Argo是一个开源原生容器工作流引擎用于在Kubernetes上开发和运行应用程序。Argo Workflow流程引擎,可以编排容器流程来执行业务逻辑,在20年4月8日进入CNCF孵化器组。
而KubeFlow的Pipeline子项目,由Google开源,其全面依赖Argo作为底层实现,并增强持久层来补充流程管理能力,同时通过Python-SDK来简化流程的编写。
一. Argo流程引擎
Argo的步骤间可以传递信息,即下一步(容器)可以获取上一步(容器)的结果。结果传递有2种:
1. 文件:上一步容器新生成的文件,会直接出现在下一步容器里面。
2. 信息:上一步的执行结果信息(如某文件内容),下一步也可以拿到。
下面我们就来解读一下,Argo怎么实现“信息”在容器间的传递的,以及它和其他的流程引擎实现传递的区别。
1.1文件怎么从上一个容器跑到下一个容器里的?
Argo流程,可以指定2个步骤之间,传递结果文件(Artifact)。即假设流程为:A->B,那么A容器跑完,B容器可以取得上一个容器的输出文件。
如下:A容器生成一个 /tmp/hello_world.txt 文件,Argo将这个文件,放到了B容器里面,并重命名为 /tmp/message文件。
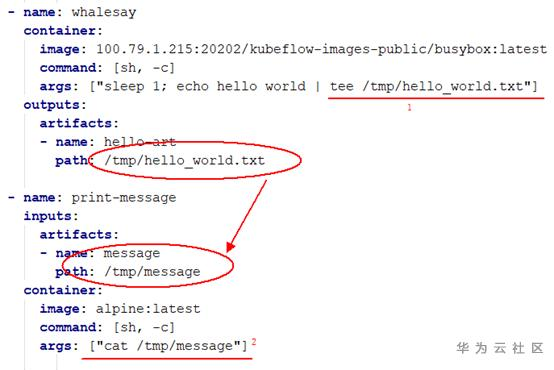
注意:流程上的每个步骤,都对应执行一个容器。 在A跑完后容器就退出了,然后才跑的B(这时候已经没有A容器在运行了)。
所以Argo怎么把一个文件从A容器“拷贝”到B容器里面的?
1.1.1容器间通过共享存储?(NO)
一般容器间共享文件,首先想到的都是:咱使用共享存储呀,大家都挂载同一个PVC不就行了。
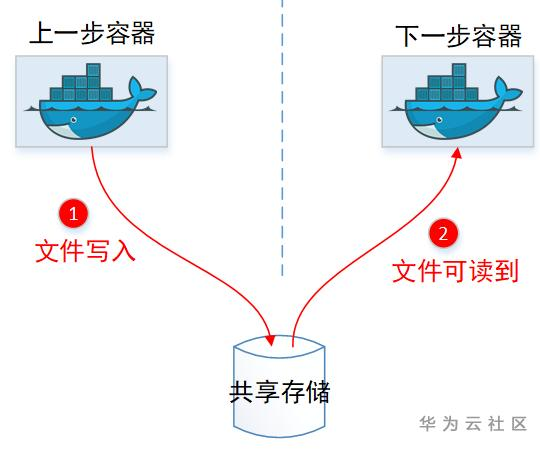
确实共享存储可以实现容器共享文件,但是这里Argo可以:
(1)任意指定文件传递。(2)传递后文件可以改名字。
这2个是共享Volume做不到的,毕竟容器挂载目录得提前设定好,然后文件名大家看到的也是一样的。所以显然文件传递,不是通过共享PVC挂载实现的。
(Ps:不过Argo也在考虑这种实现方式,毕竟共享目录不需要任何额外IO,透传效率更高。见:https://github.com/argoproj/argo/issues/1349)
1.1.2通过管理面中转?(YES)
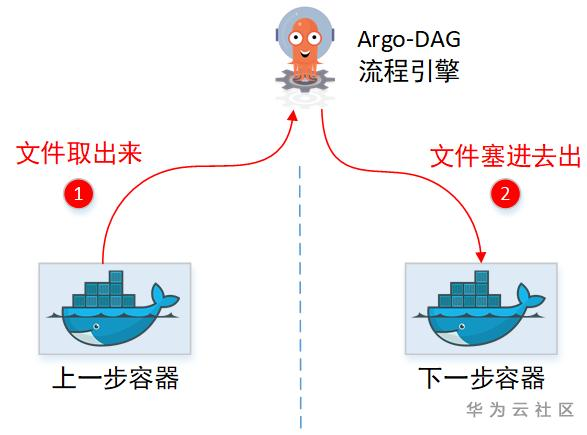
没有共享目录,那中转文件,只能是通过先取出来,再塞回去的方式喽。实际上Argo也确实这么做的,只是实现上还有些约束。
(1)“临时中转仓库”需要引入第三方软件(Minio)
(2)文件不能太大
(3)需要在用户容器侧,增加“代理”帮忙上传&下载文件。
1.1.3中转文件具体实现(docker cp)
现在我们打开Argo看看具体怎么实现的。因为你要取一个容器里面的文件,或者把一个文件放入一个容器,也不容易实现呢。
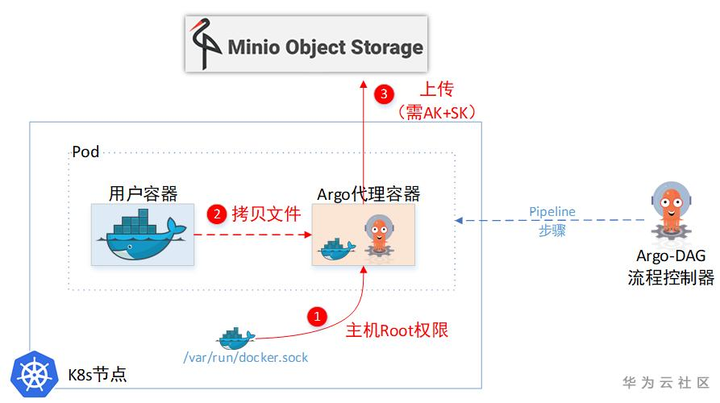
(1)小滑头Argo居给用户容器设置了一个SideCar容器,通过这个SideCar去读取用户的文件,然后上传到临时仓库。
(2) 一个Pod里面的两个Container,文件系统也是独立的,并不能直接取到另一个Container的文件。所以Sidecar容器为了取另一个容器里的文件,又把主机上面的docker.sock挂载进来了。这样就相当于拿到了主机Root权限,可以任意cp主机上任意容器里面的文件。
事实上,Sidecar里面取文件的实现是:
docker cp -a 023ce:/tmp/hello_world.txt - | gzip > /argo/outputs/artifacts/hello-art.tgz
感觉稍微有点暴力。
1.1.4中转实现的其他方式
实际上,通过sidecar容器提权到root权限,然后从用户的容器里面copy任意文件(即 docker cp命令),只是Argo默认的实现。毕竟它自己也发现这样做安全上有点说不过去。
所以呢,它也留了其他方式去copy用户容器里面的文件。比如:kubectl 也是可以cp容器里面的文件的嘛。其他方式可参见:
https://github.com/argoproj/argo/blob/master/docs/workflow-executors.md
1.2 下一步容器怎么拿到上一步容器的结果?
Argo流程,2个步骤之间,除了传递文件,还可以传递结果信息(Information)。如:A->B,那么A容器跑完,B容器可以取得上一个容器的一些Information(不是整个文件)。
一般流程引擎透传信息,都是中转:
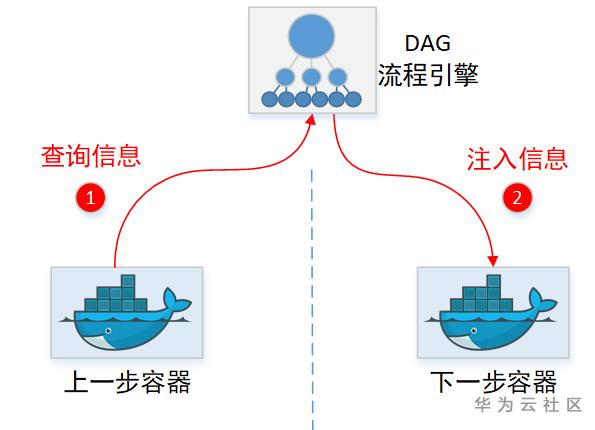
不过显然Argo自己没有存储Information的临时仓库,所以它得找个地方记录这些临时待中转的information(虽然Argo找了Minio这个对象存储用来暂存中转文件,但是显然这货只能存文件,没有存Metadata元数据功能)。这里Argo又找了Pod里面的Annotation字段,当做临时中转仓库。先把信息记这里,下一步容器想要,就来这里取。
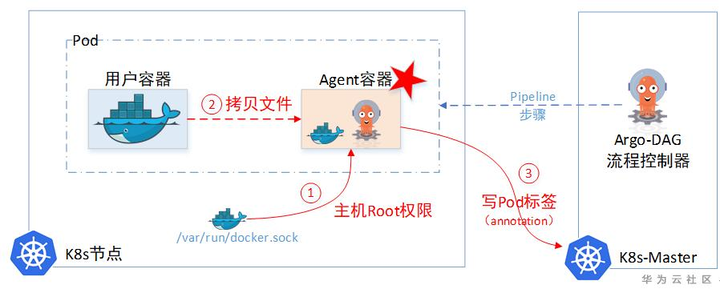
相信这里应该是有更好的实现方式的,这种把信息记录到Annotation的做法,约束比较大的(特别是ETCD的单个对象不能超过1M大小)。
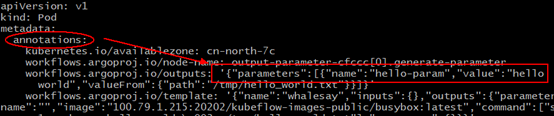
可以考虑使用单独的Configmap来中转也可以。
二. KubeFlow-Pipeline项目
KubeFlow-Pipeline项目(简称KFP),是Kubeflow社区开源的一个工作流项目,用于管理、部署端到端的机器学习工作流。KFP提供了一个流程管理方案,方便将机器学习中的应用代码按照流水线的方式编排部署,形成可重复的工作流。
2.1为什么要在Argo之上重新开发一套?
部署一套Argo很简单,启动一个K8s-Controller就行。可是部署一套Kubeflow-Pipeline系统就复杂多了,总共下来有8个组件。那是Argo什么地方不足,需要新开发一套KFP,并搞这么复杂呢?主要的原因还在于Argo是基于K8s云原生这套理念,即ETCD充当“数据库”来运行的,导致约束比较大。
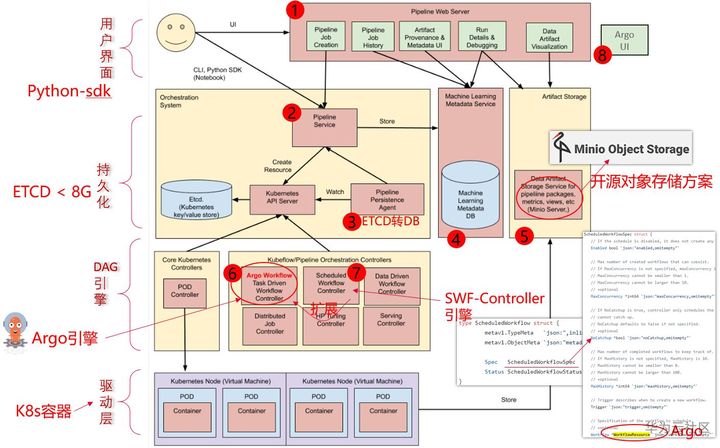
像:流程模板,历史执行记录,这些大量的信息很明显需要一个持久化层(数据库)来记录的,单纯依赖ETCD会有单条记录不能超过1M,总记录大小不能超过8G的约束。
所以一个完整的流程引擎,包含一个数据库也都是很常规的。因此KFP在这一层做了较大的增强。
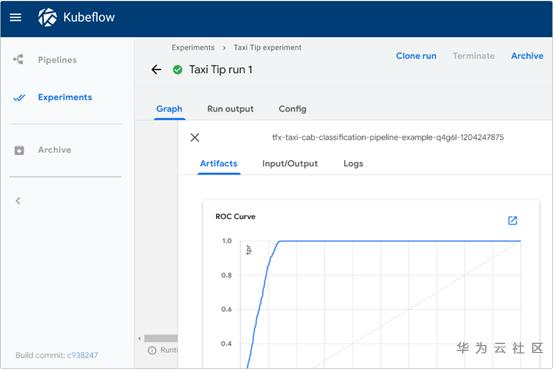
另外,在ML领域的用户界面层,KFP也做了较多的用户体验改进。包括可以查看每一步的训练输出结果,直接通过UI进行可视化的图形展示。
https://www.kubeflow.org/docs/pipelines/sdk/output-viewer/
2.2 Kubeflow-Pipeline后续演进点
见:https://github.com/kubeflow/pipelines/issues/3550
Dag引擎组件的水平扩展(HPA)是其重要的一个特性,也是要成为一个成熟引擎所必要的能力。
当前KFP在稳定性以及组件的水平扩展上都还有待改进,因此商业使用还需要一段时间,这将是KFP未来的一个重要目标。
同时,使用权限过于高的Sidecar容器作为其实现步骤之间元数据传递的途径,也会是KFP生产级使用的一道门槛。或许在权限控制方面,KFP需要思考一下其他规避途径,至少需要稍微增强一下。
概括一下:(1)水平扩展(HPA),(2)生产级可靠性,(3)安全增强。
三. 流程引擎核心&分层
3.1 DAG核心
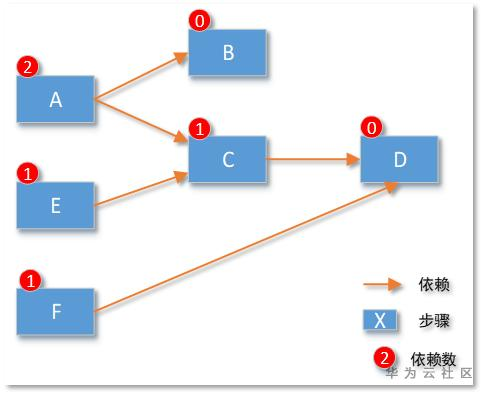
一个DAG流程引擎,核心代码也就7行大概能实现了:

例如下图示例:遍历发现步骤D没有依赖其他步骤,那么本次可以执行D步骤。
所以一般程序员一周时间总能开发一个“还能用”的流程引擎。但是完整的流程引擎却并不轻松
3.2 世界上为什么有这么多的流程引擎
DAG基础核心非常简单,同时,各个领域想要做的事情却迥然不同。即使一个简单的步骤,大数据步骤说:“这一步要执行的SQL语句是xxx”,而K8s任务步骤却说:“这一步执行需要的Docker镜像是yyy”。
所以,各种各样的流程引擎就自然的出现了。
举几个例子:
AWS:Cloudformation编排,Batch服务,SageMaker-ML Pipeline,Data Pipeline
Azure:Pipeline服务,ML Pipeline,Data Factory
Aliyun:函数Pipeline服务,ROS资源编排,Batch服务,PAI-Studio
大数据领域:Oozie,AirFlow
软件部署:Puppet,Chef,Ansible
基因分析:DNAnexus,NextFlow,Cromwell
每个领域总能找出一两个流程引擎,来控制谁先干活谁后干活。
总结一下:
(1)DAG引擎核心很小
(2)各领域步骤的描述方式不一样
这就是为什么各个领域,总会有一个自己的流程引擎,而不像K8s能一统容器平台一样,出现一个能一统江湖的流程引擎。
3.3 DAG引擎分层架构
成熟的流程引擎,应该有如下4层架构:
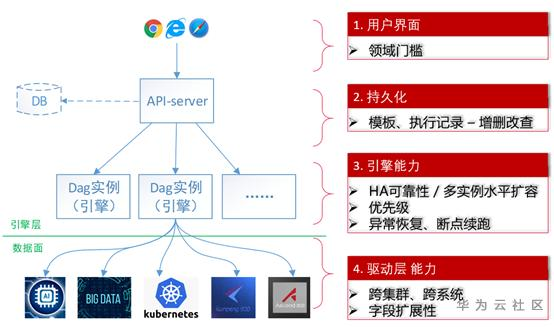
第一层:用户交互层。如:模板语法规则,Console界面等
第二层:API持久化层。如:模板记录,历史执行记录等
第三层:引擎实例层。如:能否水平扩容,流程是否有优先级等
第四层:驱动层。如:一个步骤能干什么活。跑一个容器还是跑一个Spark任务。
基本比较成熟的引擎都符合这种架构,例如AirFlow流程引擎,华为云的应用编排(AOS)引擎,数据湖工厂(DLF)引擎等都是如此。
目前Argo以及Kubeflow-Pipeline在引擎核心组件的水平扩展上,也即第三层引擎能力层稍有不足。同时其驱动层,目前也只能对接K8s(即只能跑容器任务)。在选型的时候需要考虑进去。
