摘要:分布式异步对象存储 (DAOS) 是一个开源的对象存储系统,专为大规模分布式非易失性内存 (NVM, Non-Volatile Memory) 设计,利用了 SCM(Storage-Class Memory) 和 NVMe(Non-Volatile Memory express) 等的下一代 NVM 技术。
分布式异步对象存储 (DAOS) 是一个开源的对象存储系统,专为大规模分布式非易失性内存 (NVM, Non-Volatile Memory) 设计,利用了 SCM(Storage-Class Memory) 和 NVMe(Non-Volatile Memory express) 等的下一代 NVM 技术。
DAOS 是一种横向扩展的对象存储,可以为高性能计算应用提供高带宽、低延迟和高 IOPS 的存储容器,并支持结合仿真、数据分析和机器学习的下一代以数据为中心的工作流程。
与主要针对旋转介质设计的传统存储堆栈不同,DAOS 针对全新 NVM 技术进行了重新构建,可在用户空间中端对端地运行,并能完全绕开操作系统,是一套轻量级的系统。
DAOS 提供了一种为访问高细粒度数据提供原生支持的 I/O 模型,而不是传统的基于高延迟和块存储设计的 I/O 模型,从而释放下一代存储技术的性能。
与传统的缓冲区不同,DAOS 是一个独立的高性能容错存储层,它不依赖其它层来管理元数据并提供数据恢复能力。DAOS 服务器将其元数据保存在持久内存中,而将批量数据直接保存在 NVMe 固态盘中。
DAOS 特性
DAOS 依靠 OFI(OpenFabric Interface) 绕过操作系统,将 DAOS 操作交付给 DAOS 存储服务器,充分利用架构中的任何远程直接内存访问 (RDMA, Remote Direct Memory Access) 功能,进行低延迟、高消息速率的用户空间通信,并将数据存储在持久内存和 NVMe 固态盘中。
DAOS 的键值存储接口提供了统一的存储模型,通过迁移 I/O 中间件库实现对 DAOS API 的原生支持后,就能利用 DAOS 丰富的 API 和先进功能,例如 HDF5、MPI-IO 和 Apache Arrow。
DAOS 还提供 POSIX 的仿真。POSIX 不再是新数据模型的基础,而是像其他 I/O 中间件一样,POSIX 接口将构建为 DAOS 后端 API 顶部的库。
DAOS 的 I/O 操作会被记录并存储到 SCM 维护到持久索引中,每次 I/O 都用一个特定时间戳标记,并与数据集的特定版本关联。内部不执行读-修改-写 (read-modify-write) 操作,写入操作是无损的,对对齐不敏感。在读取请求时,DAOS 服务器遍历持久索引,创建聚合 RDMA 描述符,从而直接在应用程序提供的缓冲区中重建所请求的版本的数据。
SCM 直接映射到 DAOS 服务地址空间的内存,DAOS 服务通过直接加载/存储来管理持久索引。根据不同 I/O 的特性,DAOS 服务可以决定将 I/O 存储在 SCM 或 NVMe 中:
- 对延迟敏感的I/O(如应用程序元数据和字节粒度数据)通常存储在 SCM 中;
- 检查点和批量数据存储在 NVMe 中。
这种方法允许 DAOS 将数据流式传输到 NVMe 中,并在 SCM 中维护内部元数据索引,为批量数据提供原始 NVMe 带宽。持久内存开发工具包 PMDK 管理对 SCM 的事务性访问,存储性能开发工具包 SPDK 对 NVMe 设备进行用户空间 I/O 操作。
DAOS 可以提供:
- 超高细粒度、低延迟和真正零拷贝的 I/O
- 非阻塞型数据和元数据操作,以支持 I/O 和计算重叠
- 先进的数据放置,以解决故障域
- 由软件管理冗余,可通过在线重建,支持复制和擦除代码
- 端到端 (E2E) 数据完整性
- 可扩展的分布式事务,提供可靠的数据一致性和自动恢复功能
- 数据集快照功能
- 安全框架,用于管理存储池的访问控制
- 软件定义存储管理,用于调配、配置、修改和监控存储池
- 通过 DAOS 数据模型和 API,为 I/O 中间件库(例如 HDF5、 MPI-IO 和 POSIX)提供原生支持。应用无需移植代码,即可直接使用 DAOS API
- Apache Spark 集成
- 使用发布/订阅 API,实现原生生产者/消费者工作流程
- 数据索引和查询功能
- 存储内计算,以减少存储和计算节点之间的数据移动
- 容灾工具
- 与 Lustre 并行文件系统无缝集成,并能扩展到其他并行文件系统,从而为跨多个存储层的数据访问提供统一的命名空间
- 数据搬运器,用于在 DAOS 池之间迁移数据集,将数据集从并行文件系统迁移到 DAOS,反之亦然
DAOS 组件
一个数据中心可能有数十万个计算节点,通过一个可伸缩的高性能结构相互连接,其中所有节点或称为存储节点的节点子集都可以直接访问 NVM 存储。
DAOS 安装涉及几个可以集中或分布式的组件。
DAOS 系统和存储节点
DAOS系统由一个系统名标识,它由一组连接到同一结构的 DAOS 存储节点组成。DAOS 存储节点为每个节点运行一个 DAOS 服务实例,该实例为每个物理套接字启动一个 DAOS I/O 引擎进程。这些 DAOS 服务的信息被记录到系统映射中,该映射为每个 I/O 引擎进程分配一个唯一的整数秩。两个不同的 DAOS 系统由两组不相交的 DAOS 服务器组成,它们之间无法相互配合。
DAOS 服务
DAOS 服务是一个多租户守护进程,运行在每个存储节点的 Linux 实例上(物理节点、虚拟机或容器)。服务的 I/O 引擎子进程通过网络导出本地连接的 SCM 和 NVM 存储。服务监听一个管理端口(由 IP 地址和 TCP 端口号寻址),以及一个或多个结构端点(由网络 URI 寻址)。
DAOS 服务通过 /etc/DAOS 中的 YAML 文件进行配置,包括其 I/O 引擎子进程的配置。服务的启动可以与不同的守护进程管理或编排框架集成(systemd 脚本、Kubernetes 服务、或类似 pdsh 和 srun 的并行启动程序)。
I/O引擎
在 DAOS I/O 引擎中,存储静态地跨越多个 Target 分区,增强并发能力。为了避免竞争,每个 Target 都有其私有存储、自己的服务线程池以及专用的网络上下文,这些上下文可以直接通过结构寻址,而不依赖于托管在同一存储节点上的其他 Target 。
SCM 模块通常以 AppDirect interleaved 模式配置。因此,它们作为每个套接字(在 fsdax 模式)的单个 PMEM 命名空间呈现给操作系统。当配置每个 I/O 引擎的 N 个 Target 时,每个 Target 都使用该套接字 fsdax 的 SCM 容量的 frac{1}{N}N1,与其它 Target 独立。每个 Target 还使用连接到此套接字的 NVMe 驱动器容量的一小部分。
Target
Target 没有针对存储介质故障实现任何内部数据保护机制。因此,一个 Target 就是一个单点故障,同时也是故障单元。动态状态与每个 Target 相关联:其状态可以是“up and running”,也可以是“down and not available”。
Target 是性能的单位。与 Target 关联的硬件组件(如后端存储介质、CPU 核心和网络)的能力和容量有限。
DAOS I/O 引擎实例导出的 Target 数是可配置的,取决于底层硬件(I/O 引擎实例的 SCM 模块数和 NVMe SSD 数)。I/O 引擎的 Target 数的最佳配置是该 I/O 引擎服务的 NVMe 驱动器数的整数倍。
存储 API、应用程序接口和工具
应用程序、用户和管理员可以通过两个不同的客户端 API 与 DAOS 系统交互。
管理 API 提供了管理 DAOS 系统的接口。它旨在与不同供应商的存储管理或开源编排框架集成。dmg 命令行工具是在 DAOS 的管理 API 上构建的。
DAOS 库 libdaos 实现了 DAOS 存储模型,主要提供给希望在 DAOS 系统中存储数据集的应用程序和 I/O 中间件的开发人员。用户常用的 daos 命令等的也构建在 API 之上,允许用户通过命令行管理数据集。
应用程序可以通过本机 DAOS API、I/O 中间件库(如 POSIX 仿真、MPI-IO、HDF5)或已与本机 DAOS 存储模型集成的 Spark 或 TensorFlow 等框架直接访问存储在 DAOS 中的数据集。
代理
DAOS 代理是驻留在客户端节点上的守护进程,通过与 DAOS 库交互验证应用程序进程。它是一个可信任的实体,支持使用证书对 DAOS 客户端进行签名。DAOS 代理支持不同的身份验证框架,并使用 Unix 域套接字与客户端库通信。
存储模型
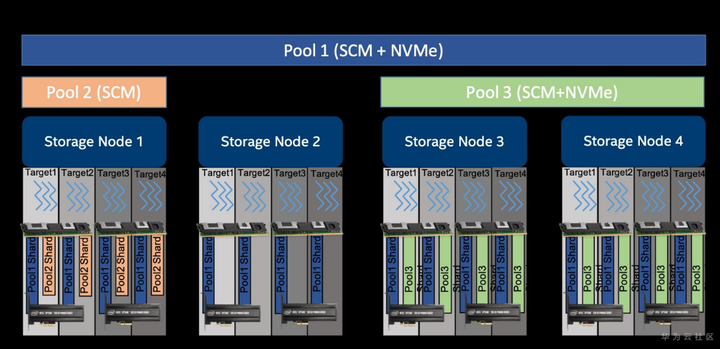
DAOS Pool 是分布在 Target 集合上的存储资源预留。分配给每个 Target 上的 Pool 的实际空间称为 Pool Shard。
分配给 Pool 的总空间在创建时确定,后期可以通过调整所有 Pool Shard 的大小(在每个 Target 专用的存储容量限制内)或跨越更多 Target(添加更多 Pool Shard)来随时间扩展。
Pool 提供了存储虚拟化,是资源调配和隔离的单元。DAOS Pool 不能跨多个系统。
一个 Pool 可以承载多个称为 DAOS Container 的事务对象存储。每个 Container 都是一个私有的对象地址空间,可以对其进行事务性修改,并且独立于存储在同一 Pool 中的其他 Container。Container 是快照和数据管理的单元。属于 Container 的 DAOS 对象可以分布在当前 Pool 的任何一个 Target 上以提高性能和恢复能力,并且可以通过不同的 API 访问,从而高效地表示结构化、半结构化和非结构化数据。
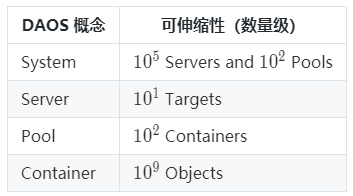
下表显示了每个 DAOS 概念的目标可伸缩性级别:
DAOS Pool
Pool 由唯一的 Pool UUID 标识,并在称为 Pool 映射的持久版本控制列表中维护 Target 成员身份。成员资格是确定的和一致的,成员资格的变更是按顺序编号的。Pool 映射不仅记录活跃 Target 的列表,还以树的形式包含存储拓扑,用于标识共享公共硬件组件的 Target。例如,树的第一级可以表示共享同一主板的 Target,第二级可以表示共享同一机架的所有主板,最后第三级可以表示同一机房中的所有机架。
该框架有效地表示了层次化的容错域,然后使用这些容错域来避免将冗余数据放置在发生相关故障的 Target 上。在任何时候,都可以将新 Target 添加到 Pool 映射中,并且可以排除失败的 Target。此外,Pool 映射是完全版本化的,这有效地为映射的每次修改分配了唯一的序列,特别是对于失败节点的删除。
Pool Shard 是永久内存的预留,可以选择与特定 Target 上 NVMe 预先分配的空间相结合。它有一个固定的容量,满了就不能运行。可以随时查询当前空间使用情况,并报告 Pool Shard 中存储的任何数据类型所使用的总字节数。
一旦 Target 失败并从 Pool 映射中排除,Pool 中的数据冗余将自动在线恢复。这种自愈过程称为重建。重建进度定期记录在永久内存中存储的 Pool 中的特殊日志中,以解决级联故障。添加新 Target 时,数据会自动迁移到新添加的 Target,以便在所有成员之间平均分配占用的空间。这个过程称为空间再平衡,使用专用的持久性日志来支持中断和重启。
Pool 是分布在不同存储节点上的一组 Target,在这些节点上分布数据和元数据以实现水平可伸缩性,并使用复制或纠删码 (erasure code) 确保持久性和可用性。
创建 Pool 时,必须定义一组系统属性以配置 Pool 支持的不同功能。此外,用户还可以定义将持久存储的属性。
Pool 只能由经过身份验证和授权的应用程序访问。DAOS 支持多种安全框架,例如 NFSv4 访问控制列表或基于第三方的身份验证 (Kerberos)。连接到 Pool 时强制执行安全性检查。成功连接到 Pool 后,将向应用程序进程返回连接上下文。
如前文所述,Pool 存储许多不同种类的持久性元数据,如 Pool 映射、身份验证和授权信息、用户属性、特性和重建日志。这些元数据非常关键,需要最高级别的恢复能力。因此,Pool 的元数据被复制到几个来自不同高级容错域的节点上。对于具有数十万个存储节点的非常大的配置来说,这些节点中只有很小的一部分(大约几十个)运行 Pool 元数据服务。在存储节点数量有限的情况下,DAOS 可以依赖一致性算法来达成一致,在出现故障时保证一致性,避免脑裂。
要访问 Pool,用户进程应该连接到 Pool 并通过安全检查。一旦授权,Pool 就可以与任何或所有对等应用程序进程(类似 openg() POSIX 扩展)共享(通过 local2global() 和 global2local() 操作)连接。这种集体连接机制有助于在数据中心上运行大规模分布式作业时避免元数据请求风暴。当发出连接请求的原始进程与 Pool 断开连接时,Pool 连接将被注销。
DAOS Container
Container 代表 Pool 中的对象地址空间,由 Container UUID 标识。
下图显示了用户(I/O 中间件、特定领域的数据格式、大数据或 AI 框架等)如何使用 Container 来存储相关数据集:
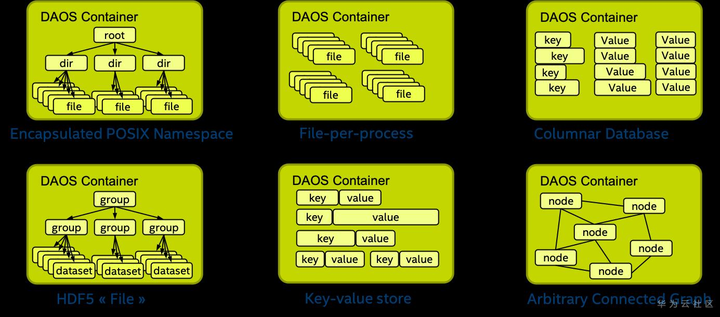
与 Pool 一样,Container 可以存储用户属性。Container 在创建时必须传递一组属性,以配置不同的功能,例如校验和。
要访问 Container,应用程序必须首先连接到 Pool,然后打开 Container。如果应用程序被授权访问 Container,则返回 Container 句柄,它的功能包括授权应用程序中的任何进程访问 Container 及其内容。打开进程可以与所有对等进程共享此句柄。它们的功能在 Container 关闭时被撤销。
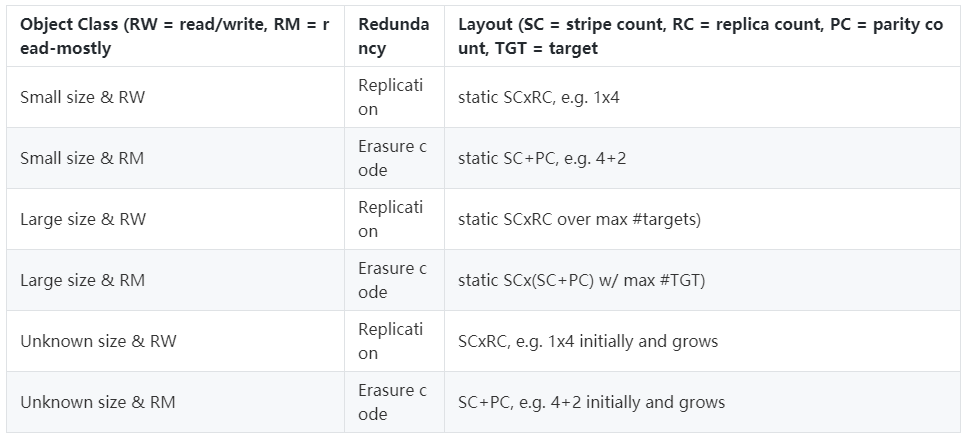
Container 中的对象可能具有不同的模式,用于处理数据分布和 Target 上的冗余,定义对象模式所需的一些参数包括动态或静态条带化、复制或纠删码。Object 类定义了一组对象的公共模式属性,每个 Object 类都被分配一个唯一的标识符,并在 Pool 级别与给定的模式相关联。一个新的 Object 类可以在任何时候用一个可配置的模式来定义,这个模式在创建之后是不可变的(或者至少在属于这个类的所有对象都被销毁之前)。
为了方便起见,在创建 Pool 时,默认情况下会预定义几个最常用的 Object 类:
如下所示,Container 中的每个对象都由一个唯一的 128 位对象地址标识。对象地址的高 32 位保留给 DAOS 来编码内部元数据,比如 Object 类。剩下的 96 位由用户管理,在 Container 中应该是唯一的。只要保证唯一性,栈的上层就可以使用这些位来编码它们的元数据。DAOS API 为每个 Container 提供了 64 位可伸缩对象 ID 分配器。应用程序要存储的对象 ID 是完整的 128 位地址,该地址仅供一次性使用,并且只能与单个对象模式相关联。
<---------------------------------- 128 bits ----------------------------------> -------------------------------------------------------------------------------- |DAOS Internal Bits| Unique User Bits | -------------------------------------------------------------------------------- <---- 32 bits ----><------------------------- 96 bits ------------------------->
Container 是事务和版本控制的基本单元。所有的对象操作都被 DAOS 库隐式地标记为一个称为 epoch 的时间戳。DAOS 事务 API 允许组合多个对象更新到单个原子事务中,并基于 epoch 顺序进行多版本并发控制。所有版本更新都可以定期聚合,以回收重叠写入所占用的空间,并降低元数据复杂性。快照是一个永久引用,可以放置在特定的 epoch 上以防止聚合。
Container 元数据(快照列表、打开的句柄、对象类、用户属性、属性和其他)存储在持久性内存中,并由专用 Container 元数据服务维护,该服务使用与父元数据 Pool 服务相同的复制引擎或自己的引擎,这在创建 Container 时是可配置的。
与 Pool 一样,对 Container 的访问由 Container 句柄控制。要获取有效的句柄,应用程序进程必须打开 Container 并通过安全检查。然后,可以通过 Container 的 local2global() 和 global2local() 操作与其他对等应用程序进程共享此句柄。
DAOS Object
为了避免传统存储系统常见的扩展问题和开销,DAOS 有意将对象简化,不提供类型和架构之外的默认对象元数据。这意味着系统不维护时间、大小、所有者、权限,甚至不跟踪开启者。
为了实现高可用性和水平伸缩性,DAOS 提供了许多对象模式(复制/纠删码、静态/动态条带化等)。模式框架是灵活的,并且易于扩展,以允许将来使用新的自定义模式类型。模式布局是在对象标识符和 Pool 映射打开的对象上通过算法生成的。通过在网络传输和存储期间使用校验和保护对象数据,确保了端到端的完整性。
可以通过不同的 API 访问 DAOS 对象:
- Multi-level key-array API 是具有局部性特征的本机对象接口。密钥分为分发密钥 (dkey) 和属性密钥 (akey)。dkey 和 akey 都可以是可变长度的类型(字符串、整数或其它复杂的数据结构)。同一 dkey 下的所有条目都保证在同一 Target 上并置。与 akey 关联的值可以是不能部分修改的单个可变长度值,也可以是固定长度值的数组。akeys 和 dkey 都支持枚举。
- Key-value API 提供了一个简单的键和可变长度值接口。它支持传统的 put、get、remove 和 list 操作。
- Array API 实现了一个由固定大小的元素组成的一维数组,该数组的寻址方式是 64 位偏移寻址。DAOS 数组支持任意范围的读、写和 punch 操作。
事务模型
DAOS API 支持分布式事务,允许将针对属于同一 Container 的对象的任何更新操作组合到单个 ACID 事务中。分布式一致性是通过基于多版本时间戳排序的无锁乐观并发控制机制提供的。DAOS 事务是可串行化的,可以在特定的基础上获取部分需要的数据集。
DAOS 版本控制机制允许创建持久的 Container 快照,该快照提供 Container 的实时分布一致性视图,该视图可用于构建生产者-消费者管道。
Epoch 和时间戳
每个 DAOS I/O 操作都有一个称为 epoch 的时间戳。epoch 是一个 64 位整数,它集成了逻辑和物理时钟(详见 HLC paper)。DAOS API 提供了辅助函数,用于将 epoch 转换为传统的 POSIX 时间(即 struct timespec,详见 clock_gettime(3))。
Container 快照
如下图所示,Container 的内容可以随时快照。
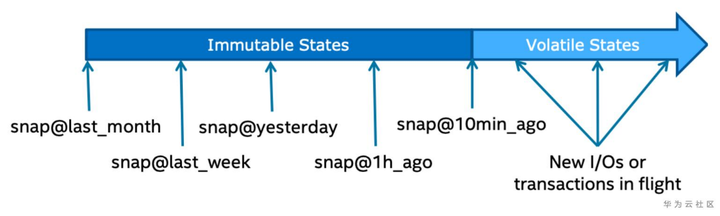
DAOS 快照非常轻量级,并且使用与创建快照的时间相关联的 epoch 进行标记。一旦创建成功,快照将一直保持可读性,直到它被显式销毁。在特定快照未被销毁前,Container 的内容可以回滚到该快照。
Container 快照功能支持本机生产者/消费者管道:
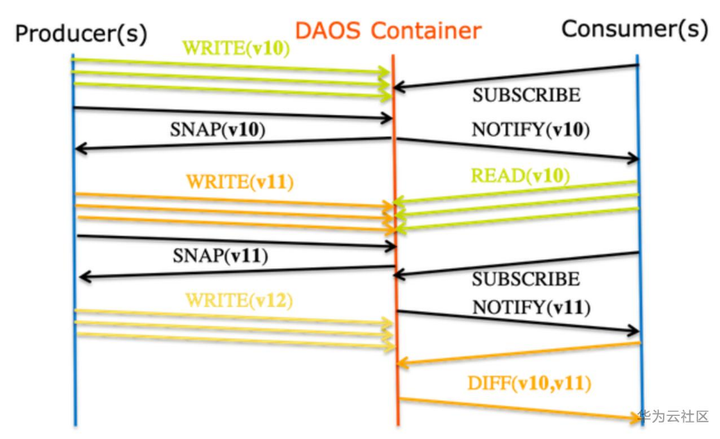
一旦成功写入数据集的一致版本,生产者 (Producer) 将生成一个快照。使用者 (Consumer) 的应用程序可以订阅 Container 快照事件,以便在生产者提交更新时可以处理新的更新。
快照的不变性保证了使用者可以看到一致的数据,即使生产者继续进行新的更新。生产者和消费者实际上都在 Container 的不同版本上操作,不需要任何串行化操作。一旦生产者生成了数据集的新版本,使用者就可以查询两个快照之间的差异,并且只处理增量修改。
分布式事务
与 POSIX 不同,DAOS API 不强制执行最坏情况下的并发控制机制来处理冲突的 I/O 操作。相反,各个 I/O 操作被标记为不同的 epoch,并按照 epoch 的顺序应用,而不管执行顺序如何。这个基准模型为不产生冲突的 I/O 工作负载的数据模型和应用程序提供了最大的可伸缩性和最高的性能。典型的例子是 MPI-IO 集合操作、POSIX 文件读/写操作和 HDF5 数据集读/写操作。
对于需要将冲突串行化的部分数据模型,DAOS 提供了基于多版本并发控制的分布式可串行化事务。当不同的用户进程要覆盖与 dkey/akey 关联的值时,通常需要该事务。例如 DAOS 上的 SQL 数据库,或者由非一致的客户端并发访问的一致的 POSIX 命名空间。
在同一操作的上下文中提交的所有 I/O 操作(包括读取)将使用相同的 epoch。DAOS 事务机制自动检测传统的读/写、写/读和写/写冲突,并中止其中一个冲突事务(事务在 -DER_RESTART 参数下提交失败)。然后,用户/应用程序必须重新启动失败的事务。
在目前的实现中,事务 API 具有以下限制,这些限制将在未来的 DAOS 版本中解决:
- 不支持 Array API
- 通过同一上下文环境执行的对象获取/列表和键值获取/列表操作所进行的事务对象更新和键值放入操作不可见。
本文分享自华为云社区《DAOS 分布式异步对象存储》,原文作者:debugzhang 。