headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
response = request.get(url,headers=headers)
关于爬虫的合法性
几乎每一个网站都有一个名为 robots.txt 的文档,当然也有部分网站没有设定 robots.txt。对于没有设定 robots.txt 的网站可以通过网络爬虫获取没有口令加密的数据,也就是该网站所有页面数据都可以爬取。如果网站有 robots.txt 文档,就要判断是否有禁止访客获取的数据。
以淘宝网为例,在浏览器中访问 https://www.taobao.com/robots.txt,如图 3 所示。

淘宝网允许部分爬虫访问它的部分路径,而对于没有得到允许的用户,则全部禁止爬取,代码如下:
User-Agent:*
Disallow:/
爬虫的基本原理
网页请求的过程分为两个环节:
- Request (请求):每一个展示在用户面前的网页都必须经过这一步,也就是向服务器发送访问请求。
- Response(响应):服务器在接收到用户的请求后,会验证请求的有效性,然后向用户(客户端)发送响应的内容,客户端接收服务器响应的内容,将内容展示出来,就是我们所熟悉的网页请求,如图 8 所示。

图 8 Response相应
网页请求的方式也分为两种:
- GET:最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快。
- POST:相比 GET 方式,多了以表单形式上传参数的功能,因此除查询信息外,还可以修改信息。
所以,在写爬虫前要先确定向谁发送请求,用什么方式发送。
使用 GET 方式抓取数据
复制任意一条首页首条新闻的标题,在源码页面按【Ctrl+F】组合键调出搜索框,将标题粘贴在搜索框中,然后按【Enter】键。
如图 8 所示,标题可以在源码中搜索到,请求对象是www.cntour.cn,请求方式是GET(所有在源码中的数据请求方式都是GET)
import requests #导入requests包 url = 'http://www.cntour.cn/' strhtml = requests.get(url) #Get方式获取网页数据 print(strhtml.text)
使用 POST 方式抓取数据
首先输入有道翻译的网址:http://fanyi.youdao.com/,进入有道翻译页面。
按快捷键 F12,进入开发者模式,单击 Network,此时内容为空,如图 11 所示:
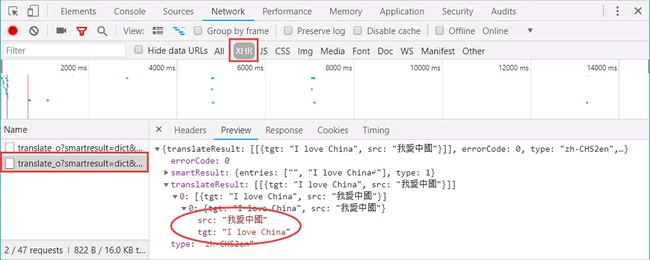
首先,将 Headers 中的 URL 复制出来,并赋值给 url,代码如下:
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
POST 的请求获取数据的方式不同于 GET,POST 请求数据必须构建请求头才可以。
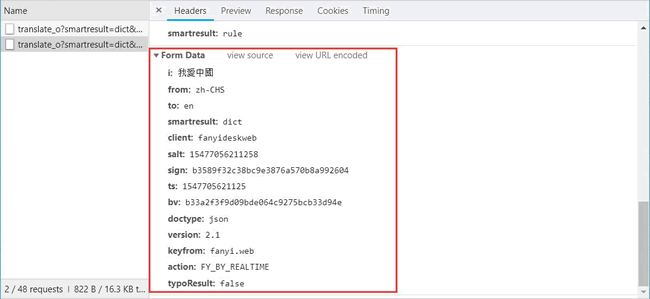
Form Data 中的请求参数如图 15 所示:
import requests #导入requests包
import json
def get_translate_date(word=None):
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
From_data={'i':word,'from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt':'15477056211258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'1547705621125','bv':'b33a2f3f9d09bde064c9275bcb33d94e','doctype':'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
#请求表单数据
response = requests.post(url,data=From_data)
#将Json格式字符串转字典
content = json.loads(response.text)
print(content)
#打印翻译后的数据
#print(content['translateResult'][0][0]['tgt'])
if __name__=='__main__':
get_translate_date('我爱中国')
使用 Beautiful Soup 解析网页
通过 requests 库已经可以抓到网页源码,接下来要从源码中找到并提取数据。Beautiful Soup 是 python 的一个库,其最主要的功能是从网页中抓取数据。Beautiful Soup 目前已经被移植到 bs4 库中,也就是说在导入 Beautiful Soup 时需要先安装 bs4 库。
安装好 bs4 库以后,还需安装 lxml 库。如果我们不安装 lxml 库,就会使用 Python 默认的解析器。尽管 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器又支持一些第三方解析器,但是 lxml 库具有功能更加强大、速度更快的特点,因此笔者推荐安装 lxml 库。
import requests #导入requests包
from bs4 import BeautifulSoup
url='http://www.cntour.cn/'
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml')
data = soup.select('#main>div>div.mtop.firstMod.clearfix>div.centerBox>ul.newsList>li>a')
print(data)
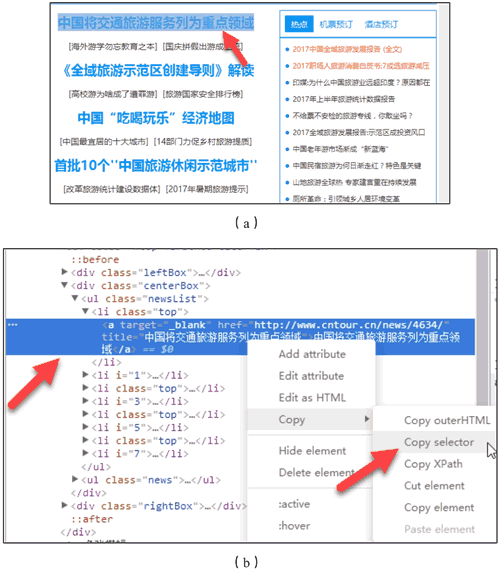
这是在代码中快速确定的方法,非常实用
首先明确要提取的数据是标题和链接,标题在<a>标签中,提取标签的正文用 get_text() 方法。链接在<a>标签的 href 属性中,提取标签中的 href 属性用 get() 方法,在括号中指定要提取的属性数据,即 get('href')。
文章的链接中有一个数字 ID。下面用正则表达式提取这个 ID。需要使用的正则符号(正则可从网上搜索)
服务器第一种识别爬虫的方式就是通过检查连接的 useragent 来识别到底是浏览器访问,还是代码访问的。如果是代码访问的话,访问量增大时,服务器会直接封掉来访 IP。
那么应对这种初级的反爬机制,我们应该采取何种举措?
还是以前面创建好的爬虫为例。在进行访问时,我们在开发者环境下不仅可以找到 URL、Form Data,还可以在 Request headers 中构造浏览器的请求头,封装自己。服务器识别浏览器访问的方法就是判断 keyword 是否为 Request headers 下的 User-Agent,
因此,我们只需要构造这个请求头的参数。创建请求头部信息即可,代码如下:
