲线下的面积值。
具体例子:

Coco中mAP的计算方法
采用的是IOU(用于决定是否为TP)在[0.5:0.05:0.95]计算10次AP,然后求均值的方法计算AP。
非极大值抑制
NMS算法一般是为了去掉模型预测后的多余框,其一般设有一个nms_threshold=0.5,
具体的实现思路如下:
- 选取这类box中scores最大的哪一个,记为box_best,并保留它
- 计算box_best与其余的box的IOU
- 如果其IOU>0.5了,那么就舍弃这个box(由于可能这两个box表示同一目标,所以保
- 留分数高的哪一个)
- 从最后剩余的boxes中,再找出最大scores的哪一个,如此循环往复
本文分享自华为云社区《目标检测基础知识》,原文作者:lutianfei 。