摘要:Volcano主要是基于Kubernetes做的一个批处理系统,希望上层的HPC、中间层大数据的应用以及最下面一层AI能够在统一Kubernetes上面运行的更高效。
Volcano产生的背景
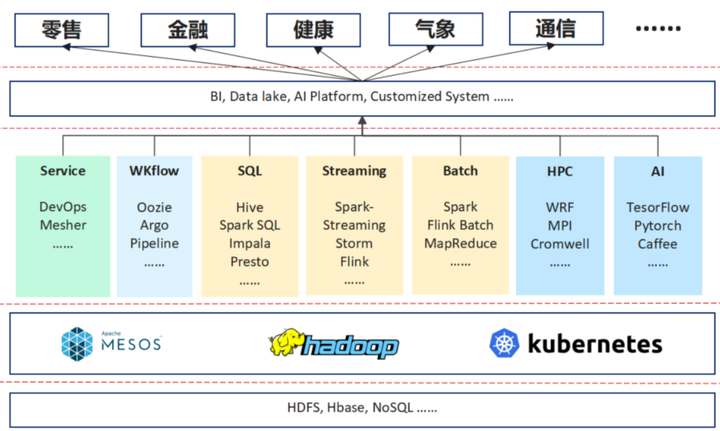
上图是我们做的一个分析,我们将其分为三层,最下面为资源管理层,中间为领域的框架,包括AI的体系、HPC、Batch, WKflow的管理以及像现在的一些微服务及流量治理等。再往上是行业以及一些行业的应用。
随着一些行业的应用变得复杂,它对所需求的解决方案也越来越高。举个例子在10多年以前,在金融行业提供解决方案时,它的架构是非常简单的,可能需要一个数据库,一个ERP的中间件,就可以解决银行大部分的业务。
而现在,每天要收集大量的数据,它需要spark去做数据分析,甚至需要一些数据湖的产品去建立数据仓库,然后去做分析,产生报表。同时它还会用 AI的一些系统,来简化业务流程等。
因此,现在的一些行业应用与10年前比,变得很复杂,它可能会应用到下面这些领域框架里面的一个或多个。其实对于行业应用,它的需求是在多个领域框架作为一个融合,领域框架的诉求是下面的资源管理层能够提供统一的资源管理。
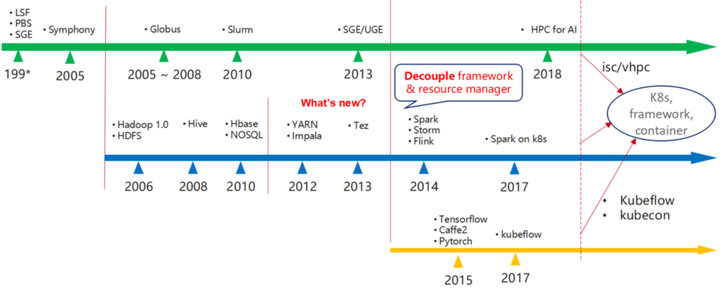
Kubernetes现在越来越多的承载了统一的资源管理的角色,它可以为 HPC这些行业领域框架提供服务,也可以作为大数据领域的资源管理层。Volcano主要是基于Kubernetes做的一个批处理系统,希望上层的HPC、中间层大数据的应用以及最下面一层AI能够在统一Kubernetes上面运行的更高效。
Volcano要解决什么样的问题?
挑战 1: 面向高性能负载的调度策略
e.g. fair-share, gang-scheduling
挑战 2: 支持多种作业生命周期管理
e.g. multiple pod template, error handling
挑战 3: 支持多种异构硬件
e.g. GPU, FPGA
挑战 4: 面向高性能负载的性能优化
e.g. scalability, throughput, network, runtime
挑战 5:支持资源管理及分时共享
e.g. Queue, Reclaim
Volcano架构体系
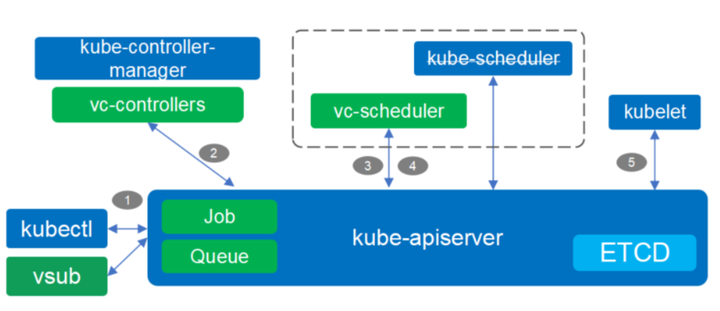
蓝色部分是 K8s本身的组件,绿色的部分是Volcano新加的一些组件。
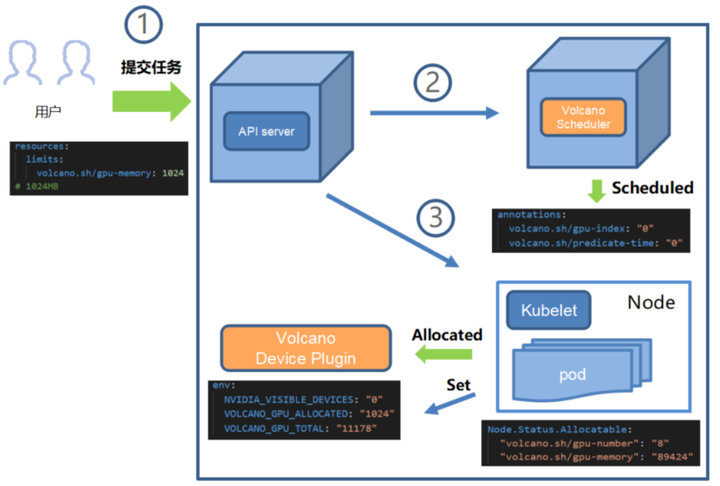
作业提交流程:
1、通过 Admission 后,kubectl 将在 kube-apiserver中创建 Job (Volcano CRD) 对像
2、JobController 根据 Job 的配置创建 相应的 Pods e.g. replicas
3、Pod及PodGroup创建 后,vc-scheduler 会到 kube-apiserver 获取Pod/PodGroup 以及 node 信息
4、获取信息后,vc-scheduler 将根据其配置的调度策略为每一个 Pod 选取合适节点
5、在为Pod分配节点后,kubelet 将从kube-apiserver中取得Pod的配置,启动相应的容器
需要强调的几点:
vc-scheduler 中的调度策略都以插件的形式存在, e.g. DRF, Priority, Gang
vc-controllers 包含了 QueueController, JobController,PodGroupController 以及 gc-controller
vc-scheduler 不仅可以调度批量计算的作业,也可以调度微服务作业;并且可以通过 multi-scheduler 功能与 kube-scheduler 共存
部分组件介绍
Controller
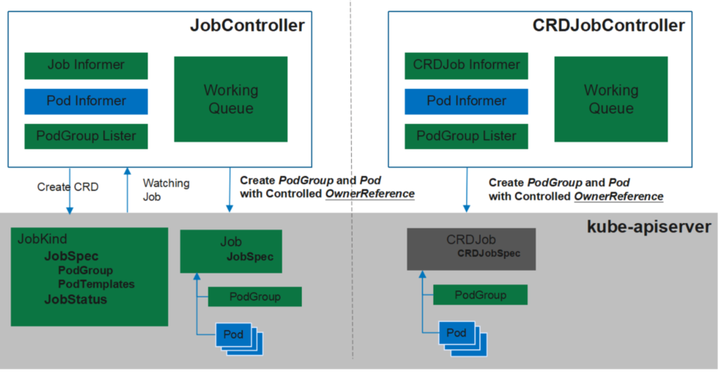
左边为Volcano Job Controller,不只调度使用的Volcano,Job的生命周期管理、作业管理都在这里面包含。我们提供了统一的作业管理,你只要使用Volcano,也不需要创建各种各样的操作,就可以直接运行作业。
右边为CRD Job Controller,通过下面的PodGroup去做集成。
scheduler架构体系
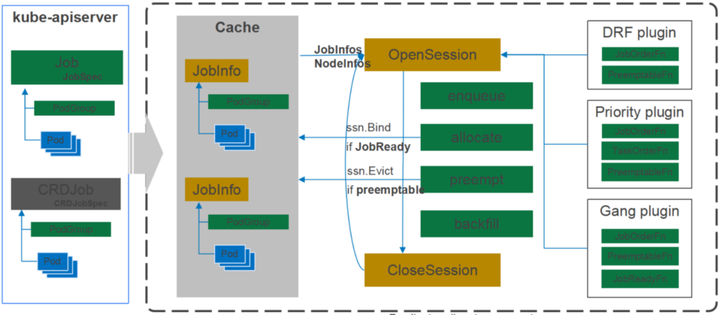
Scheduler支持动态配置和加载。左边为apiserver,右边为整个Scheduler,apiserver里有Job、Pod、Pod Group;Scheduler分为三部分,第一层为Cache,中间层为整个调度的过程,右边是以插件形式存在的调度算法。Cache会将apiserver里创建的Pod、Pod Group这些信息存储并加工为Jobinfors。中间层的OpenSession会从Cache里拉取Pod、Pod Group,同时将右边的算法插件一起获取,从而运行它的调度工作。
状态之间根据不同的操作进行转换,见下图。
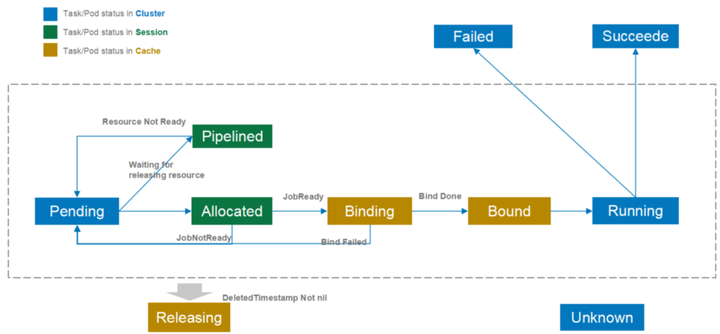
另外,我们在Pod和Pod的状态方面增加了很多状态,图中蓝色部分为K8s自带的状态;绿色部分是session级别的状态,一个调度周期,我们会创建一个session,它只在调度周期内发挥作用,一旦过了调度周期,这几个状态它是失效的;黄色部分的状态是放在Cache内的。我们加这些状态的目的是减少调度和API之间的一个交互,从而来优化调度性能。
Pod的这些状态为调度器提供了更多优化的可能。例如,当进行Pod驱逐时,驱逐在Binding和Bound状态的Pod要比较驱逐Running状态的Pod的代价要小 (思考:还有其它状态的Pod可以驱逐吗?);并且状态都是记录在Volcano调度内部,减少了与kube-apiserver的通信。但目前Volcano调度器仅使用了状态的部分功能,比如现在的preemption/reclaim仅会驱逐Running状态下的Pod;这主要是由于分布式系统中很难做到完全的状态同步,在驱逐Binding和Bound状态的Pod会有很多的状态竞争。
在功能上面能带来哪些好处?
- 支持多种类型作业混合部署
- 支持多队列用于多租户资源共享,资源规划;并分时复用资源
- 支持多种高级调度策略,有效提升整集群资源利用率
- 支持资源实时监控,用于高精度资源调度,例如 热点,网络带宽;容器引擎,网络性能优化, e.g. 免加载
分布式训练场景:
Gang-scheduler
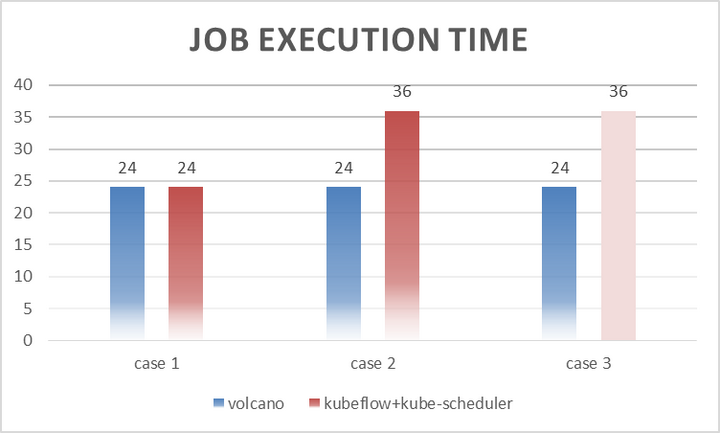
Case 1: 1 job with 2ps + 4workers
Case 2: 2 jobs with 2ps + 4workers
Case 3: 5 jobs with 2ps + 4workers
在Volcano和 kubeflow+kube-scheduler做对比,Case 1在资源充足的时候效果是差不多的;Case 2是在没有足够的资源的情况下同时运行两个作业,如果没有 gang-scheduling,其中的一个作业会出现忙等 ;Case 3当作业数涨到5后,很大概率出现死锁;一般只能完成2个作业。
IOAware
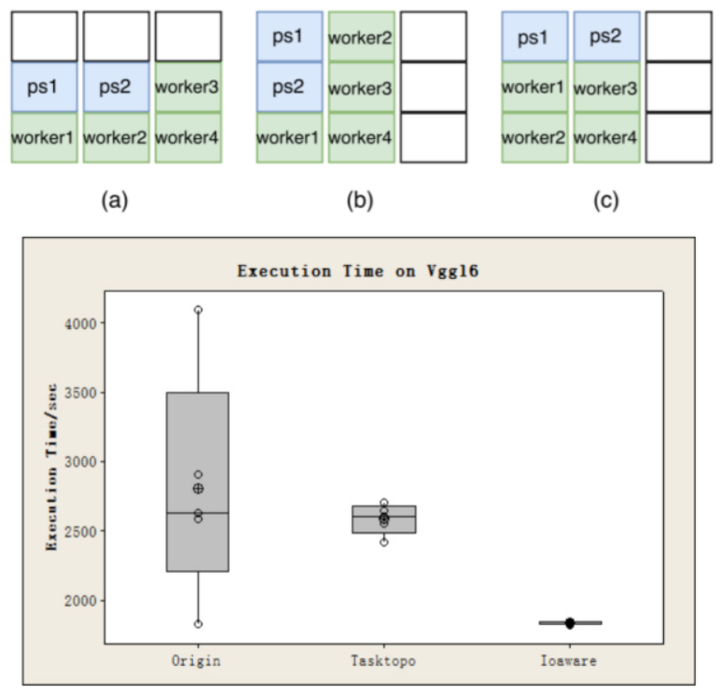
3个作业的执行时间总和; 每个作业带2ps + 4workers
默认调度器执行时间波动较大
执行时间的提高量依据数据在作业中的比例而定
减少 Pod Affinity/Anti-Affinity,提高调度器的整体性能
大数据场景
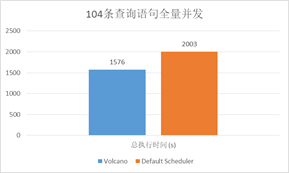
Spark-sql-perf (TP-DCS, master)
104 queries concurrently
(8cpu, 64G, 1600SSD) * 4nodes
Kubernetes 1.13
Driver: 1cpu,4G; Executor: (1cpu,4G)*5
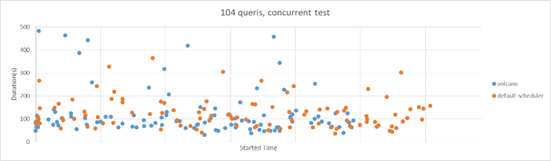
如果没有固定的driver节点,最多同时运行 26 条查询语句
由于Volcano提供了作业级的资源预留,总体性能提高了~30%
HPC场景
MPI on Volcano
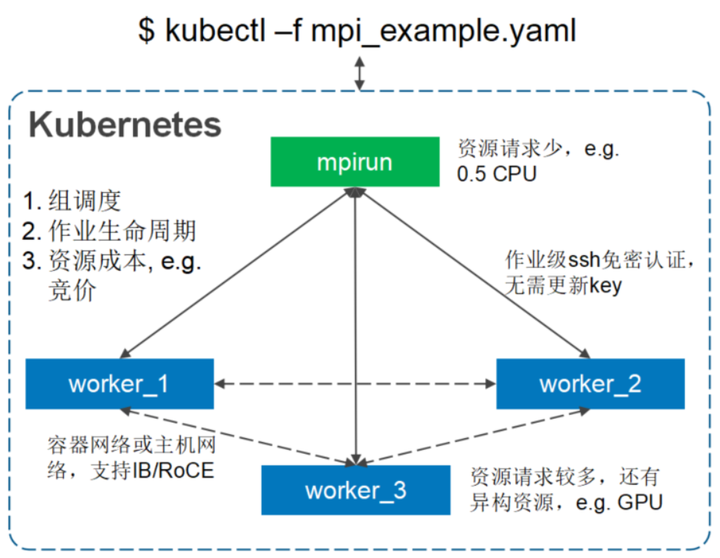
规划
GPU共享特性
1)算力优化:
- GPU硬件加速,TensorCore
- GPU共享
- 昇腾改造
2)调度算法优化:
Job/Task模型,提供AI类Job统一批量调度
多任务排队,支持多租户/部门共享集群
单Job内多任务集群中最优化亲和性调度、Gang Scheduling等
主流的PS-Worker、Ring AllReduce等分布式训练模型
3)流程优化
- 容器镜像
- CICD流程
- 日志监控
Volcano可以支持更大规模的一个集群调度,我们现在是1万个节点百万容器,调度的性能每秒达到2000个Pod。
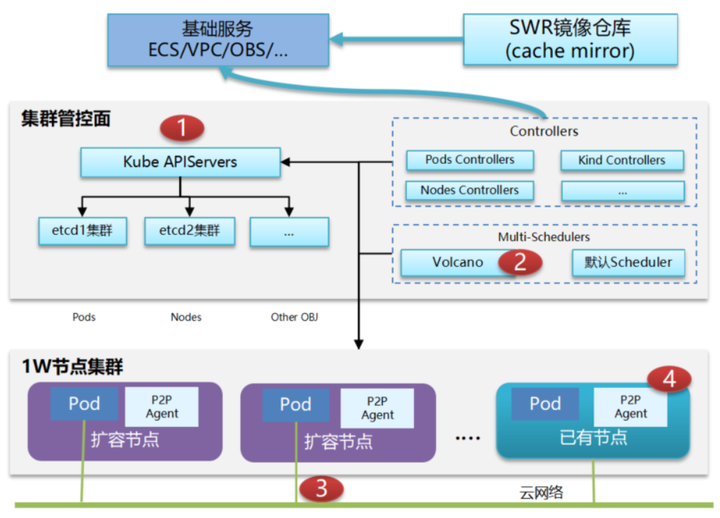
1)编排:
Etcd 分库分表,e.g. Event 放到单独库,wal/snapshot 单独挂盘
通过一致性哈希分散处理,实现 controller-manager 多活
Kube-apiserver 基于工作负载的弹性扩容
2)调度:
通过 EquivalenceCache,算法剪枝 等技术提升单调度器的吞吐性能
通过共享资源视图实现调度器多活,提升调度速率
3)网络:
通过trunkport提升单节点容器密度及单集群ENI容量
通过 Warm Pool 预申请网口,提升网口发放速度
基于eBPF/XDP 支持大规模、高度变化的云原生应用网络,e.g. Service, network policy
4)引擎:
containerd 并发 启动优化
支持shimv2,提升单节点容器密度
镜像下载加速 Lazy loading
Cromwell社区集成
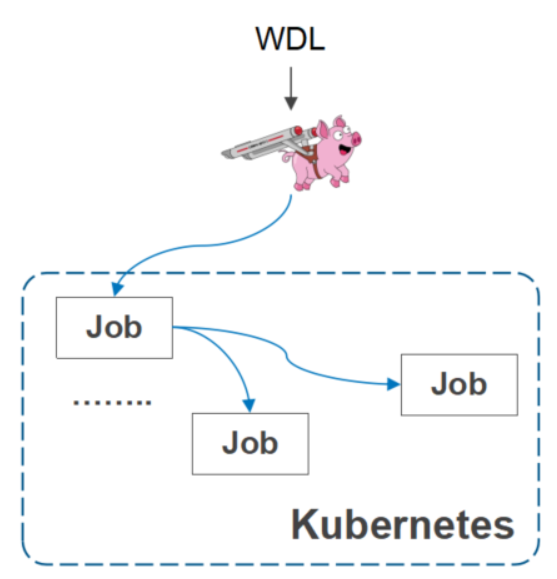
Cromwell是一个流程调度软件,它可以定义不同的作业,这个软件在基因测序以及基因计算领域里应用是比较广泛的。
Cromwell 社区原生支持Volcano
企业版已经上线 华为云 GCS
通过 cromwell 支持作业依赖
Volcano 提供面向作业、数据依赖的调度
Volcano CLI

KubeSim
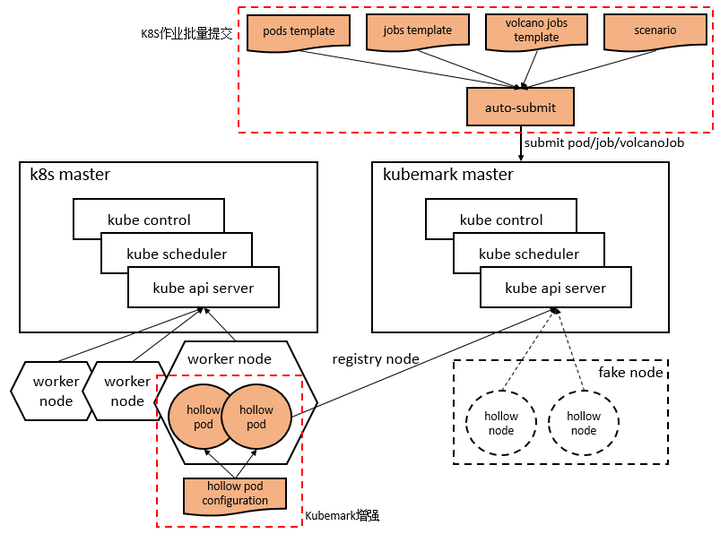
简介:
集群进行性能测试及调度的描述工具
不受资源限制,模拟大规模K8S集群
完整的K8S API调用,不会真正创建pod
已经支持产品侧大规模专项及调度专项的模拟工作
总体结构:
Worker cluster:承载kubemark虚拟节点,hollow pod
Master cluster:管理kubemark虚拟节点,hollow node
Hollow pod = hollow kubelet + hollow proxy
社区活跃度:
• 1.4k star,300+ fork,150+ 贡献者
• 3 Maintainer,7 Reviewer
• 30 家企业、科研机构
目前使用Volcano的部分企业
