好记性不如烂笔头,打算以博客连载的方式把最近机器学习的一些学习笔记记下来,机器学习涉及的知识点很多,时间一长很容易遗忘,写在博客上也方便自己随时查阅及复习。学习笔记偏重实用工程,尽量不涉及复杂的数学推导。

机器学习分类
-- 监督学习:训练数据中带有标记(分类、回归);
-- 无监督学习:训练数据中无标记(聚类、异常检测、密度分析);
-- 半监督学习:训练数据中带有少量标记(分类、回归);
-- 强化学习:通过状态空间的大量试错学习达成最佳决策(决策);
-- 深度学习:利用多层神经网络进行监督、无监督或是强化学习的方法(分类、回归、聚类)。
数据划分
-- 留出法:直接将数据集D划分为两个互斥的集合,一个集合作为训练集S,另一个作为测试机T。
-- 交叉验证法:将数据集D划分为k个大小相同的互斥子集,每次用k-1个子集作为训练集,余下的作为测试集,可进行k次训练和验证,最后取测试结果的均值。
-- 自助法:有m个样本的数据集D,每次随机从D中挑选一个样本放入D‘,再把此样本放回D中,重复执行m次后,得到训练数据集D’。约有1/3的数据没在训练数据中出现过,用于包外估计。(数据集较小时使用效果较好)
模型评估
泛化能力:指模型对未知数据的预测能力。
-- 泛化误差:偏差、方差、噪声之和。
-- 过拟合:模型在训练及上表现很好,但在未知数据上不能很好的预测。
-- 欠拟合:模型在训练集和测试集上都不能很好的预测。
性能度量指标:
-- 均方误差:m个样本的方差的平均数,均方误差小的模型性能好,主要用于回归。
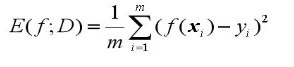
-- 错误率:分类错误的样本占样本总数的比例。
-- 精度:分类正确的样本占样本总数的比例。
-- 查准率:真正例样本数(TP)和预测结果是正例的样本数(TP(真正例数)+FP(假正例数))的比值。
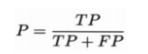
-- 查全率(召回率):真正例样本数(TP)和真实正例样本数(TP(真正例数)+FN(假反例数))的比值。
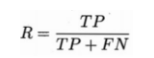
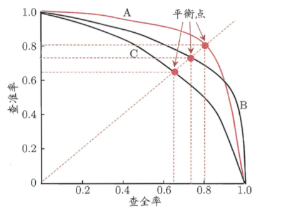
-- P-R图:以查全率做x轴,查准率做y轴的平面图。判断模型优劣的两种方式:1、平衡点(查全率=查准率时的取值)更大的性能更好;2、曲线没有交叉的情况下,被“包住”的曲线模型性能弱于外侧的模型,如下图,A模型优于C模型。
-- 混淆矩阵:用在分类问题中的NxN矩阵,N为分类的个数。如下图猫、狗、兔子的三分类系统,每一列代表预测值,每一行代表实际值,对角线两边的都是预测错误的,从混淆矩阵中可以很直观地发现问题在哪里。

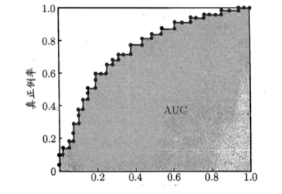
-- ROC和AUC:ROC(受试者工作特征曲线)以假正例率为x轴,真正例率为y轴,AUC是ROC曲线下的面积,面积越大分类效果越好(真正例率越高,假正例率越低越好)。
偏差(Bias):反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,高偏差,即为欠拟合。
方差(Variance):反映的是同样大小的训练集的变动导致的学习性能的波动,即刻画了数据扰动所造成的影响,即模型的稳定性。高方差,即为过拟合。
模型复杂度和偏差、方差的关系如下图,随着模型复杂度增大,偏差减小,方差变大,预测错误率在模型复杂度到达一定程度后,反而会增大,偏差和方差从某种程度上说是一对矛盾体,很难做到偏差和方差都很低,只能从偏差、方差和模型复杂度中找到一个平衡点。

作者:华为云专家周捷
HDC.Cloud 华为开发者大会2020 即将于2020年2月11日-12日在深圳举办,是一线开发者学习实践鲲鹏通用计算、昇腾AI计算、数据库、区块链、云原生、5G等ICT开放能力的最佳舞台。
